zk分布式任务管理
在我们的系统开发过程 中不可避免的会使用到定时任务的功能,而当我们在生产环境部署的服务超过1台时,就需要考虑任务调度的问题,防止两台或多台服务器上执行同一个任务,这个问题今天咱们就用zookeeper来解决。
zookeeper的存储模型
Zookeeper的数据存储采用的是结构化存储,结构化存储是没有文件和目录的概念,里边的目录和文件被抽象成了节点(node),zookeeper里可以称为znode。Znode的层次结构如下图:
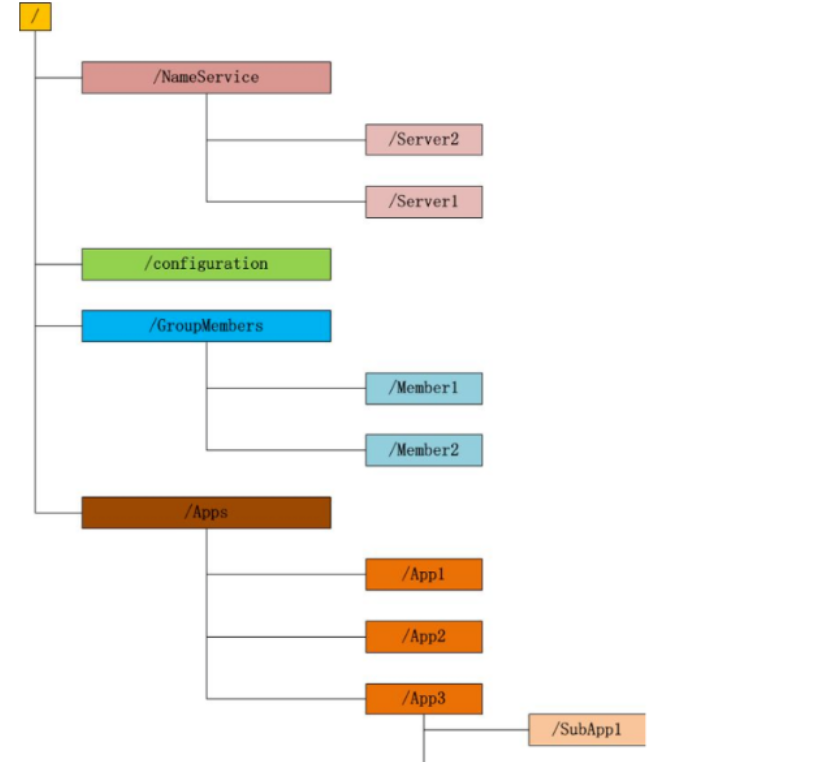
每个子目录项如 NameService 都被称作为 znode(目录节点),和文件系统一样,我们能够自由的增加、删除znode,在一个znode下增加、删除子znode,唯一的不同在于znode是可以存储数据的。
znode类型
PERSISTENT-持久化目录节点
客户端与zookeeper断开连接后,该节点依旧存在
PERSISTENT_SEQUENTIAL-持久化顺序编号目录节点
客户端与zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号
EPHEMERAL-临时目录节点
客户端与zookeeper断开连接后,该节点被删除
EPHEMERAL_SEQUENTIAL-临时顺序编号目录节点
客户端与zookeeper断开连接后,该节点被删除,只是Zookeeper给该节点名称进行顺序编号
监听通知机制
客户端注册监听它关心的目录节点,当目录节点发生变化(数据改变、被删除、子目录节点增加删除)时,zookeeper会通知客户端。基于这种监听,可以实现注册中心、分布式同步等功能。
zk分布式任务管理机制
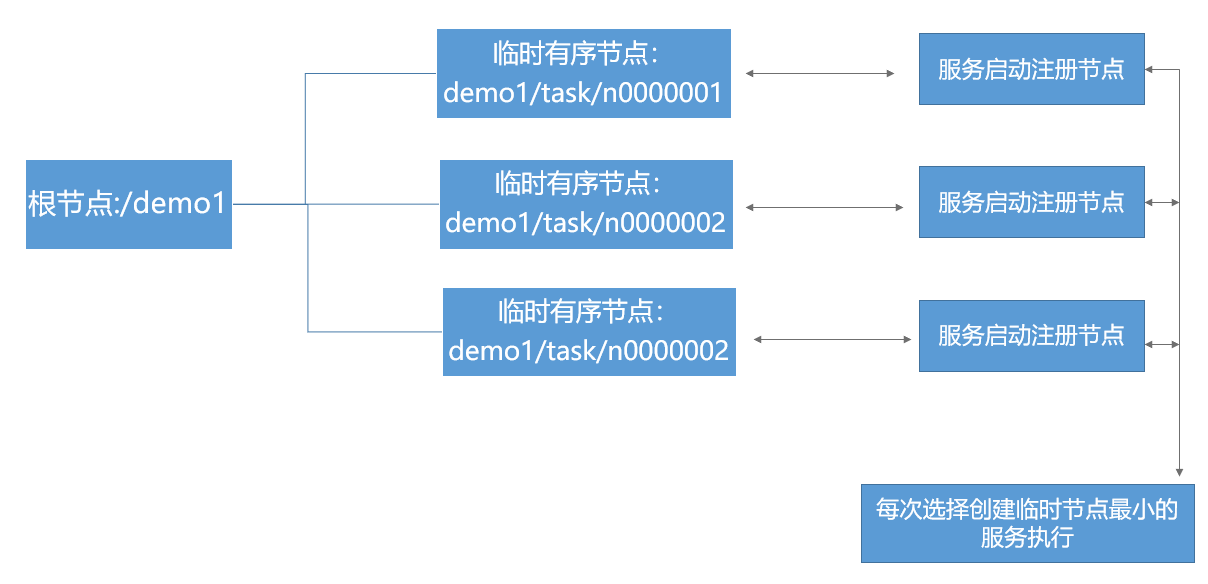
使用zookeeper的临时顺序节点,来实现分布式任务的调度功能,每一台服务启动的时候都向zookeepe指定的目录下注册一下临时顺序节点,并把该节点记录的系统里,每一次任务执行的时候,获取所有的有序节点,跟当前系统创爱你的节点对比,如果当前服务创建的节点是所有节点中最小的,则执行任务,否则不执行任务,如下如所示:
代码实现
1、pom引用
<zookeeper.version>3.4.8</zookeeper.version>
<curator.version>2.11.1</curator.version> <dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>${zookeeper.version}</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>${curator.version}</version>
</dependency>
2、ZkClient类
该类封装了zookeeper的操作类,服务启动的时候回向zk上注册有序临时节点,目录为:/demo1/task/n,例如:/demo1/task/n00000001,/demo1/task/n00000002,创建的节点路径保存到变量:curTaskNodeId
package com.blogs.client; import java.util.ArrayList;
import java.util.Collection;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit; import org.apache.curator.RetryPolicy;
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.framework.CuratorFrameworkFactory.Builder;
import org.apache.curator.framework.api.ACLProvider;
import org.apache.curator.framework.recipes.cache.ChildData;
import org.apache.curator.framework.recipes.cache.TreeCache;
import org.apache.curator.framework.recipes.cache.TreeCacheListener;
import org.apache.curator.framework.recipes.locks.InterProcessMutex;
import org.apache.curator.framework.recipes.locks.InterProcessReadWriteLock;
import org.apache.curator.framework.state.ConnectionState;
import org.apache.curator.framework.state.ConnectionStateListener;
import org.apache.curator.retry.ExponentialBackoffRetry;
import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.ZooDefs;
import org.apache.zookeeper.data.ACL;
