理解Postgres性能
目录[-]
理解Postgres性能
对于很多应用程序开发人员来说数据库就是一个黑盒子。在数据进进出出之间,开发人员希望它的时间跨度短点。不用成为DBA,这里有一些可以为大多数应用程序开发人员所理解的数据来帮助他们理解他们的数据库表现是否足够好。这篇文章将会提供一些小提示,帮助你判断是否你的数据库的性能降低了程序的性能,以及如果那样的话你该怎么做。
理解缓存和缓存命中率
对于大多数应用来说典型的判断规则是哪部分数据是经常访问的。同其他一样都服从80/20法则,就是20%的数据占据着80%的读,并且有时更高。Postgres它会跟踪你数据的模式并且还会把经常访问的数据保存到缓存中。一般来说你希望数据库能够有99%的缓存命中率。你可以查看缓存命中率:
SELECT
sum(heap_blks_read) as heap_read,
sum(heap_blks_hit) as heap_hit,
sum(heap_blks_hit) / (sum(heap_blks_hit) + sum(heap_blks_read)) as ratio
FROM
pg_statio_user_tables;
我们可以这个在 dataclip上显示 Heroku Postgres的缓存命中率为99.99%。如果你发现比例低于99%,那么你可能想要考虑增加数据库的缓存可用性了,你可以在Heroku Postgres上使用快速提升数据库性能 或者在像EC2之类的上使用dump/restore组成一个更大的实例来提升性能。
理解索引用途
其它主要提升性能的方式就是索引了。一些框架会为你的主键添加索引,但是如果你在其它字段搜索或者大量的联接时,你可能需要手动添加那样的索引了。
索引是最有价值的对于大表更是如此。同时从缓存中访问数据比从磁盘更快,即使数据在内存中可能会变慢因为Postgres必须要解析成百上千的行来确定这是不是它们曾经已处理过的条件。为了得到在你数据库中表的索引使用时间百分比并且按照表从大到小顺序显示,你可以执行这样的语句:
SELECT
relname,
100 * idx_scan / (seq_scan + idx_scan) percent_of_times_index_used,
n_live_tup rows_in_table
FROM
pg_stat_user_tables
WHERE
seq_scan + idx_scan > 0
ORDER BY
n_live_tup DESC;
然而这里没有最完美的答案,如果在某些地方访问超过10,000行数据时命中率在99%左右时,你可以考虑添加索引了。当检查在哪里添加索引你应该参照你所运行的查询类型了。一般来说,你应该在使用其它id来查询或者你经常要过滤的值如created_at字段的地方添加索引。
专业提示:如果你在产品数据库中使用CREATE INDEX CONCURRENTLY来添加索引的话,请在后台建立索引以及不要持有表锁。同时创建索引的局限是它一般会多花2-3倍时间来创建并且不会在事务中执行。即使对于任何大型产品网站,这些取舍对您的最终用户是值得的。
Heroku Dashboard示例
使用最近访问Heroku dashboard作为现实世界的示例,我们可以运行这样的查询语句以及运行结果:
# SELECT relname, 100 * idx_scan / (seq_scan + idx_scan) percent_of_times_index_used, n_live_tup rows_in_table FROM pg_stat_user_tables ORDER BY n_live_tup DESC;
relname | percent_of_times_index_used | rows_in_table
---------------------+-----------------------------+---------------
events | 0 | 669917
app_infos_user_info | 0 | 198218
app_infos | 50 | 175640
user_info | 3 | 46718
rollouts | 0 | 34078
favorites | 0 | 3059
schema_migrations | 0 | 2
authorizations | 0 | 0
delayed_jobs | 23 | 0
从这里我们可以看到events表有接近700,000行被使用了但是却没有索引。从这里你可以研究我的应用以及看出一些所使用的通用查询语句,一个例子就是把博客推送到你那里。你可以执行EXPLAIN ANALYZE来看你的execution plan,对于特定的查询语句的性能来说它可以给你更好的主意。
EXPLAIN ANALYZE SELECT * FROM events WHERE app_info_id = 7559; QUERY PLAN
-------------------------------------------------------------------
Seq Scan on events (cost=0.00..63749.03 rows=38 width=688) (actual time=2.538..660.785 rows=89 loops=1)
Filter: (app_info_id = 7559)
Total runtime: 660.885 ms
在给定的顺序遍历所有数据这方面使用索引我们可以得到优化。你可以同时添加索引来阻止锁定表,并且查看性能怎么样:
CREATE INDEX CONCURRENTLY idx_events_app_info_id ON events(app_info_id);
EXPLAIN ANALYZE SELECT * FROM events WHERE app_info_id = 7559; ----------------------------------------------------------------------
Index Scan using idx_events_app_info_id on events (cost=0.00..23.40 rows=38 width=688) (actual time=0.021..0.115 rows=89 loops=1)
Index Cond: (app_info_id = 7559)
Total runtime: 0.200 ms
同时在这单一的查询语句中我们可以看到明显的改进,我们可以在 New Relic上检验这个结果,并且可以看到使用这个索引以及其它一些索引减少了我们在数据库上所花的时间。
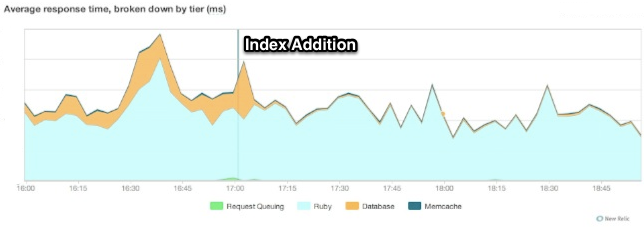
索引缓存命中率
最后两者结合,如果你对有多少索引在你的缓存中感兴趣的话,你可以运行:
SELECT
sum(idx_blks_read) as idx_read,
sum(idx_blks_hit) as idx_hit,
(sum(idx_blks_hit) - sum(idx_blks_read)) / sum(idx_blks_hit) as ratio
FROM
pg_statio_user_indexes;
一般来说,你应该要求这个达到99%,和你一般缓存命中率一样。
理解Postgres性能的更多相关文章
- 深入理解Postgres中的cache
众所周知,缓存是提高数据库性能的一个重要手段.本文着重讲一讲PostgreSQL中的缓存相关的东西.当然万变不离其宗,原理都是共同的,理解了这些,你也很容易把它运用到其它数据库中. What is a ...
