Python之scrapy linkextractors使用错误
1.环境及版本
python3.7.1+scrapy1.5.1
2.问题及错误代码详情
优先贴上问题代码,如下:
import scrapy
from scrapy.linkextractors import LinkExtractor class MatExamplesSpider(scrapy.Spider):
name = 'mat_examples'
# allowed_domains = ['matplotlib.org']
start_urls = ['https://matplotlib.org/gallery/index.html'] def parse(self, response):
le = LinkExtractor(restrict_xpaths='//a[contains(@class, "reference internal")]/@href')
links = le.extract_links(response)
print(response.url)
print(type(links))
print(links)
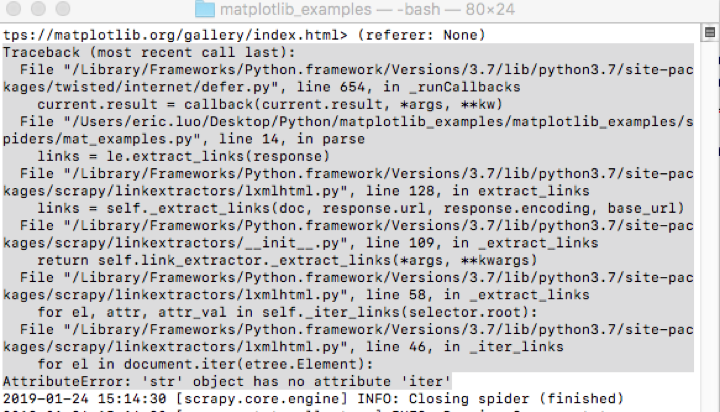
运行代码后报错如下:
Traceback (most recent call last):
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/twisted/internet/defer.py", line 654, in _runCallbacks
current.result = callback(current.result, *args, **kw)
File "/Users/eric.luo/Desktop/Python/matplotlib_examples/matplotlib_examples/spiders/mat_examples.py", line 14, in parse
links = le.extract_links(response)
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/scrapy/linkextractors/lxmlhtml.py", line 128, in extract_links
links = self._extract_links(doc, response.url, response.encoding, base_url)
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/scrapy/linkextractors/__init__.py", line 109, in _extract_links
return self.link_extractor._extract_links(*args, **kwargs)
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/scrapy/linkextractors/lxmlhtml.py", line 58, in _extract_links
for el, attr, attr_val in self._iter_links(selector.root):
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/scrapy/linkextractors/lxmlhtml.py", line 46, in _iter_links
for el in document.iter(etree.Element):
AttributeError: 'str' object has no attribute 'iter'
出现错误后自检代码并未发现问题,上网查找也未发现相关的问题;于是将代码改成(restrict_css)去抓取数据,发现是能正常获取到数据的,于是改回xpath;但这次先不使用linkextractor,采用scrapy自带的response.xpath()方法去获取对应链接所在标签的href属性值;发现这样是可以获取到正常的数据的:
即将:
le = LinkExtractor(restrict_xpaths='//a[contains(@class, "reference internal")]/@href')
links = le.extract_links(response)
改成:
links = respon.xpath(‘//a[contains(@class, "reference internal")]/@href').extract()
然后又发现报错是: 'str' object has no attribute 'iter'
而正常返回的links数据类型应该是list才对,不应该是str,所以猜测可能是由于规则写错了导致获取的数据不是list而变成了一个不知道的str;这样针对性的去修改restrict_xpaths中的规则,最后发现去掉/@href后能够获取我所需要的正常的数据;
即将:
le = LinkExtractor(restrict_xpaths='//a[contains(@class, "reference internal")]/@href')
改成:
le = LinkExtractor(restrict_xpaths='//a[contains(@class, "reference internal")]')
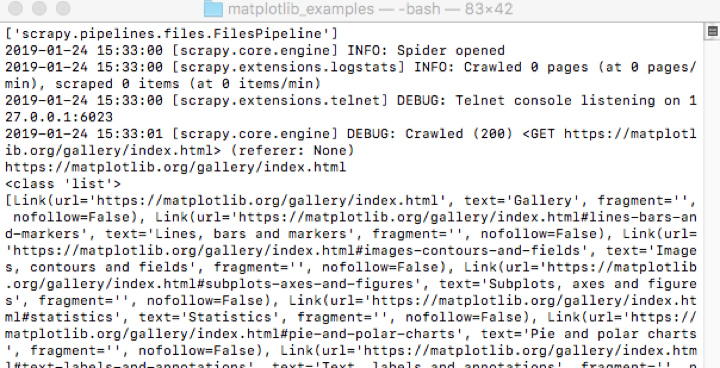
重新运行代码,发现成功获取数据,输出结果如下截图所示:
*****爬虫初学者,不喜勿喷*****
Python之scrapy linkextractors使用错误的更多相关文章
- Python之Scrapy爬虫框架安装及简单使用
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提 ...
