Linux--struct file结构体【转】
本文转载自:https://www.cnblogs.com/hanxiaoyu/p/5677677.html
struct file(file结构体):
struct file结构体定义在include/linux/fs.h中定义。文件结构体代表一个打开的文件,系统中的每个打开的文件在内核空间都有一个关联的 struct file。
它由内核在打开文件时创建,并传递给在文件上进行操作的任何函数。在文件的所有实例都关闭后,内核释放这个数据结构。在内核创建和驱动源码中,
struct file的指针通常被命名为file或filp。其有两个非常重要的字段:文件描述符和缓冲区。
文件描述符fd:
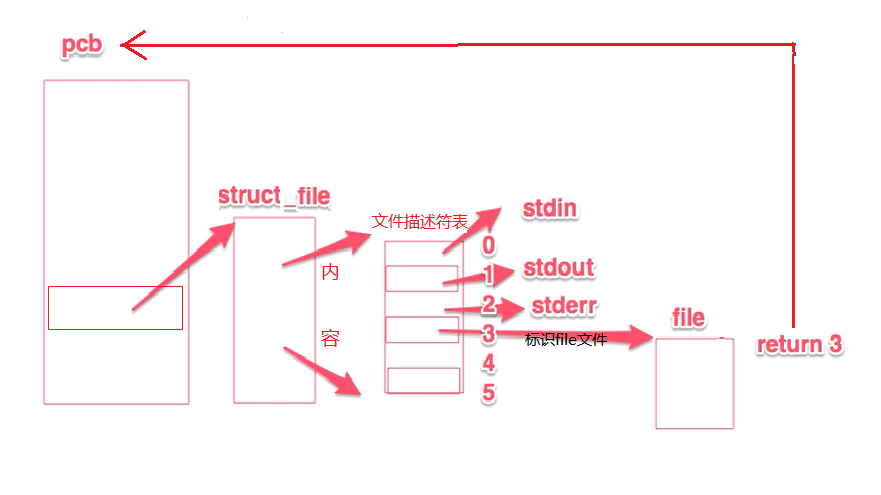
fd只是一个小整数,在open时产生。起到一个索引的作用,进程通过PCB中的文件描述符表找到该fd所指向的文件指针filp。
文件描述符的操作(如: open)返回的是一个文件描述符,内核会在每个进程空间中维护一个文件描述符表, 所有打开的文件都将通过此表中的文件描述符来引用;
而流(如: fopen)返回的是一个FILE结构指针, FILE结构是包含有文件描述符的,FILE结构函数可以看作是对fd直接操作的系统调用的封装, 它的优点是带有I/O
缓存。
每个进程在PCB(Process Control Block)即进程控制块中都保存着一份文件描述符表,文件描述符就是这个表的索引,文件描述表中每个表项都有一个指
向已打开文件的指针,现在我们明确一下:已打开的文件在内核中用file结构体表示,文件描述符表中的指针指向file结构体。
缓冲区:
A)缓冲区机制
根据应用程序对文件的访问方式,即是否存在缓冲区,对文件的访问可以分为带缓冲区的操作和非缓冲区的文件操作:
a) 带缓冲区文件操作:高级标准文件I/O操作,将会在用户空间中自动为正在使用的文件开辟内存缓冲区。
b) 非缓冲区文件操作:低级文件I/O操作,读写文件时,不会开辟对文件操作的缓冲区,直接通过系统调用对磁盘进行操作(读、写等),当然用于可以在自己
的程序中为每个文件设定缓冲区。
两种文件操作的解释和比较:
1、非缓冲的文件操作访问方式,每次对文件进行一次读写操作时,都需要使用读写系统调用来处理此操作,即需要执行一次系统调用,执行一次系统调用将涉
