spark作业
假定用户有某个周末网民网购停留时间的日志文本,基于某些业务要求,要求开发
Spark应用程序实现如下功能:
1、实时统计连续网购时间超过半个小时的女性网民信息。
2、周末两天的日志文件第一列为姓名,第二列为性别,第三列为本次停留时间,单
位为分钟,分隔符为“,”。
数据:
log1.txt:周六网民停留日志
LiuYang,female,20 YuanJing,male,10 GuoYijun,male,5 CaiXuyu,female,50 Liyuan,male,20 FangBo,female,50 LiuYang,female,20 YuanJing,male,10 GuoYijun,male,50 CaiXuyu,female,50 FangBo,female,60
log2.txt:周日网民停留日志
LiuYang,female,20 YuanJing,male,10 CaiXuyu,female,50 FangBo,female,50 GuoYijun,male,5 CaiXuyu,female,50 Liyuan,male,20 CaiXuyu,female,50 FangBo,female,50 LiuYang,female,20 YuanJing,male,10 FangBo,female,50 GuoYijun,male,50 CaiXuyu,female,50 FangBo,female,60
统计日志文件中本周末网购停留总时间超过2个小时的女性网民信息。
1、接收Kafka中数据,生成相应DStream。
2、筛选女性网民上网时间数据信息。
3、汇总在一个时间窗口内每个女性上网时间。
4、筛选连续上网时间超过阈值的用户,并获取结果。
1.启动zk
./zkServer.sh start
2.启动Kafka
./kafka-server-start.sh /root/apps/kafka/config/server.properties
3.创建topic
[root@mini3 kafka]# bin/kafka-console-producer.sh --broker-list mini1: --topic sparkhomework-test
4.生产数据
代码
package org.apache.spark import org.apache.spark.streaming.Seconds
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.kafka.KafkaUtils /**
* Created by Administrator on 2019/6/13.
*/
object SparkHomeWork {
val updateFunction = (iter: Iterator[(String, Seq[Int], Option[Int])]) => {
iter.flatMap { case (x, y, z) => Some(y.sum + z.getOrElse(0)).map(v => (x, v)) }
} def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local[2]").setAppName("SparkHomeWork")
val ssc = new StreamingContext(conf, Seconds(5))
//将回滚点写到hdfs
ssc.checkpoint("hdfs://mini1:9000/kafkatest") val Array(zkQuorum, groupId, topics, numThreads) = Array[String]("mini1:2181,mini2:2181,mini3:2181", "g1", "sparkhomework-test", "2")
val topicMap = topics.split(",").map((_, numThreads.toInt)).toMap val lines = KafkaUtils.createStream(ssc, zkQuorum, groupId, topicMap).map(_._2) //筛选女性网民上网时间数据信息
val data = lines.flatMap(_.split(" ")).filter(_.contains("female"))
//汇总每个女性上网时间
val femaleData: DStream[(String, Int)] = data.map { line =>
val t = line.split(',')
(t(0), t(2).toInt)
}.reduceByKey(_ + _)
//筛选出时间大于两个小时的女性网民信息,并输出
val results = femaleData.filter(line => line._2 > 120).updateStateByKey(updateFunction, new HashPartitioner(ssc.sparkContext.defaultParallelism), true)
results.print()
ssc.start()
ssc.awaitTermination()
} }
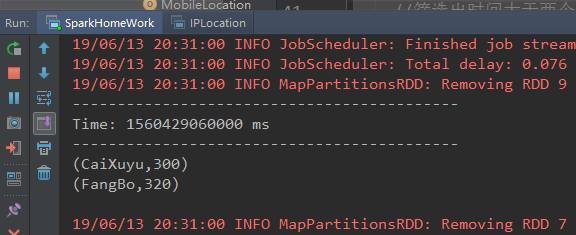
打印结果:
spark作业的更多相关文章
- Spark学习(四) -- Spark作业提交
标签(空格分隔): Spark 作业提交 先回顾一下WordCount的过程: sc.textFile("README.rd").flatMap(line => line.s ...
- 构建Spark作业
首先,要清楚,一个Java或Scala或python实现的Spark作业. 1.用sbt构建Spark作业 2.用Maven构建Spark作业 3.用non-maven-aware工具构建Spark作 ...