- 【转载】深入理解JVM性能调优
性能问题无非就这么几种:CPU.内存.磁盘IO.网络.那我们来逐一介绍以下相关的现象和一些可能出现的问题. 一.CPU过高. 查看CPU最简单的我们使用任务管理器查看,如下图所示,windows下使用 ...
- 深入理解JVM—性能监控工具
(转自:http://yhjhappy234.blog.163.com/blog/static/31632832201222691738865/) 我们知道,在JVM编译期和加载器,甚至运行期已经做了 ...
- 修改一行代码提升 Postgres 性能 100 倍
http://www.datadoghq.com/2013/08/100x-faster-postgres-performance-by-changing-1-line/ SELECT c.key, ...
- 性能调优:理解Set Statistics IO输出
性能调优是DBA的重要工作之一.很多人会带着各种性能上的问题来问我们.我们需要通过SQL Server知识来处理这些问题.经常被问到的一个问题是:早上这个存储过程运行时间还是可以的,但到了晚上就很慢很 ...
- 第17 章 : 深入理解 etcd:etcd 性能优化实践
深入理解 etcd:etcd 性能优化实践 本文将主要分享以下五方面的内容: etcd 前节课程回顾复习: 理解 etcd 性能: etcd 性能优化 -server 端: etcd 性能优化 -cl ...
- 2016 年开发者应该掌握的十个 Postgres 技巧
[编者按]作为一款开源的对象-关系数据库,Postgres 一直得到许多开发者喜爱.近日,Postgres 正式发布了9.5版本,该版本进行了大量的修复和功能改进.而本文将分享10个 Postgres ...
- Redis性能问题排查解决手册(七)
阅读目录: 性能相关的数据指标 内存使用率used_memory 命令处理总数total_commands_processed 延迟时间 内存碎片率 回收key 总结 性能相关的数据指标 通过Red ...
- MapReduce剖析笔记之一:从WordCount理解MapReduce的几个阶段
WordCount是一个入门的MapReduce程序(从src\examples\org\apache\hadoop\examples粘贴过来的): package org.apache.hadoop ...
随机推荐
- 【248】◀▶IEW-Unit13
Unit 13 Technology 流程图讲解 1.model1对应图片讲解 2.Model1范文分析 Model 1 The ice cream making process has five k ...
- Redux API之creatStore
createStore(reducer, [initialState]) 创建一个 Redux store 来以存放应用中所有的 state.应用中应有且仅有一个 store. 参数 reducer ...
- ajax方法data参数用法的总结
源文件分析: data的传递格式有两种:一是url字符串格式:一种是Json格式,格式分别如上 区别是:当传递的参数中包含 特殊字符如:&时,服务器解析这个参数时就会出错,而必须用encode ...
- Spring入门第十二课
Bean的配置方法 通过工厂方法(静态工厂方法&实例工厂方法),FactoryBean 通过调用静态工厂方法创建Bean 调用静态工厂方法创建Bean是将对象创建的过程封装到静态方法中,当客户 ...
- 基于Laravel框架的一个简单易学的微信商城(新手必学)
俗话说,麻雀虽小可五脏俱全呀! 今天分享的这个基于Laravel的小项目大概功能有这些: 1.实现会员登录.注册功能.数据双向验证功能.2.实现手机短信验证.邮件激活账号.邮件通知.3.ajax提交数 ...
- CABasicAnimation动画及其keypath值和作用
//tarnsform放大缩小动画 CABasicAnimation *animation = [CABasicAnimation animationWithKeyPath:@"transf ...
- SqlHelper 增删改查
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.D ...
- Unity 5着色器系统代码介绍(下)
http://forum.china.unity3d.com/thread-25738-1-10.html 上一篇对着色器系统的工作原理做了介绍,现在我们将继续深入,将目光聚焦在标准着色器的光照函数. ...
- 洛谷P1005 矩阵取数游戏
P1005 矩阵取数游戏 题目描述 帅帅经常跟同学玩一个矩阵取数游戏:对于一个给定的n*m的矩阵,矩阵中的每个元素aij均为非负整数.游戏规则如下: 1.每次取数时须从每行各取走一个元素,共n个.m次 ...
- react-native-video的使用
/** * Sample React Native App * https://github.com/facebook/react-native * * @format * @flow */ impo ...