及到CPU状态的切换,即从用户空间切换到内核空间,实现进程上下文的切换,这将损耗一定的CPU时间,频繁的磁盘访问对程序的执行效率造成很大的影响。
2、ANSI标准C库函数 是建立在底层的系统调用之上,即C函数库文件访问函数的实现中使用了低级文件I/O系统调用,ANSI标准C库中的文件处理函数为了减
少使用系统调用的次数,提高效率,采用缓冲机制,这样,可以在磁盘文件进行操作时,可以一次从文件中读出大量的数据到缓冲区中,以后对这部分的访问就不需
要再使用系统调用了,即需要少量的CPU状态切换,提高了效率。
B)缓冲类型
标准I/O提供了3种类型的缓冲区。
1、全缓冲区:这种缓冲方式要求填满整个缓冲区后才进行I/O系统调用操作。对于磁盘文件的操作通常使用全缓冲的方式访问。第一次执行I/O操作时,ANSI标
准的文件管理函数通过调用malloc函数获得需要使用的缓冲区,默认大小为8192。
2、行缓冲区:在行缓冲情况下,当在输入和输出中遇到换行符时,标准I/O库函数将会执行系统调用操作。当所操作的流涉及一个终端时(例如标准输入和标准
输出),使用行缓冲方式。因为标准I/O库每行的缓冲区长度是固定的,所以只要填满了缓冲区,即使还没有遇到换行符,也会执行I/O系统调用操作,默认行缓冲区
的大小为1024。
3、无缓冲区:
无缓冲区是指标准I/O库不对字符进行缓存,直接调用系统调用。标准出错流stderr通常是不带缓冲区的,这使得出错信息能够尽快地显示出来。
注:
1、标准输入和标准输出设备:当且仅当不涉及交互作用设备时,标准输入流和标准输出流才是全缓冲的。
2、标准错误输出设备:标准出错绝不会是全缓冲方式的。
3、对于任何一个给定的流,可以调用setbuf()和setvbuf()函数更改其缓冲区类型。
下面我们通过如下程序来进一步了解缓冲区:
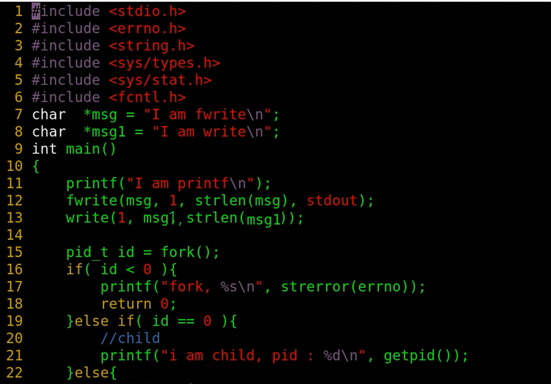

当打印到屏幕(标准输出):
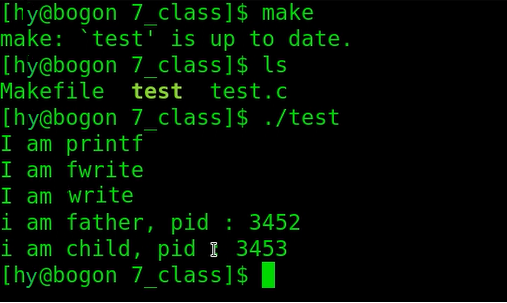
当写到文件中:

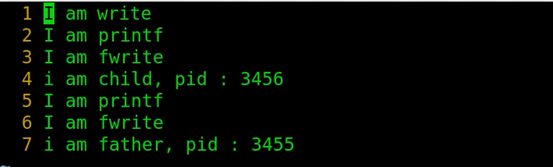
那么为什么输出到屏幕只有5条输出命令而输出到文件有7条输出命令呢?
