pytorch中的激励函数(详细版)
import torch
import torch.nn.functional as F
from torch.autograd import Variable import matplotlib.pyplot as plt x = torch.linspace(-5, 5, 200) # 构造一段连续的数据
x = Variable(x) # 转换成张量
x_np = x.data.numpy() #plt中形式需要numoy形式,tensor形式会报错
- 非线性: 当激活函数是线性的时候,一个两层的神经网络就可以逼近基本上所有的函数了。但是,如果激活函数是恒等激活函数的时候(即f(x)=x),就不满足这个性质了,而且如果MLP使用的是恒等激活函数,那么其实整个网络跟单层神经网络是等价的。
- 可微性: 当优化方法是基于梯度的时候,这个性质是必须的。
- 单调性: 当激活函数是单调的时候,单层网络能够保证是凸函数。
- f(x)≈x: 当激活函数满足这个性质的时候,如果参数的初始化是random的很小的值,那么神经网络的训练将会很高效;如果不满足这个性质,那么就需要很用心的去设置初始值。
- 输出值的范围: 当激活函数输出值是 有限 的时候,基于梯度的优化方法会更加 稳定,因为特征的表示受有限权值的影响更显著;当激活函数的输出是 无限 的时候,模型的训练会更加高效,不过在这种情况小,一般需要更小的learning rate
3:常用的激活函数
早期研究神经网络主要采用sigmoid函数或者tanh函数,输出有界,很容易充当下一层的输入。近些年Relu函数及其改进型(如Leaky-ReLU、P-ReLU、R-ReLU等)在多层神经网络中应用比较多。下面我们来总结下这些激活函数:
- 3.1单极性 sigmod函数
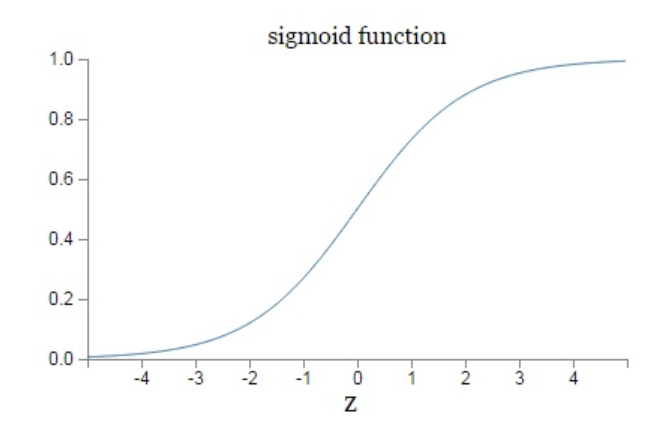
3.1.1:Sigmoid 是常用的非线性的激活函数,该函数是将取值为 (−∞,+∞)(−∞,+∞) 的数映射到 (0,1)之间,它的数学形式和图像如下:
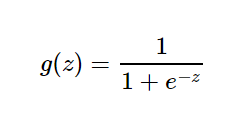
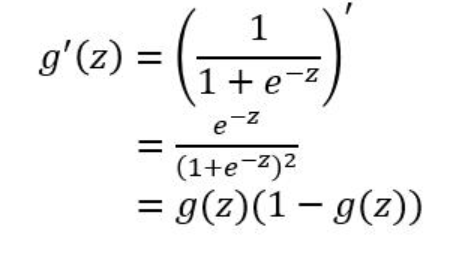
3.1.2:特点:
sigmod激励函数符合实际,当输入很小时,输出接近于0;当输入很大时,输出值接近1,但是sigmoid函数作为非线性激活函数,但是其并不被经常使用,它具有以下几个缺点:
1)当 zz 值非常大或者非常小时,通过右上图我们可以看到,sigmoid函数的导数 g′(z)g′(z) 将接近 0 。这会导致权重 WW 的梯度将接近 0 ,使得梯度更新十分缓慢,即梯度消失。
2)非零中心化,也就是当输入为0时,输出不为0,,因为每一层的输出都要作为下一层的输入,而未0中心化会直接影响梯度下降 。
