ES搜索排序,文档相关度评分介绍——Vector Space Model
Vector Space Model
The vector space model provides a way of comparing a multiterm query against a document. The output is a single score that represents how well the document matches the query. In order to do this, the model represents both the document and the query as vectors.
A vector is really just a one-dimensional array containing numbers, for example:
[1,2,5,22,3,8]
In the vector space model, each number in the vector is the weight of a term, as calculated with term frequency/inverse document frequency.
While TF/IDF is the default way of calculating term weights for the vector space model, it is not the only way. Other models like Okapi-BM25 exist and are available in Elasticsearch. TF/IDF is the default because it is a simple, efficient algorithm that produces high-quality search results and has stood the test of time.
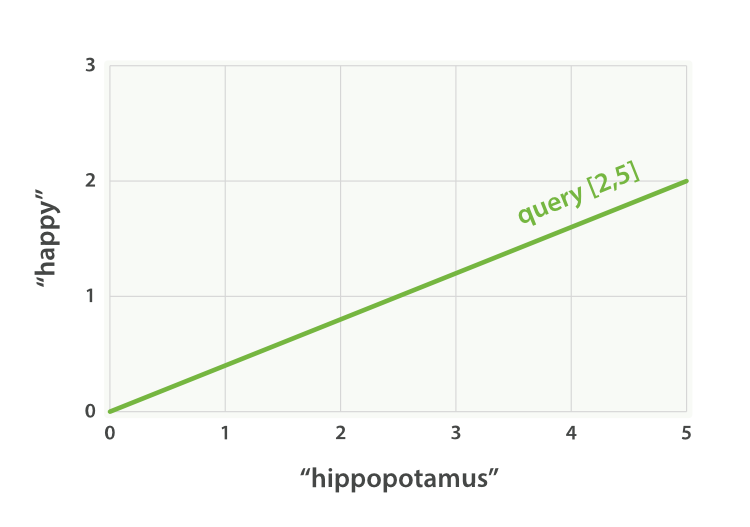
Imagine that we have a query for “happy hippopotamus.” A common word like happy will have a low weight, while an uncommon term like hippopotamus will have a high weight. Let’s assume that happyhas a weight of 2 and hippopotamus has a weight of 5. We can plot this simple two-dimensional vector—[2,5]—as a line on a graph starting at point (0,0) and ending at point (2,5), as shown inFigure 27, “A two-dimensional query vector for “happy hippopotamus” represented”.
Figure 27. A two-dimensional query vector for “happy hippopotamus” represented
Now, imagine we have three documents:
- I am happy in summer.
- After Christmas I’m a hippopotamus.
- The happy hippopotamus helped Harry.
We can create a similar vector for each document, consisting of the weight of each query term—happy and hippopotamus—that appears in the document, and plot these vectors on the same graph, as shown in Figure 28, “Query and document vectors for “happy hippopotamus””:
- Document 1:
(happy,____________)—[2,0] - Document 2:
( ___ ,hippopotamus)—[0,5] - Document 3:
(happy,hippopotamus)—[2,5]
Figure 28. Query and document vectors for “happy hippopotamus”
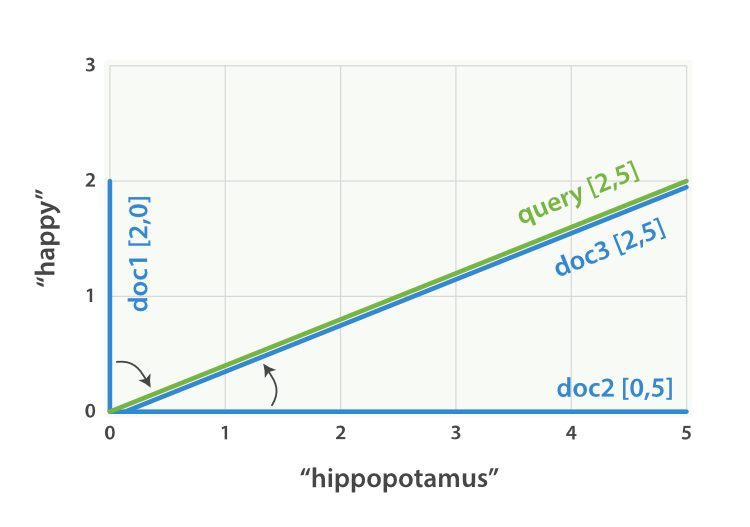
The nice thing about vectors is that they can be compared. By measuring the angle between the query vector and the document vector, it is possible to assign a relevance score to each document. The angle between document 1 and the query is large, so it is of low relevance. Document 2 is closer to the query, meaning that it is reasonably relevant, and document 3 is a perfect match.
In practice, only two-dimensional vectors (queries with two terms) can be plotted easily on a graph. Fortunately, linear algebra—the branch of mathematics that deals with vectors—provides tools to compare the angle between multidimensional vectors, which means that we can apply the same principles explained above to queries that consist of many terms.
You can read more about how to compare two vectors by using cosine similarity.
