【ABAP系列】SAP ABAP 字符编码与解码、Unicode

前言部分
大家可以关注我的公众号,公众号里的排版更好,阅读更舒适。
正文部分
本文为转载文章
DATA : xstr TYPE xstring .
DATA : l_codepage ( 4 ) TYPE n .
DATA : l_encoding ( 20 ).
********** 字符集名与内码转换
" 将外部字符集名转换为内部编码
CALL FUNCTION 'SCP_CODEPAGE_BY_EXTERNAL_NAME'
EXPORTING
external_name = 'UTF-8'
IMPORTING
sap_codepage = l_codepage .
l_encoding = l_codepage .
********** 编码
DATA : convout TYPE REF TO cl_abap_conv_out_ce .
" 创建编码对象
convout = cl_abap_conv_out_ce => create ( encoding = l_encoding ).
convout -> write ( data = 'matinal测试 ' ). " 编码
xstr = convout -> get_buffer ( ). " 获取码流
WRITE : / xstr . "E6B19FE6ADA3E5869B
********** 解码
DATA : convin TYPE REF TO cl_abap_conv_in_ce .
" 创建解码对象
convin = cl_abap_conv_in_ce => create ( encoding = l_encoding input = xstr ).
DATA : str TYPE string .
CALL METHOD convin -> read " 解码
IMPORTING data = str .
WRITE : / str . " matinal测试
使用CL_ABAP_CODEPAGE类进行编解码:
DATA: xstr TYPE xstring,
str TYPE string,
l_codepage(4) TYPE n ,
l_encoding(20).
**********字符集名与内码转换
"将外部字符集名转换为内部编码
CALL FUNCTION 'SCP_CODEPAGE_BY_EXTERNAL_NAME'
EXPORTING
external_name = 'UTF-8'
IMPORTING
sap_codepage = l_codepage.
WRITE: / l_codepage.
"等同于下面类方法
l_codepage = cl_abap_codepage=>sap_codepage( 'UTF-8' ).
WRITE: / l_codepage.
"编码
xstr = cl_abap_codepage=>convert_to(
source = 'matinal测试'
codepage = `UTF-8` ).
WRITE: / xstr.
"解码
str = cl_abap_codepage=>CONVERT_FROM(
source = xstr
codepage = `UTF-8` ).
WRITE: / str.
4110
4110
E6B19FE6ADA3E5869B
matinal测试
ABAP中的特殊字符列表
cl_abap_char_utilities=>horizontal_tab — 09 TAB符
cl_abap_char_utilities=>CR_LF ———-- 0D0A 回车换行
cl_abap_char_utilities=>VERTICAL_TAB —- 0B 垂直制表符
cl_abap_char_utilities=>NEWLINE —---- 0A 换行
cl_abap_char_utilities=>FORM_FEED —--- 0C 换页
cl_abap_char_utilities=>BACKSPACE —---08 退格符
CL_ABAP_CHAR_UTILITIES=>BYTE_ORDER_MARK_LITTLE-----(utf-16le')的文件头
CL_ABAP_CHAR_UTILITIES=>BYTE_ORDER_MARK_UTF8-------(utf-8)的文件头
如果是要单独取得回车或者换行(不是回车加换行),可以采用:
cl_abap_char_utilities=>CR_LF(1)
cl_abap_char_utilities=>CR_LF 1(1)
空白字符:
System.out.println((int)' ');//12288
DATA: gc_result(50) TYPE c.
CONSTANTS: c_tab TYPE c VALUE cl_abap_char_utilities=>horizontal_tab.
CONCATENATE 'text01' c_tab 'text02' c_tab 'text03' INTO gc_result.
Unicode字符串互转
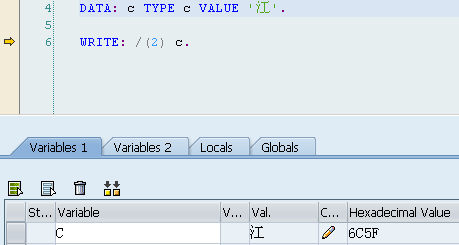
DATA: c(4) TYPE c VALUE 'ABCD'.