3)计算量比较大。
sigmoid函数可用在网络最后一层,作为输出层进行二分类,尽量不要使用在隐藏层。
3.1.3:pytorch实现:
y_sigmoid = F.sigmoid(x).data.numpy() #初始化已经在上面实现
plt.plot(x_np, y_sigmoid, c='red', label='sigmoid')
plt.ylim((-0.2, 1.2))
plt.legend(loc='best') #图例名称自动选择最佳展示位置
plt.show() #展示图片和上面(中)类似
- 3.2:双极性tanh函数
3.2.1 :该函数是将取值为 (−∞,+∞)(−∞,+∞) 的数映射到 (−1,1)(−1,1) 之间,其数学形式与图形为:
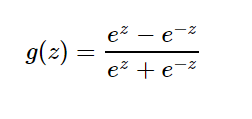
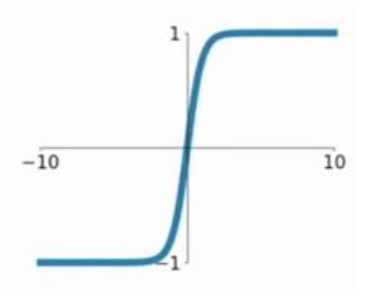
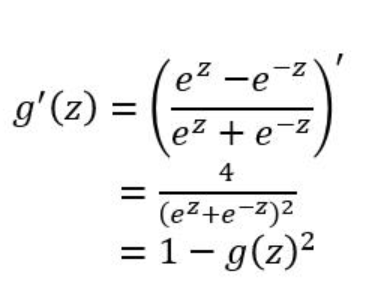
3.2.2:特点:
1)tanh函数在 0 附近很短一段区域内可看做线性的。由于tanh函数均值为 0 ,因此弥补了sigmoid函数均值为 0.5 的缺点。
2)当z为非常大或者非常小的时候,由导数推断公式可知,此时导数接近与0,会导致梯度很小,权重更新非常缓慢,即梯度消失问题。
3)幂运算问题仍然存在,计算量比较大。
3.2.3:pytorch实现:
y_tanh = F.tanh(x).data.numpy() #初始化在上面已经给出
plt.plot(x_np, y_tanh, c='red', label='tanh')
plt.ylim((-1.2, 1.2))
plt.legend(loc='best') plt.show()#展示图片和上图(中)相似。
- 3.3:Relu函数
3.3.1 :又称修正线性单元,是一种分段线性函数,其弥补了sigmoid函数以及tanh函数的梯度消失问题。ReLU函数的公式以及图形,导数公式如下:
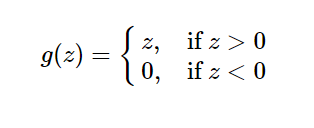
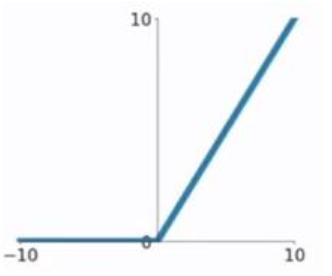
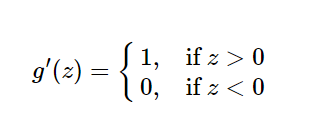
3.3.2:特点:
1)(1)在输入为正数的时候(对于大多数输入 zz 空间来说),不存在梯度消失问题。
(2) 计算速度要快很多。ReLU函数只有线性关系,不管是前向传播还是反向传播,都比sigmod和tanh要快很多。(sigmod和tanh要计算指数,计算速度会比较慢)
(3)当输入为负时,梯度为0,会产生梯度消失问题
ReLU目前仍是最常用的activation function,在搭建人工神经网络的时候推荐优先尝试!
