urllib2使用总结
keywords:
- urllib2,BeautifulSoup,cookielib
题外话:
小弟是编程爱好者,各位看官轻拍。
最近在使用urllib2抓取网页内容,在学习的过程中也查阅了不少资料,并从中收获很多。在查阅资料的过程中,我发现大部分资料都是建立在对urllib2的熟悉基础之上,程序的细节并未顾及到新手看到这份资料会产生怎样的困惑。在接下来的内容中,我会写到我碰到的疑问以及解决方法。如果你也碰到类似的困惑,希望给予你帮助。
一.urllib2简介
urllib2提供一个基础函数urlopen,通过向指定的URL发出请求来获取数据。最简单的形式就是
- import urllib2
- response=urllib2.urlopen('http://www.douban.com')
- html=response.read()
这个过程就是我们平时刷网页的代码表现形式,它基于请求-响应模型。
- response=urllib2.urlopen('http://www.douban.com')
实际上可以看作两个步骤:
我们指定一个域名并发送请求
1.
- request=urllib2.request('http://www.douban.com')
接着服务端响应来自客户端的请求
2.
- response=urllib2.urlopen(request)
也许你会注意到,我们平时除了刷网页的操作,还有向网页提交数据。这种提交数据的行为,urllib2会把它翻译为:
- import urllib
- import urllib2
- url = 'http://www.douban.com'
- info = {'name' : 'Michael Foord',
- 'location' : 'Northampton'}
- data = urllib.urlencode(info) #info 需要被编码为urllib2能理解的格式,这里用到的是urllib
- req = urllib2.Request(url, data)
- response = urllib2.urlopen(req)
- the_page = response.read()
有时你会碰到,程序也对,但是服务器拒绝你的访问。这是为什么呢?问题出在请求中的头信息(header)。
有的服务端有洁癖,不喜欢程序来触摸它。这个时候你需要将你的程序伪装成浏览器来发出请求。请求的方式就包含在header中。
常见的情形:
- import urllib
- import urllib2
- url = 'http://www.someserver.com/cgi-bin/register.cgi'
- user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'# 将user_agent写入头信息
- values = {'name' : 'Michael Foord',
- 'location' : 'Northampton',
- 'language' : 'Python' }
- headers = { 'User-Agent' : user_agent }
- data = urllib.urlencode(values)
- req = urllib2.Request(url, data, headers)
- response = urllib2.urlopen(req)
- the_page = response.read()
二.示例
模拟一个利用cookie登录人人网的过程 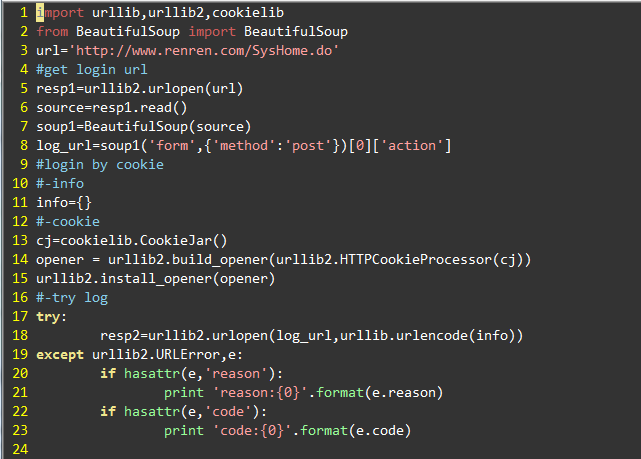
2012-03-07 21:34 上传
说明:
1.人人网的登录地址需要用BeautifulSoup来抓取。
2.个人信息存在info中。info是一个字典{'email':'xx','password':'xx'}.key的命名需要根据实际网页中定义,比如豆瓣的定义是{'form_email':'xx','form_password':'xx'}
3.使用cookie的好处在于,登录之后你可以使用cookie中保存的信息作为头信息的一部分,利用已经保存的头信息接着访问网站。
参考:
HOWTO Fetch Internet Resources Using urllib2
Beautiful Soup 中文文档
How to use Python to login to a webpage and retrieve cookies for later usage?
urllib2使用总结的更多相关文章
- 【Python网络爬虫二】使用urllib2抓去网页内容
在Python中通过导入urllib2组件,来完成网页的抓取工作.在python3.x中被改为urllib.request. 爬取具体的过程类似于使用程序模拟IE浏览器的功能,把URL作为HTTP请求 ...