import org.springframework.stereotype.Component; import lombok.Data;
import lombok.extern.slf4j.Slf4j; @Component
@Slf4j
@Data
public class ZkClient {
private CuratorFramework client;
public TreeCache cache;
//记录当前服务在zk上创建的nodeId
public String curTaskNodeId="";
//private ZookeeperProperties zookeeperProperties; public ZkClient(){
init();
} /**
* 初始化zookeeper
*/
public void init(){
try {
//初始sleep时间 ,毫秒,
int baseSleepTimeMs=1000;
//最大重试次数
int maxRetries=3;
RetryPolicy retryPolicy = new ExponentialBackoffRetry(baseSleepTimeMs,maxRetries);
Builder builder = CuratorFrameworkFactory.builder()
.connectString("127.0.0.1:2181").retryPolicy(retryPolicy)
.sessionTimeoutMs( 1000) //会话超时时间,单位为毫秒,默认60000ms,连接断开后,其它客户端还能请到临时节点的时间
.connectionTimeoutMs( 6000)//连接创建超时时间,单位为毫秒
.namespace( "demo1");//zk的根节点
//以下注释的为创建节点的用户名密码
//builder.authorization("digest", "rt:rt".getBytes("UTF-8"));
/*
builder.aclProvider(new ACLProvider() {
@Override
public List<ACL> getDefaultAcl() {
return ZooDefs.Ids.CREATOR_ALL_ACL;
} @Override
public List<ACL> getAclForPath(final String path) {
return ZooDefs.Ids.CREATOR_ALL_ACL;
}
});*/
client = builder.build();
client.start(); client.getConnectionStateListenable().addListener(new ConnectionStateListener() {
public void stateChanged(CuratorFramework client, ConnectionState state) {
if (state == ConnectionState.LOST) {
//连接丢失
log.info("lost session with zookeeper");
} else if (state == ConnectionState.CONNECTED) {
//连接新建
log.info("connected with zookeeper");
} else if (state == ConnectionState.RECONNECTED) {
log.info("reconnected with zookeeper");
}
}
});
System.out.println("zk初始化完成");
//获取当前服务启动时创建的节点,临时有序节点,用作定时任务的执行
curTaskNodeId=createNode(CreateMode.EPHEMERAL_SEQUENTIAL,"/task/n",""); } catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
}
} public void stop() {
client.close();
} public CuratorFramework getClient() {
return client;
}
/**
* 创建节点
* @param mode 节点类型
* 1、PERSISTENT 持久化目录节点,存储的数据不会丢失。
* 2、PERSISTENT_SEQUENTIAL顺序自动编号的持久化目录节点,存储的数据不会丢失
* 3、EPHEMERAL临时目录节点,一旦创建这个节点的客户端与服务器端口也就是session 超时,这种节点会被自动删除
*4、EPHEMERAL_SEQUENTIAL临时自动编号节点,一旦创建这个节点的客户端与服务器端口也就是session 超时,这种节点会被自动删除,并且根据当前已近存在的节点数自动加 1,然后返回给客户端已经成功创建的目录节点名。
* @param path 节点名称
* @param nodeData 节点数据
*/
public String createNode(CreateMode mode, String path , String nodeData) {
String nodepath="";
try {
//使用creatingParentContainersIfNeeded()之后Curator能够自动递归创建所有所需的父节点
