【D3D12学习手记】CPU/GPU Synchronization
由于有两个并行运行的处理器(CPU和GPU),会出现许多同步问题。
假设我们有一些资源R存储了我们希望绘制的某些几何体的位置。 此外,假设CPU更新R的数据以存储位置p1,然后将引用R的绘图命令C添加到命令队列,目的是在位置p1处绘制图形。 将命令添加到命令队列不会阻塞CPU,因此CPU会继续运行。 在GPU执行绘图命令C之前,CPU继续并覆盖R的数据以存储新位置p2将会导致错误(参见下图)。
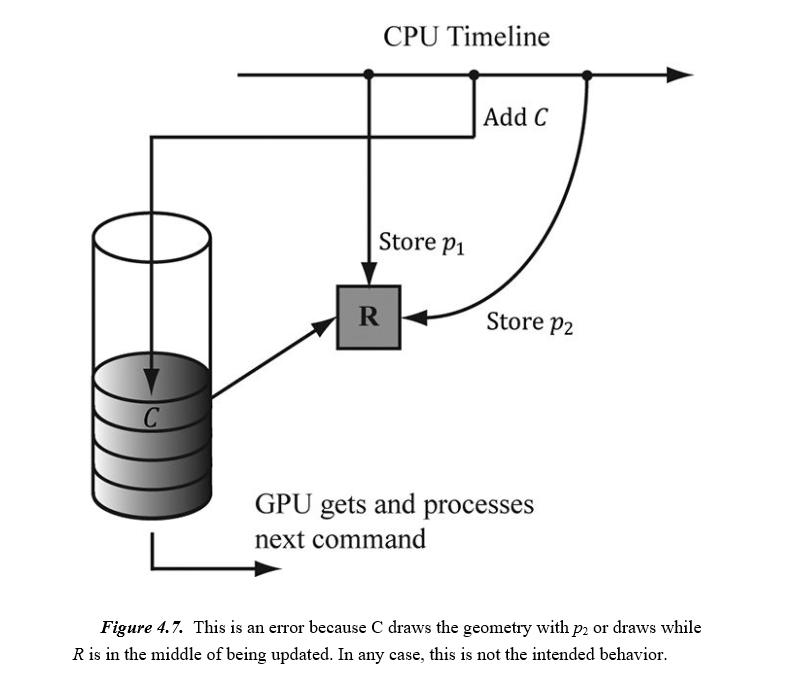
这种情况的一种解决方案是强制CPU等待GPU完成处理队列中的所有命令直到指定的栅栏点(fence point)。 我们称之为刷新命令队列(flushing the command queue)。 我们可以使用栅栏(fence)来做到这一点。 栅栏由ID3D12Fence接口表示,用于同步GPU和CPU。 可以使用以下方法创建fence对象:
HRESULT ID3D12Device::CreateFence(
UINT64 InitialValue,
D3D12_FENCE_FLAGS Flags,
REFIID riid,
void **ppFence); // Example
ThrowIfFailed(md3dDevice->CreateFence(
,
D3D12_FENCE_FLAG_NONE,
IID_PPV_ARGS(&mFence)));
fence对象维护UINT64值,该值只是一个整数,用于标识栅栏时间点。 我们从零开始,每次我们需要标记一个新的栅栏点时,我们只是递增整数。 现在,以下代码/注释显示了我们如何使用fence来刷新命令队列。
UINT64 mCurrentFence = ;
void D3DApp::FlushCommandQueue()
{
// Advance the fence value to mark commands up to this fence point.
mCurrentFence++; // Add an instruction to the command queue to set a new fence point.
// Because we are on the GPU timeline, the new fence point won’t be
// set until the GPU finishes processing all the commands prior to
// this Signal().