根据输出结果我们可以看出printf和fwrite重复写了两次,没有重复打印的是write.。
printf和fwrite都是库函数:结合已有知识,我们了解到当使用库函数命令时,打印消息并没有直接写到输出位置上,而是 先把数据写到输出缓冲区,在刷新至输
出位置。
1、当输出目标位置为输出到显示器时,则刷新方式是行刷新;
2、当输出目标位置为输出到文件中时,刷新方式由行缓冲变为全缓冲,全缓冲是指当把缓冲区写满后才能刷新。(或者强制刷新)
代码中printf和fwrite第一次打印,在fork操作之前,第二次在fork操作之后,原因是因为在fork操作前,printf和fwrite的输出命令将数据先写到缓冲区中,此时
只执行了这两条命令,由于是全缓冲的刷新方式,所以这两条命令并不足以将缓存写满,所以数据暂存在缓冲区中;然后进行fork创建子进程,由于fork创建出的父子
进程代码共享,而数据不共享,各自私有一份,缓冲区中的数据都属于数据,因为父进程的残留数据还在缓冲区中,所以fork完毕后,父子进程将缓存中的数据各自存
一份有父进程残留数据的数据,所以当父子进程各自刷新时,父子进程会各自执行一次printf和fwrite的输出命令,所以命令就从原来的两条变为四条。
struct file 的其他重要成员有:.
1.mode_t f_mode;
文件模式确定文件是可读的或者是可写的(或者都是), 通过位 FMODE_READ 和FMODE_WRITE. 你可能想在你的 open 或者 ioctl 函数中检查这个成员的读写
许可, 但是不需要检查读写许可, 因为内核在调用你的方法之前检查. 当文件还没有为那种存取而打开时读或写的企图被拒绝, 驱动甚至不知道这个情况.
2.loff_t f_pos;
当前读写位置. loff_t 在所有平台都是 64 位( 在 gcc 术语里是 long long ). 驱动可以读这个值,如果它需要知道文件中的当前位置, 但是正常地不应该改变它; 读
和写应当使用它们作为最后参数而收到的指针来更新一个位置, 代替直接作用于 filp->f_pos. 这个规则的一个例外是在 llseek 方法中, 它的目的就是改变文件位置.
3.unsigned int f_flags;
这些是文件标志, 例如 O_RDONLY, O_NONBLOCK, 和 O_SYNC. 驱动应当检查O_NONBLOCK 标志来看是否是请求非阻塞操作; 其他标志很少使用. 特别地,
应当检查读/写许可, 使用 f_mode 而不是f_flags. 所有的标志在头文件<linux/fcntl.h> 中定义.
4.struct file_operations *f_op;
和文件关联的操作. 内核安排指针作为它的open 实现的一部分, 接着读取它当它需要分派任何的操作时. filp->f_op 中的值从不由内核保存为后面的引用; 这意味
着你可改变你的文件关联的文件操作, 在你返回调用者之后新方法会起作用. 例如, 关联到主编号 1 (/dev/null, /dev/zero, 等等)的 open 代码根据打开的次编号来替
代 filp->f_op 中的操作. 这个做法允许实现几种行为, 在同一个主编号下而不必在每个系统调用中引入开销. 替换文件操作的能力是面向对象编程的"方法重载"的内核对
等体.
5.void *private_data;
open 系统调用设置这个指针为 NULL, 在为驱动调用 open 方法之前. 你可自由使用这个成员或者忽略它; 你可以使用这个成员来指向分配的数据, 但是接着你必须
记住在内核销毁文件结构之前, 在 release 方法中释放那个内存. private_data 是一个有用的资源, 在系统调用间保留状态信息, 我们大部分例子模块都使用它.
6.struct dentry *f_dentry;
关联到文件的目录入口( dentry )结构. 设备驱动编写者正常地不需要关心 dentry 结构, 除了作为 filp->f_dentry->d_inode 存取 inode 结构.
Linux--struct file结构体【转】的更多相关文章
- Linux_Struct file()结构体
struct file结构体定义在/linux/include/linux/fs.h(Linux 2.6.11内核)中,其原型是:struct file { /* * f ...
- Linux--struct file结构体
struct file(file结构体): struct file结构体定义在include/linux/fs.h中定义.文件结构体代表一个打开的文件,系统中的每个打开的文件在内核空间都有一个关联的 ...