nodepath = client.create().creatingParentsIfNeeded().withMode(mode).forPath(path,nodeData.getBytes("UTF-8"));
System.out.println(nodepath);
} catch (Exception e) {
log.error("注册出错", e);
}
return nodepath;
} /**
* 创建节点
* @param mode 节点类型
* 1、PERSISTENT 持久化目录节点,存储的数据不会丢失。
* 2、PERSISTENT_SEQUENTIAL顺序自动编号的持久化目录节点,存储的数据不会丢失
* 3、EPHEMERAL临时目录节点,一旦创建这个节点的客户端与服务器端口也就是session 超时,这种节点会被自动删除
* 4、EPHEMERAL_SEQUENTIAL临时自动编号节点,一旦创建这个节点的客户端与服务器端口也就是session 超时,这种节点会被自动删除,并且根据当前已近存在的节点数自动加 1,然后返回给客户端已经成功创建的目录节点名。
* @param path 节点名称
*/
public void createNode(CreateMode mode,String path ) {
try {
//使用creatingParentContainersIfNeeded()之后Curator能够自动递归创建所有所需的父节点
client.create().creatingParentsIfNeeded().withMode(mode).forPath(path);
} catch (Exception e) {
log.error("注册出错", e);
}
} /**
* 删除节点数据
*
* @param path
*/
public void deleteNode(final String path) {
try {
deleteNode(path,true);
} catch (Exception ex) {
log.error("{}",ex);
}
} /**
* 删除节点数据
* @param path
* @param deleteChildre 是否删除子节点
*/
public void deleteNode(final String path,Boolean deleteChildre){
try {
if(deleteChildre){
//guaranteed()删除一个节点,强制保证删除,
// 只要客户端会话有效,那么Curator会在后台持续进行删除操作,直到删除节点成功
client.delete().guaranteed().deletingChildrenIfNeeded().forPath(path);
}else{
client.delete().guaranteed().forPath(path);
}
} catch (Exception e) {
e.printStackTrace();
}
} /**
* 设置指定节点的数据
* @param path
* @param datas
*/
public void setNodeData(String path, byte[] datas){
try {
client.setData().forPath(path, datas);
}catch (Exception ex) {
log.error("{}",ex);
}
} /**
* 获取指定节点的数据
* @param path
* @return
*/
public byte[] getNodeData(String path){
Byte[] bytes = null;
try {
if(cache != null){
ChildData data = cache.getCurrentData(path);
if(data != null){
return data.getData();
}
}
client.getData().forPath(path);
return client.getData().forPath(path);
}catch (Exception ex) {
log.error("{}",ex);
}
return null;
} /**
* 获取数据时先同步
* @param path
* @return
*/
public byte[] synNodeData(String path){
client.sync();
return getNodeData( path);
} /**
* 判断路径是否存在
*
* @param path
* @return
*/
public boolean isExistNode(final String path) {
client.sync();
try {
return null != client.checkExists().forPath(path);
} catch (Exception ex) {
return false;
}
} /**
* 获取节点的子节点
* @param path
* @return
*/
public List<String> getChildren(String path) {
List<String> childrenList = new ArrayList<>();
