内部排序总结之----插入类排序(插入和Shell)
一、直接插入排序
直接插入排序(straight insertion sort)的做法是:
每次从无序表中取出第一个元素,把它插入到有序表的合适位置,使有序表仍然有序。
第一趟比较前两个数,然后把第二个数按大小插入到有序表中; 第二趟把第三个数据与前两个数从后向前扫描,把第三个数按大小插入到有序表中;依次进行下去,进行了(n-1)趟扫描以后就完成了整个排序过程。
void insertSort(int arr[],int len)
{
int i,j;
for(i = ; i < len; ++i)
{
for(j = i; j > && arr[j] < arr[j-]; --j)//j为待排序序列头部
{
int tmp = arr[j];
arr[j] = arr[j-];
arr[j-] = tmp;
}
}
}
直接插入排序总结:
时间复杂度:平均情况O(n2),最好情况O(n),最坏情况O(n2)
空间复杂度:O(1)
稳定性:稳定
直接插入排序较为简单,一笔带过,我们下面看看另一种优化的插入排序---Shell排序。
二、Shell排序
观察一下”插入排序“:其实不难发现它有个缺点:
如果当数据是“5, 4, 3, 2, 1”的时候,此时我们将“待排序序列”中的记录插入到“有序序列”时,每次比较都要挪动数据,此时插入排序的效率可想而知。
shell根据这个弱点进行了算法改进,融入了一种叫做“缩小增量排序法”的思想,其实也蛮简单的,不过有点注意的就是:增量不是乱取,而是有规律可循的。
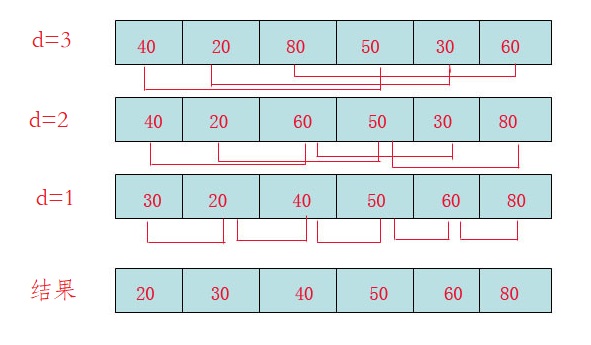
d=3时:将40跟50比,因50大,不交换。
将20跟30比,因30大,不交换。
将80跟60比,因60小,交换。
d=2时:将40跟60比,不交换,拿60跟30比交换,此时交换后的30又比前面的40小,又要将40和30交换,如上图。
将20跟50比,不交换,继续将50跟80比,不交换。
d=1时:这时就是前面讲的插入排序了,不过此时的序列已经差不多有序了,所以给插入排序带来了很大的性能提高。
插入类排序的特点就是:越有序越快。
#include <stdio.h> void Shell(int arr[],int arr_len,int dk)
{
int i,j;
//此时dk就是一个单位长度,相当于直接插入排序中的1 for(i = dk; i < arr_len; ++i)
{
for(j = i - dk; j >= 0 && arr[j+dk] < arr[j]; j -=dk)
{
int tmp = arr[j+dk];
arr[j+dk] = arr[j];
arr[j] = tmp;
}
}
} void ShellSort(int arr[],int arr_len,int dka[],int dka_len)//分组
{
int i;
for (i = 0; i < dka_len; i++)
{
Shell(arr,arr_len,dka[i]);
}
} void Show(int arr[],int len)
{
for(int i = 0; i < len; i++)
{
printf("%d ",arr[i]);
}
printf("\n"); }
int main ()
{
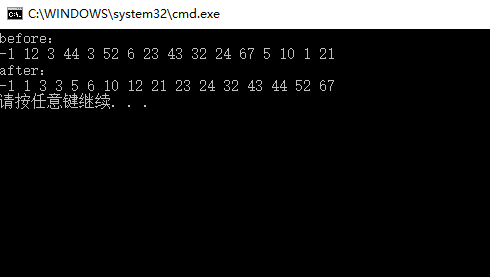
int arr[] = {-1,12,3,44,3,52,6,23,43,32,24,67,5,10,1,21};
int dk[] = {5,3,1};
int len = sizeof(arr)/sizeof(arr[0]);
int lenDk = sizeof(dk)/sizeof(dk[0]); printf("before:\n");
Show(arr,len);
ShellSort(arr,len,dk,lenDk);
printf("after:\n");
Show(arr,len);
return 0;
}
那么如何选取关键字呢?就是分成三组,一组,这个分组的依据是什么呢?为什么不是二组,六组或者其它组嘞?