Now that we have talked about the theoretical basis of scoring, we can move on to see how scoring is implemented in Lucene.
ES搜索排序,文档相关度评分介绍——Vector Space Model的更多相关文章
- ES搜索排序,文档相关度评分介绍——TF-IDF—term frequency, inverse document frequency, and field-length norm—are calculated and stored at index time.
Theory Behind Relevance Scoring Lucene (and thus Elasticsearch) uses the Boolean model to find match ...
- ES搜索排序,文档相关度评分介绍——Field-length norm
Field-length norm How long is the field? The shorter the field, the higher the weight. If a term app ...
- ES 文档与索引介绍
在之前的文章中,介绍了 ES 整体的架构和内容,这篇主要针对 ES 最小的存储单位 - 文档以及由文档组成的索引进行详细介绍. 会涉及到如下的内容: 文档的 CURD 操作. Dynamic Mapp ...
- ES-PHP向ES批量添加文档报No alive nodes found in your cluster
ES-PHP向ES批量添加文档报No alive nodes found in your cluster 2016年12月14日 12:31:40 阅读数:2668 参考文章phpcurl 请求Chu ...
- atitit.vod search doc.doc 点播系统搜索功能设计文档
atitit.vod search doc.doc 点播系统搜索功能设计文档 按键的enter事件1 Left rig事件1 Up down事件2 key_events.key_search = fu ...
- 认识DOM 文档对象模型DOM(Document Object Model)定义访问和处理HTML文档的标准方法。元素、属性和文本的树结构(节点树)。
认识DOM 文档对象模型DOM(Document Object Model)定义访问和处理HTML文档的标准方法.DOM 将HTML文档呈现为带有元素.属性和文本的树结构(节点树). 先来看看下面代码 ...
- es之对文档进行更新操作
5.7.1:更新整个文档 ES中并不存在所谓的更新操作,而是用新文档替换旧文档: 在内部,Elasticsearch已经标记旧文档为删除并添加了一个完整的新文档并建立索引.旧版本文档不会立即消失 ,但 ...
- es搜索排序不正确
沿用该文章里的数据https://www.cnblogs.com/MRLL/p/12691763.html 查询时发现,一模一样的name,但是相关度不一样 GET /z_test/doc/_sear ...
- MongoDB中的映射,限制记录和记录拼排序 文档的插入查询更新删除操作
映射 在 MongoDB 中,映射(Projection)指的是只选择文档中的必要数据,而非全部数据.如果文档有 5 个字段,而你只需要显示 3 个,则只需选择 3 个字段即可. find() 方法 ...
随机推荐
- 使用 mybatis + flying + 双向相关建模 的电商后端
代码地址如下:http://www.demodashi.com/demo/12468.html mybatis.flying 众所周知,mybatis 虽然易于上手,但放到互联网环境下使用时,不可避免 ...
- Linux ps 命令查看进程启动及运行时间
引言 同事问我怎样看一个进程的启动时间和运行时间,我第一反应当然是说用 ps 命令啦.ps aux或ps -ef不就可以看时间吗? ps aux选项及输出说明 我们来重新复习下ps aux的选项,这是 ...
- 【Android应用开发详解】实现第三方授权登录、分享以及获取用户资料
由于公司项目的需要,要实现在项目中使用第三方授权登录以及分享文字和图片等这样的效果,几经波折,查阅了一番资料,做了一个Demo.实现起来的效果还是不错的,不敢独享,决定写一个总结的教程,供大家互相 ...
- D类功放基础简介
DAC和D类PA的开关时序是先开dac再开D类pa,先关D类pa再关dac
- 使用sphinx生成美观的文档
先上效果图 详情 首先,须要知道什么是restructuredtext.能够理解为类似于markdown的一个东西. 然后 安装.pip install sphinx 进入存放文档的文件夹,在命令行, ...
- HBase 系统架构及数据结构
一.基本概念 2.1 Row Key (行键) 2.2 Column Family(列族) 2.3 Column Qualifier (列限定符) 2.4 Column ...
- spring源码解析之IOC容器(一)
学习优秀框架的源码,是提升个人技术水平必不可少的一个环节.如果只是停留在知道怎么用,但是不懂其中的来龙去脉,在技术的道路上注定走不长远.最近,学习了一段时间的spring源码,现在整理出来,以便日后温 ...
- HDFS源码分析之LightWeightGSet
LightWeightGSet是名字节点NameNode在内存中存储全部数据块信息的类BlocksMap需要的一个重要数据结构,它是一个占用较低内存的集合的实现,它使用一个数组array存储元素,使用 ...
- Spark源码分析之三:Stage划分
继上篇<Spark源码分析之Job的调度模型与运行反馈>之后,我们继续来看第二阶段--Stage划分. Stage划分的大体流程如下图所示: 前面提到,对于JobSubmitted事件,我 ...
- nginx - KeepAlive详细解释
最近工作中遇到一个问题,想把它记录下来,场景是这样的: 从上图可以看出,用户通过Client访问的是LVS的VIP, VIP后端挂载的RealServer是Nginx服务器. Client可以是浏览器 ...