try {
childrenList = client.getChildren().forPath(path);
} catch (Exception e) {
log.error("获取子节点出错", e);
}
return childrenList;
} /**
* 随机读取一个path子路径, "/"为根节点对应该namespace
* 先从cache中读取,如果没有,再从zookeeper中查询
* @param path
* @return
* @throws Exception
*/
public String getRandomData(String path) {
try{
Map<String,ChildData> cacheMap = cache.getCurrentChildren(path);
if(cacheMap != null && cacheMap.size() > 0) {
log.debug("get random value from cache,path="+path);
Collection<ChildData> values = cacheMap.values();
List<ChildData> list = new ArrayList<>(values);
Random rand = new Random();
byte[] b = list.get(rand.nextInt(list.size())).getData();
return new String(b,"utf-8");
}
if(isExistNode(path)) {
log.debug("path [{}] is not exists,return null",path);
return null;
} else {
log.debug("read random from zookeeper,path="+path);
List<String> list = client.getChildren().forPath(path);
if(list == null || list.size() == 0) {
log.debug("path [{}] has no children return null",path);
return null;
}
Random rand = new Random();
String child = list.get(rand.nextInt(list.size()));
path = path + "/" + child;
byte[] b = client.getData().forPath(path);
String value = new String(b,"utf-8");
return value;
}
}catch(Exception e){
log.error("{}",e);
}
return null; } /**
* 获取读写锁
* @param path
* @return
*/
public InterProcessReadWriteLock getReadWriteLock(String path){
InterProcessReadWriteLock readWriteLock = new InterProcessReadWriteLock(client, path);
return readWriteLock;
} /**
* 在注册监听器的时候,如果传入此参数,当事件触发时,逻辑由线程池处理
*/
ExecutorService pool = Executors.newFixedThreadPool(2); /**
* 监听数据节点的变化情况
* @param watchPath
* @param listener
*/
public void watchPath(String watchPath,TreeCacheListener listener){
// NodeCache nodeCache = new NodeCache(client, watchPath, false);
TreeCache cache = new TreeCache(client, watchPath);
cache.getListenable().addListener(listener,pool);
try {
cache.start();
} catch (Exception e) {
e.printStackTrace();
}
} }
3、定时任务调用
package com.blogs.client; import java.time.LocalDateTime;
import java.util.List; import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.scheduling.annotation.EnableScheduling;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component; @Component
@EnableScheduling
public class ScheduleTask { @Autowired
private ZkClient zkClient; //添加定时任务
@Scheduled(cron = "0/5 * * * * ?")