- Python urllib2 调试
#!/usr/bin/env python # coding=utf-8 __author__ = 'zhaoyingnan' import urllib import urllib2 import ...
- 使用urllib2打开网页的三种方法
#coding:utf-8 import urllib2 import cookielib url="http://www.baidu.com" print '方法 1' resp ...
- No module named 'urllib2'
import urllib2 response = urllib2.urlopen('http://www.baidu.com/') html = response.read() print html ...
- Python自动化测试 (九)urllib2 发送HTTP Request
urllib2 是Python自带的标准模块, 用来发送HTTP Request的. 类似于 .NET中的, HttpWebRequest类 urllib2 的优点 Python urllib2 ...
- urllib2抓取HTML存入Excel
通过urllib2抓取HTML网页,然后过滤出包含特定字符的行,并写入Excel文件: # -*- coding: utf-8 -*- import sys #import urllib import ...
- [Python] urllib2.HTTPError: HTTP Error 403: Forbidden
搬运自http://www.2cto.com/kf/201309/242273.html,感谢原作. 之所以出现上面的异常,是因为如果用 urllib.request.urlopen 方式打开一个UR ...
- python urllib2 发起http请求post
使用urllib2发起post请求 def GetCsspToken(): data = json.dumps({"userName":"wenbin", &q ...
- cookielib和urllib2模块相结合模拟网站登录
1.cookielib模块 cookielib模块的主要作用是提供可存储cookie的对象,以便于与urllib2模块配合使用来访问Internet资源.例如可以利用 本模块的CookieJar类的对 ...
- 使用python标准库urllib2访问网页
#访问不需要登录的网页import urllib2target_page_url='http://10.224.110.118/myweb/view.jsp' f = urllib2.urlopen( ...
随机推荐
- php实现Bloom Filter
Bloom Filter(BF) 是由Bloom在1970年提出的一种多哈希函数映射的高速查找算法,用于高速查找某个元素是否属于集合, 但不要求百分百的准确率. Bloom filter通经常使用于爬 ...
- 我的嵌入式Qt开发第一课——基于BBB和hmc5843三轴电子罗盘
几次想照着课本系统地学习Qt,但我发现还是有详细问题驱动时学习比較快. 于是我给自己设定了这个任务: 读取HMC5843的三轴磁场强度值,计算出角度,并把角度用直观形式显示在图形界面上. 这里面涉及到 ...
- Lucene学习总结之七:Lucene搜索过程解析 2014-06-25 14:23 863人阅读 评论(1) 收藏
一.Lucene搜索过程总论 搜索的过程总的来说就是将词典及倒排表信息从索引中读出来,根据用户输入的查询语句合并倒排表,得到结果文档集并对文档进行打分的过程. 其可用如下图示: 总共包括以下几个过程: ...
- 驱动程序调试方法之printk——自制proc文件(一)
首先我们需要弄清楚proc机制,来看看fs/proc/proc_misc.c这个文件,从入口函数开始看: proc_misc_init(void) #ifdef CONFIG_PRIN ...
- #ifdef 的使用
1. _DEBUG #ifdef DEBUG的理解 首先需要注意的是,只有当前项目工作在 Debug(调试模式)(而不是Release(发布))设置下时编译器提供的宏定义.对于 visual stud ...
- js实现计时功能
原文链接:https://blog.csdn.net/qq_37936542/article/details/78912786 一:计时器功能 <!DOCTYPE html> <ht ...
- C++对象模型——对象成员的效率 (Object Member Efficiency)(第三章)
3.5 对象成员的效率 (Object Mem ber Efficiency) 以下某个測试,目的在測试聚合(aggregation).封装(encapsulation),以及继承(Inheritan ...
- 基于 Android NDK 的学习之旅-----HelloWorld
Hello World作为所有编程语言的起始阶段,占据着无法改变的地位,所有中/英/法/德/美……版本的编程教材中,hello world总是作为第一个TEST记录于书本之中,所有的编程第一步就在于此 ...
- Mysql存储过程中使用cursor
一.表 学生表 CREATE TABLE `t_student` ( `stuNum` int(11) NOT NULL auto_increment, `stuName` varchar ...
- [Angular] @ContentChild and ngAfterContentInit
@ContentChild normally works with ngAfterContentInit lifecycle. @ContentChild is used for looking in ...