ThrowIfFailed(mCommandQueue->Signal(mFence.Get(), mCurrentFence)); // Wait until the GPU has completed commands up to this fence point.
if(mFence->GetCompletedValue() < mCurrentFence)
{
HANDLE eventHandle = CreateEventEx(nullptr, false, false, EVENT_ALL_ACCESS); // Fire event when GPU hits current fence.
ThrowIfFailed(mFence->SetEventOnCompletion(mCurrentFence, eventHandle));
// Wait until the GPU hits current fence event is fired.
WaitForSingleObject(eventHandle, INFINITE);
CloseHandle(eventHandle);
}
}
图4.8以图形方式解释了此代码。
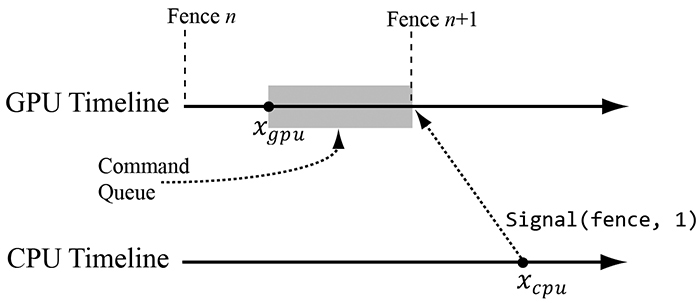
图4.8。 在这个快照中,GPU已经处理了直到xgpu之前的命令,而CPU刚刚调用了ID3D12CommandQueue :: Signal(fence,n + 1)方法。 这实质上是在队列末尾添加一条指令,将fence值更改为n + 1.但是,mFence-> GetCompletedValue()将继续返回n,直到GPU处理完队列中在Signal指令之前的所有命令。
因此在前面的示例中,在CPU发出绘图命令C之后,它将在覆盖R的数据之前刷新命令队列以存储新位置p2。 这个解决方案并不理想,因为它意味着CPU在等待GPU完成时处于空闲状态,但它提供了一个简单的解决方案,我们将在第7章之前使用它。您几乎可以在任何时候刷新命令队列(每帧不一定只有一次); 比如如果您有一些初始化GPU命令,则可以在进入主渲染循环之前刷新命令队列以执行初始化。
请注意,刷新命令队列也可用于解决我们在上一节末尾提到的问题; 也就是说,我们可以刷新命令队列,以确保在重置命令分配器之前已经执行了所有GPU命令。
【D3D12学习手记】CPU/GPU Synchronization的更多相关文章
- 【D3D12学习手记】The Command Queue and Command Lists
GPU有一个命令队列,CPU通过Direct3D API将命令提交到队列里来使用命令列表(command lists),如下图.当一套命令(a set of commands)已经被提交到命令队列,他 ...
- 【D3D12学习手记】4.3.8 Create the Depth/Stencil Buffer and View
我们现在需要创建深度/模板缓冲区. 如§4.1.5所述,深度缓冲区只是一个2D纹理,用于存储最近的可见对象的深度信息(如果使用模板(stencil),则也会存储模板信息). 纹理是一种GPU资源,因此 ...
- 【D3D12学习手记】4.1.6 Resources and Descriptors
在渲染过程中,GPU将写资源(resources)(例如,后缓冲区,深度/模板缓冲区),读资源(例如,描述表面外观的纹理,存储场景中几何体3D位置的缓冲区).在我们发出绘图命令之前,我们需要将资源绑定 ...
- 【D3D12学习手记】The Swap Chain and Page Flipping
为了避免动画中的闪烁,最好将整个动画帧绘制到称为后台缓冲区的屏幕外纹理(off-screen texture)中.一旦整个场景被绘制到给定动画帧的后缓冲区,它就作为一个完整的帧呈现给屏幕;以这种方式, ...
- Linux.NET学习手记(7)
前一篇中,我们简单的讲述了下如何在Linux.NET中部署第一个ASP.NET MVC 5.0的程序.而目前微软已经提出OWIN并致力于发展VNext,接下来系列中,我们将会向OWIN方向转战. 早在 ...