增量序列的共同特征:
① 最后一个增量必须为1(如果最后一个增量不为1,会出现有数据没有参加排序)
② 应该尽量避免序列中的值(尤其是相邻的值)互为倍数的情况(如果为倍数,相当于,后面的排序再重复之前的行为)
Shell排序总结:
时间复杂度:平均情况O(n1.3),最好情况O(n),最坏情况O(n2)
空间复杂度:O(1)
稳定性:不稳定
优劣:

),Shell排序时间复杂度的下界是n*log2n。Shell排序没有快速排序算法快 O(n(logn)),因此中等大小规模表现良好,对规模非常大的数据排序不是最优选择。但是比O(

)复杂度的算法快得多。并且Shell排序非常容易实现,算法代码短而简单。 此外,Shell算法在最坏的情况下和平均情况下执行效率相差不是很多,与此同时快速排序在最坏的情况下执行的效率会非常差。专家们提倡,几乎任何排序工作在开始时都可以用Shell排序,若在实际使用中证明它不够快,再改成快速排序这样更高级的排序算法. 本质上讲,Shell排序算法是直接插入排序算法的一种改进,减少了其复制的次数,速度要快很多。 原因是,当n值很大时数据项每一趟排序需要移动的个数很少,但数据项的距离很长。当n值减小时每一趟需要移动的数据增多,此时已经接近于它们排序后的最终位置。 正是这两种情况的结合才使Shell排序效率比插入排序高很多。Shell算法的性能与所选取的分组长度序列有很大关系。只对特定的待排序记录序列,可以准确地估算关键词的比较次数和对象移动次数。想要弄清关键词比较次数和记录移动次数与增量选择之间的关系,并给出完整的数学分析,至今仍然是数学难题。
内部排序总结之----插入类排序(插入和Shell)的更多相关文章
- 【PHP数据结构】插入类排序:简单插入、希尔排序
总算进入我们的排序相关算法的学习了.相信不管是系统学习过的还是没有系统学习过算法的朋友都会听说过许多非常出名的排序算法,当然,我们今天入门的内容并不是直接先从最常见的那个算法说起,而是按照一定的规则一 ...
- C语言排序算法学习笔记——插入类排序
排序就是讲原本无序的序列重新排序成有序的序列.序列里可以是一个单独数据,也可以是多个数据组合的记录,按照记录里的主关键字或者次关键字进行排序. 排序的稳定性:如果排序表中有两个元素R1,R2,其对应的 ...
- Java实现单词自定义排序|集合类、工具类排序、comparable、comparator接口
课题 针对单词进行排序,先按字母的长度排序,长者在前: 在长度相等的情况下,按字典降序排序. 例如,有单词序列"apple banana grape orange",排序后输出结果 ...
- 剑指offer 查找和排序的基本操作:查找排序算法大集合
重点 查找算法着重掌握:顺序查找.二分查找.哈希表查找.二叉排序树查找. 排序算法着重掌握:冒泡排序.插入排序.归并排序.快速排序. 顺序查找 算法说明 顺序查找适合于存储结构为顺序存储或链接存储的线 ...
