centos7搭建伪分布式集群
centos7搭建伪分布式集群
需要
centos7虚拟机一台;
jdk-linux安装包一个
hadoop-2.x安装包1个(推荐2.7.x)
一、设置虚拟机网络为静态IP(最好设成静态,为之后编程提供方便,不设置静态ip也可以)
1、进入网络配置查看ip
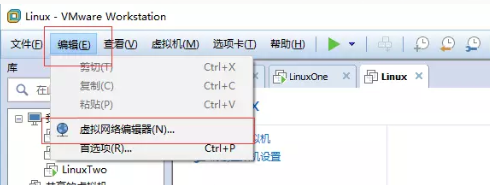
2、选择NAT模式链连接

3、点击NAT设置,记住网关IP,后面要用到

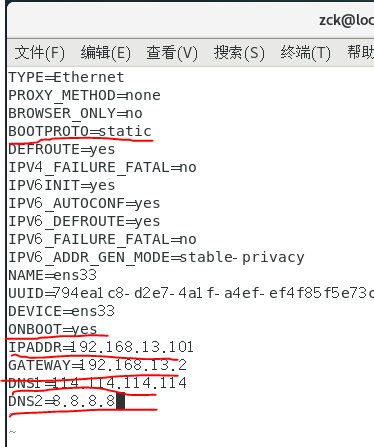
4、进入终端,输入命令: cd /etc/sysconfig/network-scripts,然后 vim ./ifcfg-eth0,(有的虚拟机是文件是:ifcfg-ens33)并进行如下设置,
【IPADDR为静态ip地址,格式必须与网关IP的前三位一样:192.168.13.X】 X在1-255之间
GATWAY是之前记得的网关IP.
其他的如图所示。
5、重启网络服务:service network restart

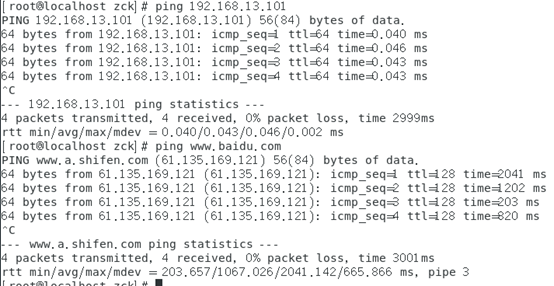
6、网络测试:ping网关,ping外网。都能ping通表示网络正常,大功告成(前提主机联网)
成功标志如图:
二、配置ssh免密登录(开启集群服务时不必每次都输入密码)
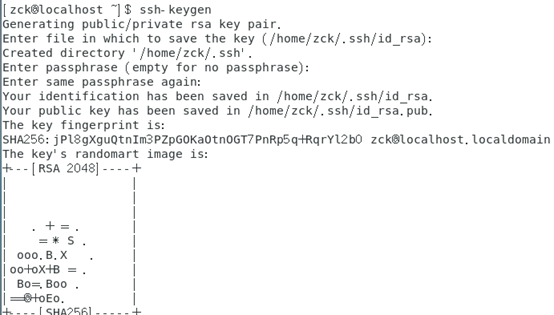
1、命令:ssh-keygen 一路回车。遇到overwrite(覆盖写入)输入y
2、将生成的密钥发送到本机地址:ssh-copy-id localhost
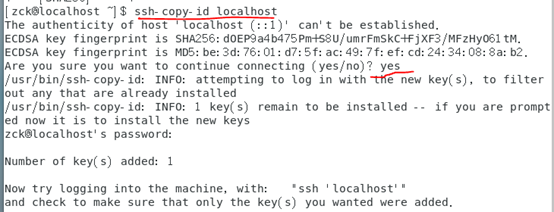
3、测试是否可以免密登录。出现下图解果就OK;
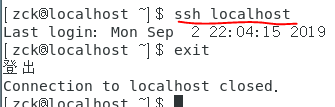
三、安装java环境(jdk)
1、卸载虚拟机自带的dk;
确定JDK版本
rpm –qa | grep jdk
rpm –qa | grep gcj

切换到root用户,根据结果卸载java
yum -y remove java-1.8.0-openjdk-headless.x86_64
yum -y remove java-1.7.0-openjdk-headless.x86_64
2、测试jdk是否卸载干净 java -version

3、安装jdk.
将jdk-linux-xxx解压到某一个文件夹(记好路径,不要有中文)

