spark作业
假定用户有某个周末网民网购停留时间的日志文本,基于某些业务要求,要求开发
Spark应用程序实现如下功能:
1、实时统计连续网购时间超过半个小时的女性网民信息。
2、周末两天的日志文件第一列为姓名,第二列为性别,第三列为本次停留时间,单
位为分钟,分隔符为“,”。
数据:
log1.txt:周六网民停留日志
LiuYang,female,20 YuanJing,male,10 GuoYijun,male,5 CaiXuyu,female,50 Liyuan,male,20 FangBo,female,50 LiuYang,female,20 YuanJing,male,10 GuoYijun,male,50 CaiXuyu,female,50 FangBo,female,60
log2.txt:周日网民停留日志
LiuYang,female,20 YuanJing,male,10 CaiXuyu,female,50 FangBo,female,50 GuoYijun,male,5 CaiXuyu,female,50 Liyuan,male,20 CaiXuyu,female,50 FangBo,female,50 LiuYang,female,20 YuanJing,male,10 FangBo,female,50 GuoYijun,male,50 CaiXuyu,female,50 FangBo,female,60
统计日志文件中本周末网购停留总时间超过2个小时的女性网民信息。
1、接收Kafka中数据,生成相应DStream。
2、筛选女性网民上网时间数据信息。
3、汇总在一个时间窗口内每个女性上网时间。
4、筛选连续上网时间超过阈值的用户,并获取结果。
1.启动zk
./zkServer.sh start
2.启动Kafka
./kafka-server-start.sh /root/apps/kafka/config/server.properties
3.创建topic
[root@mini3 kafka]# bin/kafka-console-producer.sh --broker-list mini1: --topic sparkhomework-test
4.生产数据
代码
package org.apache.spark import org.apache.spark.streaming.Seconds
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.kafka.KafkaUtils /**
* Created by Administrator on 2019/6/13.
*/
object SparkHomeWork {
val updateFunction = (iter: Iterator[(String, Seq[Int], Option[Int])]) => {
iter.flatMap { case (x, y, z) => Some(y.sum + z.getOrElse(0)).map(v => (x, v)) }
} def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local[2]").setAppName("SparkHomeWork")
val ssc = new StreamingContext(conf, Seconds(5))
//将回滚点写到hdfs
ssc.checkpoint("hdfs://mini1:9000/kafkatest") val Array(zkQuorum, groupId, topics, numThreads) = Array[String]("mini1:2181,mini2:2181,mini3:2181", "g1", "sparkhomework-test", "2")
val topicMap = topics.split(",").map((_, numThreads.toInt)).toMap val lines = KafkaUtils.createStream(ssc, zkQuorum, groupId, topicMap).map(_._2) //筛选女性网民上网时间数据信息
val data = lines.flatMap(_.split(" ")).filter(_.contains("female"))
//汇总每个女性上网时间
val femaleData: DStream[(String, Int)] = data.map { line =>
val t = line.split(',')
(t(0), t(2).toInt)
}.reduceByKey(_ + _)
//筛选出时间大于两个小时的女性网民信息,并输出
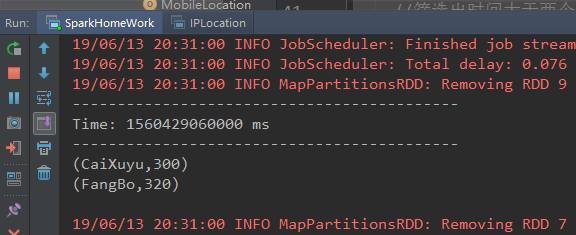
val results = femaleData.filter(line => line._2 > 120).updateStateByKey(updateFunction, new HashPartitioner(ssc.sparkContext.defaultParallelism), true)
results.print()
ssc.start()
ssc.awaitTermination()
} }
打印结果:
spark作业的更多相关文章
- Spark学习(四) -- Spark作业提交
标签(空格分隔): Spark 作业提交 先回顾一下WordCount的过程: sc.textFile("README.rd").flatMap(line => line.s ...
- 构建Spark作业
首先,要清楚,一个Java或Scala或python实现的Spark作业. 1.用sbt构建Spark作业 2.用Maven构建Spark作业 3.用non-maven-aware工具构建Spark作 ...