private void configureTasks() {
System.out.println("开始执行任务");
//获取所有节点
List<String> taskNodes=zkClient.getChildren("/task");
//查找最小节点
int minNodeNum=Integer.MAX_VALUE;
for (int i = 0; i < taskNodes.size(); i++) {
//节点前面有一个n,把n替换掉,剩下的转换为数字
int nodeNum=Integer.valueOf(taskNodes.get(i).replace("n", ""));
if(nodeNum < minNodeNum){
minNodeNum = nodeNum;
}
System.out.println("节点:"+taskNodes.get(i));
}
System.out.println("当前节点:"+zkClient.getCurTaskNodeId());
//如果最小节点 等于该服务创建的节点,则执行任务
int curNodeNum=Integer.valueOf(zkClient.getCurTaskNodeId().substring(zkClient.getCurTaskNodeId().lastIndexOf('/') + 2));
if(minNodeNum - curNodeNum == 0){
System.out.println("执行任务");
}else {
System.out.println("不执行任务");
} System.err.println("执行静态定时任务时间: " + LocalDateTime.now());
}
}
当前服务创建的服务为节点最小的,则执行服务,否则不执行服务
执行结果
把服务的端口分别修改为:8080,8081,模拟启动两个服务,查看定时任务的执行情况

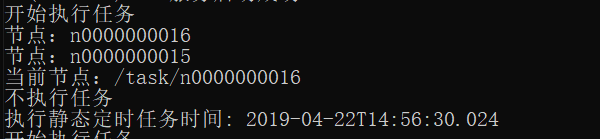
当把两个服务的任何一个服务关闭,定时任务还可以正常执行。
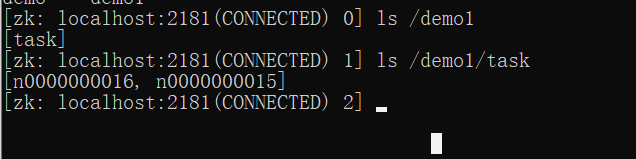
zkCli查看查创建的目录结构
出处:https://www.cnblogs.com/lc-chenlong
如果喜欢作者的文章,请关注“写代码的猿”订阅号以便第一时间获得最新内容。本文版权归作者所有,欢迎转载

zk分布式任务管理的更多相关文章
- 本地锁、redis分布式锁、zk分布式锁
本地锁.redis分布式锁.zk分布式锁 https://www.cnblogs.com/yjq-code/p/dotnetlock.html 为什么要用锁? 大型站点在高并发的情况下,为了保持数据最 ...
- 2020-05-24:ZK分布式锁有几种实现方式?各自的优缺点是什么?
福哥答案2020-05-24: Zk分布式锁有两种实现方式一种比较简单,应对并发量不是很大的情况.获得锁:创建一个临时节点,比如/lock,如果成功获得锁,如果失败没获得锁,返回false释放锁:删除 ...
- 【分布式锁的演化】终章!手撸ZK分布式锁!
前言 这应该是分布式锁演化的最后一个章节了,相信很多小伙伴们看完这个章节之后在应对高并发的情况下,如何保证线程安全心里肯定也会有谱了.在实际的项目中也可以参考一下老猫的github上的例子,当然代码没 ...
- 【zookeeper】Apache curator的使用及zk分布式锁实现
上篇,本篇主要讲Apache开源的curator的使用,有了curator,利用Java对zookeeper的操作变得极度便捷. 其实在学之前我也有个疑虑,我为啥要学curator,撇开涨薪这些外在的 ...