通过pwd命令查看当前路径

4、配置环境变量
在root用户下,将/etc/profile的权限赋给普通用户:chown -R zck:zck /etc/profile (zck是我的普通用户名,不然普通用户无法修改环境变量)


转到普通用户(zck)下,修改环境变量:vim /etc/profile (注意自己的jdk路径)


|
#java export JAVA_HOME=/home/hadoop/app/jdk1.8.0_141 export JAVA_JRE=JAVA_HOME/jre export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_JRE/lib export PATH=$PATH:$JAVA_HOME/bin |
5、保存退出,并使/etc/profile文件生效:source /etc/profile

6、测试jdk环境:java -version

四、安装hadoop
1、解压hadoop(同jdk)
2、配置环境变量(基本步骤与jdk一样)。
|
#hadoop |

3、测试(保存之后要source /etc/profile 不然环境变量修改不生效)
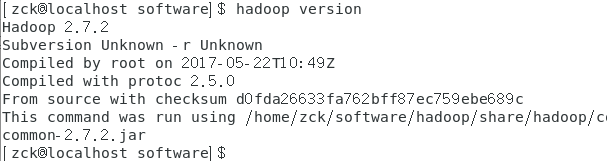
五、搭建伪分布式
修改5个配置文件
进入文件目录 ../hadoop/etc/hadoop
1、修改core-site.xml配置文件 (建议将localhost修改为你之前设置的静态ip)
|
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/data/tmp</value> </property> <property> <name>hadoop.proxyuser.hadoop.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.hadoop.groups</name> <value>*</value> </property> </configuration> |
2、修改hdfs-site.xml配置文件
|
<configuration> <property> <name>dfs.namenode.name.dir</name> <value>/data/dfs/name</value> <final>true</final> </property> <property> <name>dfs.datanode.data.dir</name> <value>/data/dfs/data</value> <final>true</final> </property> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> </configuration> |
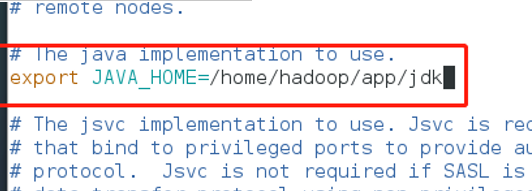
3、修改hadoop-env.sh配置文件(改成jdk位置)
4、修改mapred-site.xml.template配置文件(先重命名为mapred-site.xml)
|
<configuration> <property> <name>mapreduce.frameword.name</name> <value>yarn</value> </property> </configuration> |
5、修改yarn-site.xml配置文件
|
<property> <name>yarn.nodemanager.aux-servies</name> <value>mapreduce_shuffle</value> </property> </configuration> |
使修改生效,命令:sourec /etc/profile
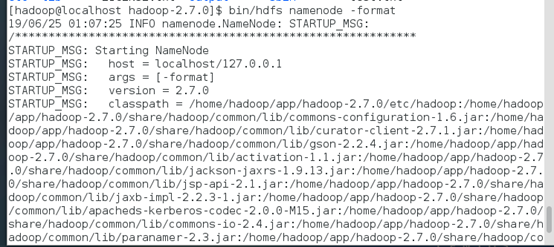
6、格式化namenode
切回到hadoop目录,输入如下命令:bin/hdfs namenode -format
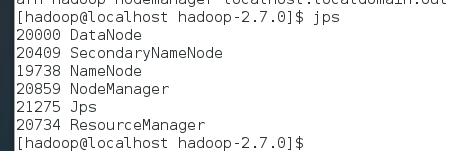
启动hadoop伪分布式集群:sbin/start-all.sh