- Spark记录-Spark作业调试
在本地IDE里直接运行spark程序操作远程集群 一般运行spark作业的方式有两种: 本机调试,通过设置master为local模式运行spark作业,这种方式一般用于调试,不用连接远程集群. 集群 ...
- spark作业提交参数设置(转)
来源:https://www.cnblogs.com/arachis/p/spark_parameters.html 摘要 1.num-executors 2.executor-memory 3.ex ...
- 数据倾斜是多么痛?spark作业调优秘籍
目录视图 摘要视图 订阅 [观点]物联网与大数据将助推工业应用的崛起,你认同么? CSDN日报20170703——<从高考到程序员——我一直在寻找答案> [直播]探究L ...
- 【转】数据倾斜是多么痛?spark作业/面试/调优必备秘籍
原博文出自于: http://sanwen.net/a/gqkotbo.html 感谢! 来源:数盟 调优概述 有的时候,我们可能会遇到大数据计算中一个最棘手的问题——数据倾斜,此时Spark作业的性 ...
- spark作业运行过程之--DAGScheduler
DAGScheduler--stage划分和创建以及stage的提交 本篇,我会从一次spark作业的运行为切入点,将spark运行过程中涉及到的各个步骤,包括DAG图的划分,任务集的创建,资源分配, ...
- Spark作业执行流程源码解析
目录 相关概念 概述 源码解析 作业提交 划分&提交调度阶段 提交任务 执行任务 结果处理 Reference 本文梳理一下Spark作业执行的流程. Spark作业和任务调度系统是其核心,通 ...
- Spark作业提交至Yarn上执行的 一个异常
(1)控制台Yarn(Cluster模式)打印的异常日志: client token: N/A diagnostics: Application application_1584359 ...
- Spark作业执行
Spark中一个action触发一个job的执行,在job提交过程中主要涉及Driver和Executor两个节点. Driver主要解决 1. RDD 依赖性分析,生成DAG. 2. 根据RDD D ...
随机推荐
- http://www.ibm.com/developerworks/cn/web/wa-lo-firefox-ext/index.html
<html> <head> <style> textarea{ width:800p ...
- html5 03
HTML03 一. 表单标签 <form></form> 常用属性 Action 跳转到什么页面 Method 以什么模式提交 Get Url有长度限制 IE6.0 url ...
- tomcat服务器,从前端到后台到跳转
前端页面: <!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <tit ...
- ionic 2 起航 控件的使用 客户列表场景(四)
接下来,我们的客户列表要怎么刷新数据呢? 我们不会安卓开发,不会ios开发,没关系,我们还有ionic 2.ionic 2的控件 Ion-refresher 轻松帮我们搞掂. <!--下拉刷新- ...
- 一点对原生HTTP请求的理解与总结
全手打原创,转载请标明出处:https://www.cnblogs.com/dreamsqin/p/10946165.html,多谢,=.=~ 术语 HTTP:超文本传输协议,规定Web浏览器如何从W ...
- 会写网页 就会写手机APP #2-- 范例修正 , Hybrid Mobile Apps for ASP.NET Developers (Apache Cordova)
原文出处:会写网页 就会写手机APP #2-- 范例修正 , Hybrid Mobile Apps for ASP.NET Developers (Apache Cordova) 这是我的文章备份 ...
- HDU 5095 Linearization of the kernel functions in SVM (坑水)
比较坑的水题,首项前面的符号,-1,+1,只有数字项的时候要输出0. 感受一下这些数据 160 0 0 0 0 0 0 0 0 -10 0 0 0 0 0 0 0 0 10 0 0 0 0 0 0 0 ...
- event loop、进程和线程、任务队列
本文原链接:https://cloud.tencent.com/developer/article/1106531 https://cloud.tencent.com/developer/articl ...
- 得到本地机器的IP地址
实现效果: 知识运用: DNS类的GetHostByName //获取指定DNS主机名的DNS信息 public static IPHostEntry GetHostByName (string ...
- Python 生成器和协程
Python3 迭代器与生成器 迭代器 迭代是Python最强大的功能之一,是访问集合元素的一种方式. 迭代器是一个可以记住遍历的位置的对象. 迭代器对象从集合的第一个元素开始访问,直到所有的元素被访 ...