- .net下 本地锁、redis分布式锁、zk分布式锁的实现
为什么要用锁? 大型站点在高并发的情况下,为了保持数据最终一致性就需要用到技术方案来支持.比如:分布式锁.分布式事务.有时候我们在为了保证某一个方法每次只能被一个调用者使用的时候,这时候我们也可以锁来 ...
- dubbo zk 分布式服务项目搭建与配置
1. 项目 jar -----提供接口 2. 项目 jar -----接口实现 provider启动zk main方法启动 start applicationContext.xml <b ...
- Quart.Net分布式任务管理平台
无关主题:一段时间没有更新文章了,与自己心里的坚持还是背驰,虽然这期间在公司做了统计分析,由于资源分配问题,自己或多或少的原因,确实拖得有点久了,自己这段时间也有点松懈,借口就不说那么多 ...
- Quart.Net分布式任务管理平台(续)
感谢@Taking园友得建议,我这边确实多做了一步上传,导致后面还需处理同步上传到其他服务器来支持分布式得操作.所有才有了上篇文章得完善. 首先看一下新的项目结构图: 这个图和上篇文章中 ...
- Quartz.Net分布式任务管理平台(第二版)
前言:在Quartz.Net项目发布第一版后,有挺多园友去下载使用,我们通过QQ去探讨,其中项目中还是存在一定的不完善.所以有了现在这个版本.这个版本的编写完成其实有段时间了一直没有放上去.现在已经同 ...
随机推荐
- C++中的内联函数和C中的宏定义的区别
在C++中内联函数: 内联函数即是在函数的声明和和定义前面加上“inline”关键字,内联函数和常规函数一样,都是按照值来传递参数的,如果参数为表达式,如4.5+7.5,则函数将传递表达式的值(这里为 ...
- 【NOIP2011】 聪明的质监员
小 T 是一名质量监督员,最近负责检验一批矿产的质量.这批矿产共有n个矿石,从 1 到n逐一编号,每个矿石都有自己的重量wi以及价值vi.检验矿产的流程是: 1. 给定 m个区间[Li,Ri]: 2. ...
- 【莫比乌斯反演】BZOJ2820 YY的GCD
Description 求有多少对(x,y)的gcd为素数,x<=n,y<=m.n,m<=1e7,T<=1e4. Solution 因为题目要求gcd为素数的,那么我们就只考虑 ...
- BZOJ_2743_[HEOI2012]采花_离线+树状数组
BZOJ_2743_[HEOI2012]采花_离线+树状数组 Description 萧芸斓是Z国的公主,平时的一大爱好是采花.今天天气晴朗,阳光明媚,公主清晨便去了皇宫中新建的花园采花 .花园足够大 ...
- linux系统日志查看
系统 日志文件( 可以通过cat 或tail 命令来查看) /var/log/message 系统启动后的信息和错误日志,是Red Hat Linux中最常用的日志之一/var/log/secure ...
- python--装饰器(附偏函数、断言)
博客地址:http://www.cnblogs.com/yudanqu/ 概念:装饰器是一个闭包,把一个函数当做参数返回一个替代版的函数,本质上就是一个返回函数的函数 装饰器就是在我们需要的一个函数外 ...
- C# WinForm ShowInTaskbar Api Version
using System; using System.Runtime.InteropServices; namespace x { unsafe class NativeWindow { /* * W ...
- Navicat:实现两个数据库结构同步和数据库对比
Navicat版本:Navicat Premium 12 选择 工具 ——> 结构同步 选择源数据库和目标数据库,选择完成后点击右下角对比按钮 要修改的对象:源数据库和目标数据库中都有的 ...
- 《HelloGitHub》第 35 期
<HelloGitHub>第 35 期 兴趣是最好的老师,HelloGitHub 就是帮你找到兴趣! 简介 分享 GitHub 上有趣.入门级的开源项目. 这是一个面向编程新手.热爱编程. ...
- Asp.Net Core对接钉钉群机器人
钉钉作为企业办公越来越常用的软件,对于企业内部自研系统提供接口支持,以此来打通多平台下的数据,本次先使用最简单的钉钉群机器人完成多种形式的消息推送,参考钉钉开发文档中自定义机器人环节,此次尝试所花的时 ...