- [Python爬虫] scrapy爬虫系列 <一>.安装及入门介绍
前面介绍了很多Selenium基于自动测试的Python爬虫程序,主要利用它的xpath语句,通过分析网页DOM树结构进行爬取内容,同时可以结合Phantomjs模拟浏览器进行鼠标或键盘操作.但是,更 ...
- python爬虫scrapy框架
Scrapy 框架 关注公众号"轻松学编程"了解更多. 一.简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量 ...
- python之scrapy框架基础搭建
一.创建工程 #在命令行输入scrapy startproject xxx #创建项目 二.写item文件 #写需要爬取的字段名称 name = scrapy.Field() #例 三.进入spide ...
- Python:Scrapy(三) 进阶:额外的一些类ItemLoader与CrawlSpider,使用原理及总结
学习自:Python Scrapy 爬虫框架实例(一) - Blue·Sky - 博客园 这一节是对前两节内容的补充,涉及内容为一些额外的类与方法,来对原代码进行改进 原代码:这里并没有用前两节的代码 ...
- Python爬虫Scrapy框架入门(0)
想学习爬虫,又想了解python语言,有个python高手推荐我看看scrapy. scrapy是一个python爬虫框架,据说很灵活,网上介绍该框架的信息很多,此处不再赘述.专心记录我自己遇到的问题 ...
- dota玩家与英雄契合度的计算器,python语言scrapy爬虫的使用
首发:个人博客,更新&纠错&回复 演示地址在这里,代码在这里. 一个dota玩家与英雄契合度的计算器(查看效果),包括两部分代码: 1.python的scrapy爬虫,总体思路是pag ...
- python爬虫scrapy框架——人工识别登录知乎倒立文字验证码和数字英文验证码(2)
操作环境:python3 在上一文中python爬虫scrapy框架--人工识别知乎登录知乎倒立文字验证码和数字英文验证码(1)我们已经介绍了用Requests库来登录知乎,本文如果看不懂可以先看之前 ...
- python爬虫Scrapy(一)-我爬了boss数据
一.概述 学习python有一段时间了,最近了解了下Python的入门爬虫框架Scrapy,参考了文章Python爬虫框架Scrapy入门.本篇文章属于初学经验记录,比较简单,适合刚学习爬虫的小伙伴. ...
随机推荐
- C语言之基本算法40—字符串删除元音字母倒序输出
//字符串,数组 /* ================================================================== 题目: 输入一行字符,将辅音字母按反序输出 ...
- [面试题]java中final finally finalized 的差别是什么?
final 是修饰符,能够用于修饰变量.方法和类.修饰变量时.代表变量不能够改动,也就是常量了.常量须要在定义时赋值或通过构造函数赋值,两者仅仅能选其一:修饰方法时,代表方法仅仅能调用,不能被 ove ...
- commons-fileupload上传文件(1)
近期,写一个上传图片的功能.于是用到commons-fileupload这个组件.提过form提交表单到后台(这里没实用到structs框架).在后台List pl = dfu.parseReques ...
- stack 栈
其实今天我们主要讲的是搜索,但是留作业不知道怎么就突然全变成栈了. 其实栈和队列没什么区别,只是一个先进先出,一个先进后出.基本操作也是一样的. 栈(stack)又名堆栈,它是一种运算受限的线性表.其 ...
- 杂项:ESB接口
ylbtech-杂项:ESB接口 ESB全称为Enterprise Service Bus,即企业服务总线.它是传统中间件技术与XML.Web服务等技术结合的产物.ESB提供了网络中最基本的连接中枢, ...
- Truck History(prim)
http://poj.org/problem?id=1789 读不懂题再简单也不会做,英语是硬伤到哪都是真理,sad++. 此题就是一个最小生成树,两点之间的权值是毎两串之间的不同字母数. #incl ...
- python-day01 pip 在线安装,标识符规则,注释,变量名,类型
1.python第三方库安装: 在线安装:pip install 库名 pip install 库名 -i 国内源网站地址 离线安装:xxx.tar.gz/rar/zip 解压安装 2.标识符规则: ...
- Vue Element-ui table只展开一行
直接上代码了哈~ <template> <div class="app-content"> <div class="table_expand ...
- 【BZOJ4590】自动刷题机
[思路分析] 比赛的时候想到了用二分+贪心,二分的部分与贪心的部分也写对了,但是由于数据范围未看没有开long long,且二分左端点赋值过小导致WA掉 正解:二分+贪心 二分代码的长度,贪心判断能否 ...
- 智能识别快递地址api接口实现(PHP示例)
电商.ERP等行业发货时,批量录入图片上的收件人地址是个难题:智能识别收件人API是近乎完美的解决方案,通过识别图片,解析出图片中收件人的姓名.电话.详细地址(省.市.区/县.详细地址).将此接口集成 ...