FIELD-SYMBOLS <fs1>.
"将字符串以十六进制的Unicode码来表示
ASSIGN c TO <fs1> type 'X'.
WRITE: / <fs1>.0041004200430044这是在AIX上测试的结果。注意,SAP上使用的是Unicode码,所以为双字节,在转换为十六进制时,与服务器所在操作系统的字节顺有关(Java是与平台无关的,在任何平台上都是高字节序),从这里就可以看出Windows与Unix上的字节序不是一样的。
"====分配时指定类型
DATA: x(8) TYPE x ."这里的8表示8个字节
x = <fs1>.
FIELD-SYMBOLS <fs3> .
"将十六进制的Unicode码转换为字符串
ASSIGN x TO <fs3> type 'C'. "C在这里是一般类型,代指字符串,而不是只一个C
WRITE:/ <fs3>.
"====通过强转
FIELD-SYMBOLS <fs4> TYPE c. "C在这里也是一般类型
ASSIGN x TO <fs4> CASTING.
WRITE:/ <fs4>.
4100420043004400
ABCD
ABCD
JAVA与ABAP中的Unicode
Java与ABAP内存存储字符时,都是以Unicode来编解码的。
注:平时我们讲的字节序是以字节为单位,字节与字节是有高低之分的,但在某个字节里是没有高低位之分的。就像下面江字那样,在低字节系统中为5F6C,而决不可能出现 F5 或 C6 之类的情况出现。
“江”字的Unicode编码为:27743(十进制),6C5F(十六进制)

从上面可以看出:Java中的Unicode编码是采用高字节序(符合人的阅读习惯),而ABAP中是采用低字节序(符合机器存储结构)(注意,可能与测试的环境有关。经测试,与测试环境确实有关系,请看下面在AIX机器上的测试结果——高字节顺序——高字节在前,低字节在后,符合人的阅读习惯,但与机器存储刚好相反——内存是从左到右字节地址越来越大,即内存前面是低字节,而后面是高字节。正是因为ABAP不像Java那样跨平台,所以在ABAP中可以通过CL_ABAP_CHAR_UTILITIES=>ENDIAN获得当前SAP所在的服务器的字节序类别;但是Java是跨平台的,在任何平台下都是采用上面的高字节序)
【ABAP系列】SAP ABAP 字符编码与解码、Unicode的更多相关文章
- 【转】python 字符编码与解码——unicode、str和中文:UnicodeDecodeError: 'ascii' codec can't decode
原文网址:http://blog.csdn.net/trochiluses/article/details/16825269 摘要:在进行python脚本的编写时,如果我们用python来处理网页数据 ...
- python字符编码与解码 unicode,str
解释以下几个问题: (1)python2中str和unicode是两种字符串类型,与字符编码方式是什么关系? (2)str和unicode是怎么相互转换的? (3)'\x...':'\u...', ' ...
- [SAP ABAP开发技术总结]字符编码与解码、Unicode
声明:原创作品,转载时请注明文章来自SAP师太技术博客( 博/客/园www.cnblogs.com):www.cnblogs.com/jiangzhengjun,并以超链接形式标明文章原始出处,否则将 ...
- 【ABAP系列】ABAP CL_ABAP_CONV_IN_CE
公众号:SAP Technical 本文作者:matinal 原文出处:http://www.cnblogs.com/SAPmatinal/ 原文链接:[ABAP系列]ABAP CL_ABAP_CON ...
- Python2/3的中、英文字符编码与解码输出: UnicodeDecodeError: 'ascii' codec can't decode/encode
摘要:Python中文虐我千百遍,我待Python如初恋.本文主要介绍在Python2/3交互模式下,通过对中文.英文的处理输出,理解Python的字符编码与解码问题(以点破面). 前言:字符串的编码 ...