- java中的TreeMap如何顺序按照插入顺序排序
java中的TreeMap如何顺序按照插入顺序排序 你可以使用LinkedHashMap 这个是可以记住插入顺序的. 用LinkedHashMap吧.它内部有一个链表,保持插入的顺序.迭代的时候,也 ...
- Java四种排序:冒泡,选择,插入,二分(折半插入)
四种排序:冒泡,选择,插入,二分(折半插入) public class Test{ // public static void main(String[] args) { // Test t=new ...
- php插入式排序的两种写法。
百度了下插入式排序,百度百科中php版本的插入式排序如下: function insert_sort($arr) { // 将$arr升序排列 $count = count($arr); for ($ ...
- 左神算法第一节课:复杂度、排序(冒泡、选择、插入、归并)、小和问题和逆序对问题、对数器和递归(Master公式)
第一节课 复杂度 排序(冒泡.选择.插入.归并) 小和问题和逆序对问题 对数器 递归 1. 复杂度 认识时间复杂度常数时间的操作:一个操作如果和数据量没有关系,每次都是固定时间内完成的操作,叫做常数 ...
- 《Entity Framework 6 Recipes》中文翻译系列 (16) -----第三章 查询之左连接和在TPH中通过派生类排序
翻译的初衷以及为什么选择<Entity Framework 6 Recipes>来学习,请看本系列开篇 3-10应用左连接 问题 你想使用左外连接来合并两个实体的属性. 解决方案 假设你有 ...
随机推荐
- vue采坑之——vue里面渲染html 并添加样式
在工作中,有次遇到要把返回的字符串分割成两部分,一部分用另外的样式显示. 这时候,我想通过对得到字符串进行处理,在需要特别样式的字符串片段用html标签(用的span)包裹起来再通过变量绑定就好了.不 ...
- Docker Registry搭建
一.前言 Docker官方镜像仓库 访问速度很慢,Docker Registry允许搭建我们自己的镜像仓库,为实现镜像拉取.推送提供便利. 二.安装与启动 1.创建目录 mkdir /usr/loca ...
- Node.js Express项目搭建
讲干货,不啰嗦,Express 是一个简洁而灵活的 node.js Web应用框架,使用 Express 可以快速地搭建一个完整功能的网站.本教程介绍如何从零开始搭建Express项目. 开发环境:w ...
- 0502 xss 实验
0x01 dvwa xss(reflected) 1.1 Security Level: low use the typical <script>alert(1)</script&g ...
- const成员函数和const对象
从成员函数说起 在说const成员函数之前,先说一下普通成员函数,其实每个成员函数都有一个隐形的入参:T *const this. int getValue(T *const this) { retu ...
- Windows下同时安装两个版本Jdk
在项目开发中遇到了jdk版本切换的问题,于是尝试在电脑中安装jdk1.6和jdk1.7,话不多说马上开始 1 准备好两个版本的jdk路径 2 设置两个JAVA_HOME 3 设置总的动态切换的JAVA ...
- 高性能Java科学与技术运算库Colt
在学习<Machine Learning in Action>和<NLTK Natural Language Processing with Python>的过程中,我真切地感 ...
- Linux基础篇之CentOS的网络配置(DHCP,静态)
1.启动系统,使用用户名.密码登录系统: 2. 配置网卡(DHCP获取IP地址.静态手动配置IP地址): 网卡的默认信息 DHCP模式修改为(下图): 静态IP地址修改为(下图): 无论哪种配置, ...
- RT-Thread代码启动过程与$Sub$ $main、$Super$ $main
文章转载自:https://blog.csdn.net/yang1111111112/article/details/80913001 我们找到系统复位的地方,可以往下单步跟踪. ①从系统初始化开始执 ...
- Django框架orm
一.django目录 二.登录注册 三.三件套 四.orm简介 五.基于orm的用户登录 一.django目录 -settings -urls -views -强调:setting中的'django. ...