Python Multiprocessing 多进程,使用多核CPU计算 并使用tqdm显示进度条
1.背景
在python运行一些,计算复杂度比较高的函数时,服务器端单核CPU的情况比较耗时,因此需要多CPU使用多进程加快速度
2.函数要求
笔者使用的是:pathos.multiprocessing 库,进度条显示用tqdm库,安装方法:
pip install pathos
安装完成后
from pathos.multiprocessing import ProcessingPool as Pool
from tqdm import tqdm
这边使用pathos的原因是因为,multiprocessing 库中的Pool 函数只支持单参数输入,例如 f(x) = x**2,而不能处理 f (x,y) = x+y 这类的函数
更不用说一些需要参数的函数 例如:F(x , alpha=0.5, gamma = 0.1) 这样。
3.代码
定义一个 函数 F [ X ] ,其中,输入X是可以在第一个维度上迭代的array, 大小:[ num_X, len ] , 在第一维度 num_X 上进行迭代。
def F(X,lamda=10,weight=0.05):
res={}
res.update(F_1(X,lamda=lamda,weight=weight))
res.update(F_2(X,lamda=lamda,weight=weight))
return res
x 是 F 的输出,是一个dict (字典格式)
这里的两个函数超参数 lamda 和 weight 虽然每次调用的时候值是一样的,但是还是需要放一个数组每次用于迭代。
zip_lamda = [lamda for i in range(len(X)) ]
zip_weight = [weight for i in range(len(X)) ] with tqdm(total=len(cold_sequences)) as t:
for i, x in enumerate(pool.imap(F,X,zip_lamda,zip_weight)):
X[i,:] = [x[key] for key in x.keys()]
Y[i,] = 0
t.update() pool.close()
pool.join()
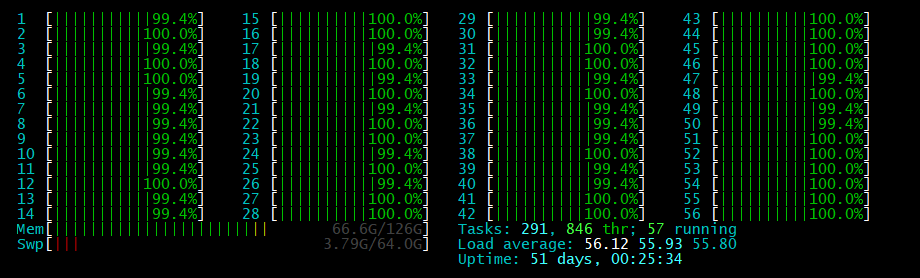
4.结果
mutiprocess 加速前

mutiprocess 加速后
Python Multiprocessing 多进程,使用多核CPU计算 并使用tqdm显示进度条的更多相关文章
- python多线程不能利用多核cpu,但有时候多线程确实比单线程快。
python 为什么不能利用多核 CPU GIL 其实是因为在 python中有一个 GIL( Global Interpreter Lock),中文为:全局解释器锁. 1.最开始时候设计GIL是 ...
- 利用Python计算π的值,并显示进度条
利用Python计算π的值,并显示进度条 第一步:下载tqdm 第二步;编写代码 from math import * from tqdm import tqdm from time import ...
- go/node/python 多进程与多核cpu
node node单线程,没有并发,但是可以利用cluster进行多cpu的利用.cluster是基于child_process的封装,帮你做了创建子进程,负载均衡,IPC的封装. const clu ...
- python multiprocessing多进程应用
multiprocessing包是Python中的多进程管理包,可以利用multiprocessing.Process对象来创建进程,Process对象拥有is_alive().join([timeo ...
- python 全栈开发,Day36(作业讲解(大文件下载以及进度条展示),socket的更多方法介绍,验证客户端链接的合法性hmac,socketserver)
先来回顾一下昨天的内容 黏包现象粘包现象的成因 : tcp协议的特点 面向流的 为了保证可靠传输 所以有很多优化的机制 无边界 所有在连接建立的基础上传递的数据之间没有界限 收发消息很有可能不完全相 ...
- Python:如何显示进度条
首先,推荐一个组件:progressive 效果如下: 进度条和一般的print区别在哪里呢? 答案就是print会输出一个\n,也就是换行符,这样光标移动到了下一行行首,接着输出,之前已经通过std ...
- python显示进度条
当一个python任务是需要逐个处理相同的事物时(里面有循环操作,例如对一系列的文件进行处理),这时可以将处理的进度条加进来,下面是一个例子: import time import sys def v ...
- python Multiprocessing 多进程应用
在运维工作中,经常要处理大量数据,或者要跑一些时间比较长的任务,可能都需要用到多进程,不管是管理端下发任务,还是客户端执行任务,如果服务器配置还可以,跑多进程还是挺能解决问题的 Multiproces ...
- python multiprocessing多进程模块
原文:https://blog.csdn.net/CityzenOldwang/article/details/78584175 多进程 Multiprocessing 模块 multiprocess ...
随机推荐
- 原生JavaScript常用本地浏览器存储方法四(HTML5 LocalStorage sessionStorage)
HTML5 LocalStorage浏览器的支持的情况如上图,IE在8.0的时候就支持了.不过需要注意的是,IE测试的时候需要服务器环境(或者localhost). 测试自然是检测浏览器是否支持本地存 ...
- SpringBoot学习笔记:动态数据源切换
SpringBoot学习笔记:动态数据源切换 数据源 Java的javax.sql.DataSource接口提供了一种处理数据库连接的标准方法.通常,DataSource使用URL和一些凭据来建立数据 ...
- 【计算机视觉】SeetaFace Engine开源C++人脸识别引擎
SeetaFace Engine是一个开源的C++人脸识别引擎,它可以在不依赖第三方的条件下载CPU上运行.他包含三个关键部分,即:SeetaFace Detection,SeetaFace Alig ...
- 深入css过渡transition
通过过渡transition,可以让web前端开发人员不需要javascript就可以实现简单的动画交互效果.过渡属性看似简单,但实际上它有很多需要注意的细节和容易混淆的地方. 过渡transitio ...
- idea的maven依赖本地jar
可以手动添加jar,但是idea手动添加jar时,有时候不行. 用maven依赖本地jar方法,感觉比较正规,不会因为自己忘记手动添加jar. 比如这个达梦数据库依赖 <dependency&g ...
- 基因id转换
DAVID网站提供了id转换的功能 1 选择上传gene list文件 2 选择上传ID的类型,我们ID-list.txt中的是Ensembl Gene ID,所以这里选ENSEMBL_GENE_ID ...
- cuda-convnet在Ubuntu12.04+CUDA5.5下的配置
deep learning近年来非常之火,尤其是在IMAGENET上的识别效果更是惊呆了小伙伴,其所用的Hinton的学生编写的cuda-convet代码早已公开,但是一直没有时间去仔细研究,最近趁着 ...
- Cannot assign requested address的解决办法
今天想试一下redis,写了个程序,对redis连续进行100000访问,却出现以了Cannot assign requested address的问题,我起先是以为是redis的问题(可能承受不了这 ...
- ding
Import "shanhai.lua"Dim currHour,currMinute,currSecondDim mmRnd = 0Dim sumFor=Int(ReadUICo ...
- LeetCode 590. N叉树的后序遍历(N-ary Tree Postorder Traversal)
590. N叉树的后序遍历 590. N-ary Tree Postorder Traversal 题目描述 给定一个 N 叉树,返回其节点值的后序遍历. LeetCode590. N-ary Tre ...