- Raspberry Pi B+ 定时向物联网yeelink上传CPU GPU温度
Raspberry Pi B+ 定时向物联网yeelink上传CPU GPU温度 硬件平台: Raspberry Pi B+ 软件平台: Raspberry 系统与前期安装请参见:树莓派(Ros ...
- 舌尖上的硬件:CPU/GPU芯片制造解析(高清)(组图)
一沙一世界,一树一菩提,我们这个世界的深邃全部蕴藏于一个个普通的平凡当中.小小的厨房所容纳的不仅仅是人们对味道的情感,更有推动整个世界前进的动力.要想理解我们的世界,有的时候只需要细细品味一下我们所喜 ...
- CPU/GPU/TPU/NPU...XPU都是什么意思?
CPU/GPU/TPU/NPU...XPU都是什么意思? 现在这年代,技术日新月异,物联网.人工智能.深度学习等概念遍地开花,各类芯片名词GPU, TPU, NPU,DPU层出不穷......都是什么 ...
- 深度学习框架:GPU
深度学习框架:GPU Deep Learning Frameworks 深度学习框架通过高级编程接口为设计.训练和验证深度神经网络提供了构建块.广泛使用的深度学习框架如MXNet.PyTorch.Te ...
随机推荐
- 洛谷 P2939 [USACO09FEB]改造路Revamping Trails
题意翻译 约翰一共有N)个牧场.由M条布满尘埃的小径连接.小径可 以双向通行.每天早上约翰从牧场1出发到牧场N去给奶牛检查身体. 通过每条小径都需要消耗一定的时间.约翰打算升级其中K条小径,使之成为高 ...
- linux下进程间通信的机制
今天突然想起了nginx解决惊群的方法,就是在多个进程间利用锁来保证同一时刻只能有一个worker进程在自己的epoll中加入监听的句柄,那么进程间是怎么共享变量的呢,下面就介绍一下共享内存 共享内存 ...
- Linux常用命令type、date
Linux命令类型: 内置命令(shell内置):cd is shell builtin 外部命令:命令 is /usr/bin/命令,在文件系统的某个路径下有一个与命令名称相应的可执行文件 type ...
- phpStudy环境下composer的安装
前言 原来是做php开发的,现在转行前端工程师,因为很久没有接触了,可能会有其他问题,这里简单记录一下,后期遇到什么问题再进行更新~ 话说下载特别慢所以这里给个网盘链接Composer-Setup.e ...
- Java-五种线程池,四种拒绝策略,三种阻塞队列(转)
Java-五种线程池,四种拒绝策略,三种阻塞队列 三种阻塞队列: BlockingQueue<Runnable> workQueue = null; workQueue = n ...
- jpa单向一对多
单向一对多是一个类中的一条记录可对应另一个类的多条记录: 比如一个部门可对应多个员工: jpa中的实现步骤: one-to-many的one类中添加一个many类类型的set;比如部门类D ...
- web文件系统
在Web应用系统开发中,文件上传和下载功能是非常常用的功能,今天来讲一下JavaWeb中的文件上传和下载功能的实现. 先说下要求: PC端全平台支持,要求支持Windows,Mac,Linux 支持所 ...
- vue-cli3的vue.config.js文件配置,生成dist文件
//vue.config.jsonconst path = require('path'); // const vConsolePlugin = require('vconsole-webpack-p ...
- vue-cli3中axios如何跨域请求以及axios封装
1. vue.config.js中配置如下 module.exports = { // 选项... // devtool: 'eval-source-map',//开发调试 devServer: { ...
- Android中关于回调概念的笔记
一.回调函数 回调函数就是一个通过函数指针调用的函数.如果你把函数的指针(地址)作为参数传递给另一个函数,当这个指针被用为调用它所指向的函数时,我们就说这是回调函数.回调函数不是由该函数的实现方直接调 ...