3.3.3:pytorch实现:
y_relu = F.relu(x).data.numpy()
plt.plot(x_np, y_relu, c='red', label='relu')
plt.ylim((-1, 5))
plt.legend(loc='best') plt.show()
- 3.4:Leaky Relu函数
3.4.1:这是一种对ReLU函数改进的函数,又称为PReLU函数,但其并不常用。其公式与图形如下:(a取值在(0,1)之间)
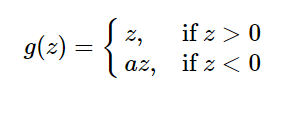
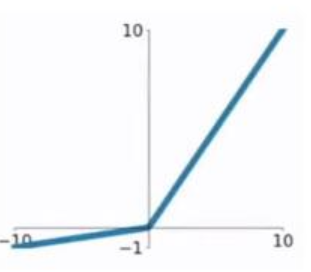
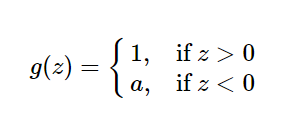
特点:
Leaky ReLU函数解决了ReLU函数在输入为负的情况下产生的梯度消失问题。
理论上来讲,Leaky ReLU有ReLU的所有优点,外加不会有Dead ReLU问题,但是在实际操作当中,并没有完全证明Leaky ReLU总是好于ReLU。
3.5:softplus函数
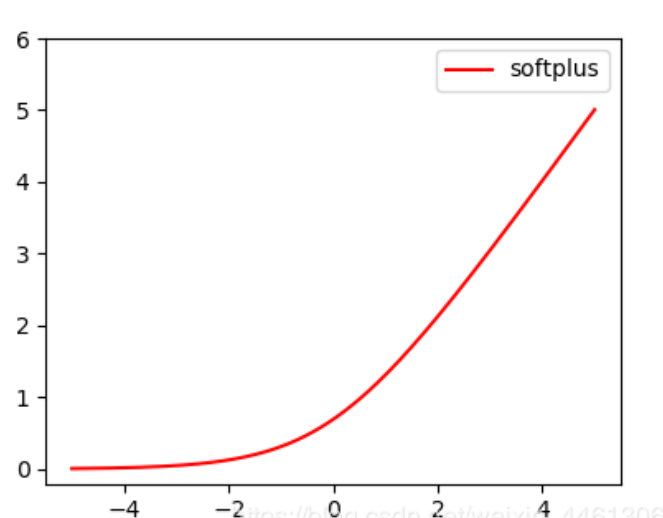
3.5.1:和relu一样为近似生物神经激活函数,函数数学形式和图像如下:(log里面加1是为了避免非0出现)
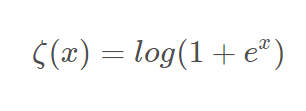
3.5.2:特点:
1)softplus可以看作是ReLu的平滑。
3.5.3:pytorch实现:
y_softplus = F.softplus(x).data.numpy()
plt.plot(x_np, y_softplus, c='red', label='softplus')
plt.ylim((-0.2, 6))
plt.legend(loc='best') plt.show()
4:怎么样去选择激励函数
1)在少量层结构中, 我们可以尝试很多种不同的激励函数. 在卷积神经网络 Convolutional neural networks 的卷积层中, 推荐的激励函数是 relu. 在循环神经网络中 recurrent neural networks, 推荐的是 tanh 或者是 relu 。
2)如果使用 ReLU,那么一定要小心设置 learning rate,而且要注意不要让网络出现很多 “dead” 神经元,如果这个问题不好解决,那么可以试试 Leaky ReLU、PReLU 或者 Maxout.
3)Relu->Lecky Relu/Elu>tanh>sigmoid
5:参考文献:
pytorch中的激励函数(详细版)的更多相关文章
- caffe学习--使用caffe中的imagenet对自己的图片进行分类训练(超级详细版) -----linux
http://blog.csdn.net/u011244794/article/details/51565786 标签: caffeimagenet 2016-06-02 12:57 9385人阅读 ...
- iOS App上架流程(2016详细版)
iOS App上架流程(2016详细版) 原文地址:http://www.jianshu.com/p/b1b77d804254 感谢大神整理的这么详细 一.前言: 作为一名iOSer,把开发出来的Ap ...
- 手把手Maven搭建SpringMVC+Spring+MyBatis框架(超级详细版)
手把手Maven搭建SpringMVC+Spring+MyBatis框架(超级详细版) SSM(Spring+SpringMVC+Mybatis),目前较为主流的企业级架构方案.标准的MVC设计模式, ...
- 使用keil建立标准STM32工程模版(图文详细版!)
1. 模板工程的创建(超级详细版,使用的是keil 4.5版本) 1.1创建工程目录 良好的工程结构能让文件的管理更科学,让开发更容易更方便,希望大家养成良好的习惯,使用具有合理结构的工程目录,当 ...