启动完毕输入jps查看
centos7搭建伪分布式集群的更多相关文章
- hadoop搭建伪分布式集群(centos7+hadoop-3.1.0/2.7.7)
目录: Hadoop三种安装模式 搭建伪分布式集群准备条件 第一部分 安装前部署 1.查看虚拟机版本2.查看IP地址3.修改主机名为hadoop4.修改 /etc/hosts5.关闭防火墙6.关闭SE ...
- 超详细!CentOS 7 + Hadoop3.0.0 搭建伪分布式集群
超详细!CentOS 7 + Hadoop3.0.0 搭建伪分布式集群 ps:本文的步骤已自实现过一遍,在正文部分避开了旧版教程在新版使用导致出错的内容,因此版本一致的情况下照搬执行基本不会有大错误. ...
- hadoop(二)搭建伪分布式集群
前言 前面只是大概介绍了一下Hadoop,现在就开始搭建集群了.我们下尝试一下搭建一个最简单的集群.之后为什么要这样搭建会慢慢的分享,先要看一下效果吧! 一.Hadoop的三种运行模式(启动模式) 1 ...
- Redis集群搭建,伪分布式集群,即一台服务器6个redis节点
Redis集群搭建,伪分布式集群,即一台服务器6个redis节点 一.Redis Cluster(Redis集群)简介 集群搭建需要的环境 二.搭建集群 2.1Redis的安装 2.2搭建6台redi ...
- Hadoop伪分布式集群
一.HDFS伪分布式环境搭建 Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统.它和现有的分布式文件系统有很多共同点.但同时, ...
- Hadoop伪分布式集群环境搭建
本教程讲述在单机环境下搭建Hadoop伪分布式集群环境,帮助初学者方便学习Hadoop相关知识. 首先安装Hadoop之前需要准备安装环境. 安装Centos6.5(64位).(操作系统再次不做过多描 ...
- hadoop伪分布式集群搭建与安装(ubuntu系统)
1:Vmware虚拟软件里面安装好Ubuntu操作系统之后使用ifconfig命令查看一下ip; 2:使用Xsheel软件远程链接自己的虚拟机,方便操作.输入自己ubuntu操作系统的账号密码之后就链 ...
- Zookeeper 集群搭建--单机伪分布式集群
一. zk集群,主从节点,心跳机制(选举模式) 二.Zookeeper集群搭建注意点 1.配置数据文件 myid 1/2/3 对应 server.1/2/3 2.通过./zkCli.sh -serve ...
- CentOS中搭建Redis伪分布式集群【转】
解压redis 先到官网https://redis.io/下载redis安装包,然后在CentOS操作系统中解压该安装包: tar -zxvf redis-3.2.9.tar.gz 编译redis c ...
随机推荐
- MyBatis日期用法技巧
当你想在实体类中使用Java.util.Date类型,而且还想在数据库中保存时分秒时,你可以在xml中修改为: #{xxdate,jdbcType=TIMESTAMP} 就是将#{}中的jdbcTyp ...
- Hbuilder + MUI 的简单案例
话不多说 直接上代码 项目结构: index.html 的代码 <!DOCTYPE html><html> <head> <meta ch ...
- Codeforces Round #588 (Div. 2) A. Dawid and Bags of Candies
链接: https://codeforces.com/contest/1230/problem/A 题意: Dawid has four bags of candies. The i-th of th ...
- HDOJ 4858 项目管理 ( 只是有点 莫队的分块思想在里面而已啦 )
题目: 链接:http://acm.hdu.edu.cn/showproblem.php?pid=4858 题意: 我们建造了一个大项目!这个项目有n个节点,用很多边连接起来,并且这个项目是连通的! ...
- DockerAPI版本不匹配的问题
1.问题描述 在执行docker指令的时候显示client和server的API版本不匹配,如下: 说明:在这里server API的版本号比client API版本号低,因此不能有效实现cilent ...
- sudo/su
linux用户分为根用户/ 普通用户 系统用户 根用户和普通用户是可以实际登录到系统中的,普通用户是没办法使用useradd添加新用户的,只有根用户有权限 当然,也可以使用su su 是切换用户的意思 ...
- pat 甲级 1045 ( Favorite Color Stripe ) (动态规划 )
1045 Favorite Color Stripe (30 分) Eva is trying to make her own color stripe out of a given one. She ...
- 「BZOJ 5010」「FJOI 2017」矩阵填数「状压DP」
题意 你有一个\(h\times w\)的棋盘,你需要在每个格子里填\([1, m]\)中的某个整数,且满足\(n\)个矩形限制:矩形的最大值为某定值.求方案数\(\bmod 10^9+7\) \(h ...
- 【线性代数】3-4:方程组的完整解( $Ax=b$ )
title: [线性代数]3-4:方程组的完整解( Ax=bAx=bAx=b ) categories: Mathematic Linear Algebra keywords: Ax=b Specia ...
- luogu4281
P4281 [AHOI2008]紧急集合 / 聚会 题目描述 欢乐岛上有个非常好玩的游戏,叫做“紧急集合”.在岛上分散有N个等待点,有N-1条道路连接着它们,每一条道路都连接某两个等待点,且通过这些道 ...