- Spark记录-Spark作业调试
在本地IDE里直接运行spark程序操作远程集群 一般运行spark作业的方式有两种: 本机调试,通过设置master为local模式运行spark作业,这种方式一般用于调试,不用连接远程集群. 集群 ...
- spark作业提交参数设置(转)
来源:https://www.cnblogs.com/arachis/p/spark_parameters.html 摘要 1.num-executors 2.executor-memory 3.ex ...
- 数据倾斜是多么痛?spark作业调优秘籍
目录视图 摘要视图 订阅 [观点]物联网与大数据将助推工业应用的崛起,你认同么? CSDN日报20170703——<从高考到程序员——我一直在寻找答案> [直播]探究L ...
- 【转】数据倾斜是多么痛?spark作业/面试/调优必备秘籍
原博文出自于: http://sanwen.net/a/gqkotbo.html 感谢! 来源:数盟 调优概述 有的时候,我们可能会遇到大数据计算中一个最棘手的问题——数据倾斜,此时Spark作业的性 ...
- spark作业运行过程之--DAGScheduler
DAGScheduler--stage划分和创建以及stage的提交 本篇,我会从一次spark作业的运行为切入点,将spark运行过程中涉及到的各个步骤,包括DAG图的划分,任务集的创建,资源分配, ...
- Spark作业执行流程源码解析
目录 相关概念 概述 源码解析 作业提交 划分&提交调度阶段 提交任务 执行任务 结果处理 Reference 本文梳理一下Spark作业执行的流程. Spark作业和任务调度系统是其核心,通 ...
- Spark作业提交至Yarn上执行的 一个异常
(1)控制台Yarn(Cluster模式)打印的异常日志: client token: N/A diagnostics: Application application_1584359 ...
- Spark作业执行
Spark中一个action触发一个job的执行,在job提交过程中主要涉及Driver和Executor两个节点. Driver主要解决 1. RDD 依赖性分析,生成DAG. 2. 根据RDD D ...
随机推荐
- 洛谷 P2983 [USACO10FEB]购买巧克力Chocolate Buying
购买巧克力Chocolate Buying 乍一看以为是背包,然后交了一个感觉没错的背包上去. #include <iostream> #include <cstdio> #i ...
- 一键部署基于GitLab的自托管Git项目仓库
https://market.azure.cn/Vhd/Show?vhdId=9851&version=11921 产品详情 产品介绍GitLab https://about.gitlab.c ...
- wpf ListBox删除选择项(支持多项)
搞了个ListBox删除选择项,开始老是不能把选择项删除干净,剩下几个.后来调试一下原来是ListBox在删除一个选择项之后立即更新,选择项也有变化.结果我想了个这样的方法来删除呵呵. Departm ...
- vue 中根据地址名称获取实际经纬度方法
<div id="container" class="map" style="margin-top:30px; width: 1200px;he ...
- python基础一 day15 作业
3.处理文件,用户指定要查找的文件和内容,将文件中包含要查找内容的每一行都输出到屏幕def check_file(filename,aim): with open(filename,encoding= ...
- Logistic回归,梯度上升算法理论详解和实现
经过对Logistic回归理论的学习,推导出取对数后的似然函数为 现在我们的目的是求一个向量,使得最大.其中 对这个似然函数求偏导后得到 根据梯度上升算法有 进一步得到 我们可以初始化向量为0,或者随 ...
- Bootstrap 徽章(Badges)
本章将讲解Bootstrap徽章(Badges),徽章与标签相似,主要的区别是徽章的圆角比较圆滑. 徽章(Badges)主要用于突出显示新的或未读的项,如果使用徽章,只需要把<span clas ...
- Java中什么是匿名对象,空参构造方法输出创建了几个匿名对象,属性声明成static
package com.swift; //使用无参构造方法自动生成对象,序号不断自增 public class Person { private static int count; //如果在定义类时 ...
- 解决cocos2dx 打包lua环境搭建问题( ImportError: No module named Cheetah.Template)
将c++ 封装成lua调用时,显示一下错误: PYTHON_BIN not defined, use current python. generating userconf.ini... Genera ...
- vue 前端判断输入框不能输入0 空格。特殊符号。
oninput="value=value.replace(/[^\d.]/g,'').replace(/\.{2,}/g,'.').replace('.','$#$').replace(/\ ...