- [19/03/28-星期四] IO技术_基本概念&字符编码与解码
一.概念 输入(Input) 指的是:可以让程序从外部系统获得数据(核心含义是“读”,读取外部数据) 常见的应用: Ø 读取硬盘上的文件内容到程序.例如:播放器打开一个视频文件.word打开一个do ...
- Java 字符编码与解码
1.字符编码的发展历程 ①.ASCII 码 因为计算机只认识数字,所以我们在计算机里面的一切数据都是以数字来表示,因为英文字符有限,所以规定使用的字节的最高位是 0,每一个字节都是以 0-127 之间 ...
- 字符编码(ASCII,Unicode和UTF-8) 和 大小端
本文包括2部分内容:“ASCII,Unicode和UTF-8” 和 “Big Endian和Little Endian”. 第1部分 ASCII,Unicode和UTF-8 介绍 1. ASCII码 ...
- 字符编码知识:Unicode、UTF-8、ASCII、GB2312等编码之间是如何转换的?
转自: http://apps.hi.baidu.com/share/detail/17798660 字符编码是计算机技术的基石,想要熟练使用计算机,就必须懂得字符编码的知识.不注意的人可能对这个不 ...
随机推荐
- 10—mybatis 通用mapper插件 pagehelper 分页
spring boot真的太好用了,大家以后多多使用,今天来说说pagehelper 来做mybatis分页,我用的是spring boot 做的开发,后面会把源码发出来. pagehelper(ht ...
- linux学习-添加多个硬盘和lvm配置
原文 一般,服务器会有多个硬盘,一块硬盘分区安装操作系统,另外多块硬盘分区做存储使用.现在测试添加多块硬盘分区,使用lvm进行实现动态磁盘分配. 1.新增硬盘查看 fdisk -l 可以看到新增的两块 ...
- Selenium+Java+Jenkins+TestNg
注意:各webdriver版本都有对应的浏览器版本 如果启动出现问题,可能是driver路径错误,需要使用System.setProperty("webdriver.firefox.bin& ...
- ZrOJ #878. 小K与赞助 (网络流)
傻逼最大费用流: . 两棵树分别流,最后汇合. CODE #include <bits/stdc++.h> using namespace std; #define pb push_bac ...
- 题解 [ZJOI2010]基站选址
题解 [ZJOI2010]基站选址 题面 解析 首先考虑一个暴力的DP, 设\(f[i][k]\)表示第\(k\)个基站设在第\(i\)个村庄,且不考虑后面的村庄的最小费用. 那么有\(f[i][k] ...
- webpack+vue+Eslint+husky+lint-staged 统一项目编码规范
一. Eslint: 为什么我们要在项目中使用ESLint ESLint可以校验我们写的代码,给代码定义一个规范,项目里的代码必须按照这个规范写. 加入ESLint有非常多的好处,比如说可以帮助我们避 ...
- [Luogu] 子共七
https://www.luogu.org/problemnew/show/P3131 A表示前缀和数组 A[r] - A[l - 1] = 0 (mod 7) 得 A[r] = A[l - 1] ( ...
- Codeforces 1175E Minimal Segment Cover
题意: 有\(n\)条线段,区间为\([l_i, r_i]\),每次询问\([x_i, y_i]\),问要被覆盖最少要用多少条线段. 思路: \(f[i][j]\)表示以\(i\)为左端点,用了\(2 ...
- JavaScript中BOM的重要内容总结
一.BOM介绍 BOM(Browser Object Model),浏览器对象模型: 用来操作浏览器部分功能的API: BOM由一系列的对象构成,由于主要用于管理窗口和窗口之间的通讯,所以核心对象是w ...
- springboot工程打成war包
1.将pom.xml中默认的jar修改为war. <packaging>war</packaging> 2.排除SpringBoot内置的Tomcat容器. <depen ...