- doc命令大全(详细版)
doc命令大全(详细版) 1 echo 和 @回显命令@ #关闭单行回显echo off #从下一行开始关闭回显@echo ...
- SpringBoot整合Mybatis完整详细版二:注册、登录、拦截器配置
接着上个章节来,上章节搭建好框架,并且测试也在页面取到数据.接下来实现web端,实现前后端交互,在前台进行注册登录以及后端拦截器配置.实现简单的未登录拦截跳转到登录页面 上一节传送门:SpringBo ...
- SpringBoot整合Mybatis完整详细版
记得刚接触SpringBoot时,大吃一惊,世界上居然还有这么省事的框架,立马感叹:SpringBoot是世界上最好的框架.哈哈! 当初跟着教程练习搭建了一个框架,传送门:spring boot + ...
- Ubuntu 18.04 nvidia driver 390.48 安装 TensorFlow 1.12.0 和 PyTorch 1.0.0 详细教程
最近要在个人台式机上搭建TensorFlow和PyTorch运行环境,期间遇到了一些问题.这里就把解决的过程记录下来,同时也可以作为安装上述环境的过程记录. 如果没有遇到类似的问题,想直接从零安装上述 ...
- MySQL与MariaDB核心特性比较详细版v1.0(覆盖mysql 8.0/mariadb 10.3,包括优化、功能及维护)
注:本文严禁任何形式的转载,原文使用word编写,为了大家阅读方便,提供pdf版下载. MySQL与MariaDB主要特性比较详细版v1.0(不含HA).pdf 链接:https://pan.baid ...
随机推荐
- Redis主从复制配置+哨兵模式
架构设计: master:s0 slave:s1.s2 主机映射信息如下: 192.168.32.100 s0 192.168.32.101 s1 192.168.32.102 s2 1.安装Redi ...
- AOP初步
一刀切的AOP基础 软件开发的目的,最终是为了解决各种需求,包括业务和系统的,使用OOP可以对业务需求等普通关注点进行很好的抽象和封装,并且使之模块化. 但OOP却无法解决类似于日志.安全.事务等系统 ...
- 交换机配置——STP实验(指定特定交换机为根桥)
一.实验目的:将三层交换机Switch3设置为根桥交换机 二.拓扑图如下: 三.具体步骤 先说明一下,四个交换机形成环路,为解决环路问题交换机会自动进行选举,选举出一个根源,根桥交换机会决定一个最佳路 ...
- Mockito 2 参数匹配器
Mockito 通过使用 equals() 这种自然的 Java 样式来校验参数值.有时候,当需要有其他一些灵活性的时候,你可能会要求使用参数匹配(argument matchers). 请参考下面的 ...
- CDOJ 1135 邱老师看电影 概率dp
邱老师看电影 Time Limit: 3000/1000MS (Java/Others) Memory Limit: 65535/65535KB (Java/Others) Submit St ...
- 推荐系统系列(三):FNN理论与实践
背景 在FM之后出现了很多基于FM的升级改造工作,由于计算复杂度等原因,FM通常只对特征进行二阶交叉.当面对海量高度稀疏的用户行为反馈数据时,二阶交叉往往是不够的,三阶.四阶甚至更高阶的组合交叉能够进 ...
- ERROR: virtualenvwrapper could not find virtualenv in your path
环境: Ubuntu 18.04 Python3 使用pip3安装virtualenv和virtualenvwrapper两个包,ubuntu18.04中,用户使用pip安装的包在~/.local/下 ...
- linux修改ulimit参数
有如下三种修改方式: 1.在/etc/rc.local 中增加一行 ulimit -SHn 655352.在/etc/profile 中增加一行 ulimit -SHn 655353.在/etc/se ...
- Keras学习笔记一:修改数据读入方式为本地图片读入
第一种方法: Keras官方给的图片去噪示例要自动下载mnist数据集并处理,不能修改和加入自己的数据集. from keras.datasets import mnist (x_train, _), ...
- springMVC中的ModelAndView说明
ModelAndView 类别就如其名称所示,是代表了Spring Web MVC程式中呈现画面时所使用Model资料物件与View资料物件,由于Java程式中一次只能返回一个物件,所以ModelAn ...