- file结构体
struct file结构体定义在include/linux/fs.h中定义.文件结构体代表一个打开的文件,系统中的每个打开的文件在内核空间都有一个关联的 struct file.它由内核在打开文件时 ...
- file结构体中private_data指针的疑惑
转:http://www.360doc.com/content/12/0506/19/1299815_209093142.shtml hi all and barry, 最近在学习字符设备驱动,不太明 ...
- C语言文件操作 FILE结构体
内存中的数据都是暂时的,当程序结束时,它们都将丢失.为了永久性的保存大量的数据,C语言提供了对文件的操作. 1.文件和流 C将每个文件简单地作为顺序字节流(如下图).每个文件用文件结束符结束,或者在特 ...
- file结构体中private_data指针的疑惑【转】
本文转载自:http://www.cnblogs.com/pengdonglin137/p/3328984.html hi all and barry, 最近在学习字符设备驱动,不太明白private ...
- struct socket结构体详解
原创作品,允许转载,转载时请务必以超链接形式标明文章 原始出处 .作者信息和本声明.否则将追究法律责任.http://weiguozhihui.blog.51cto.com/3060615/15852 ...
- Linux内核device结构体分析
1.前言 Linux内核中的设备驱动模型,是建立在sysfs设备文件系统和kobject上的,由总线(bus).设备(device).驱动(driver)和类(class)所组成的关系结构,在底层,L ...
- 2018.5.2 file结构体
f_flags,File Status Flag f_pos,表示当前读写位置 f_count,表示引用计数(Reference Count): dup.fork等系统调用会导致多个文件描述符指向同一 ...
随机推荐
- OllyDbg 使用笔记 (一)
OllyDbg 使用笔记 (一) 參考 书:<加密与解密> 视频:小甲鱼 解密系列 视频 ollydbg下载地址:http://tools.pediy.com/debuggers.htm ...
- 【ActionScript】Flash与网页的交互,ActionScript与JavaScript的交互
Flash是可以轻松与网页交互数据的,不然为何Flash会有这么大的生命力呢?仅仅是这样编程比較麻烦而已,又要调试Flash,然后又要放到server上调试. 只是这种方式可以收到非常好的效果.Fla ...
- 微信小程序 - 对象转换成对象数组
后端传过来的一个个对象 {1,2,3,4},{1,3,5,},{1,3,5} 我们应该转化为数组对象 [{},{},{},{}] ,最后通过wx:for遍历到页面 示例图:
- struts2获取文件真实路径
CreateTime--2017年8月25日15:59:33 Author:Marydon struts2获取文件真实路径 需要导入: import java.io.FileNotFoundExc ...
- php计算两个经纬度地点之间的距离(转)
php计算两个指定的经纬度地点之间的距离,这个在做计算给定某个地点的经纬度,计算其附近的商业区,以及给定地点与附近各商业区之间的距离的时候,还是用的到的.下面是具体的函数代码以及用法示例. 关于如何获 ...
- 【selenium+Python unittest】之使用smtplib发送邮件错误:smtplib.SMTPDataError:(554)、smtplib.SMTPAuthenticationError(例:126邮箱)
原代码如下: import smtplib from email.mime.text import MIMEText from email.header import Header #要发送的服务器 ...
- pooler [转]
pooler和poolboy都是用erlang写的管理进程池的库. pooler/poolboygithub : seth/pooler · GitHubgithub : devinus/poolbo ...
- vue 流程设计器
github地址:https://github.com/280780363/gucflow.designer demo地址:https://280780363.github.io/gucflow.de ...
- python读写数据篇
一.读写数据1.读数据 #使用open打开文件后一定要记得调用文件对象的close()方法.比如可以用try/finally语句来确保最后能关闭文件.file_object = open('thefi ...
- POJ 1163 The Triangle(经典问题教你彻底理解动归思想)
The Triangle Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 38195 Accepted: 22946 De ...