深度学习基础网络 ResNet
Highway Networks
论文地址:arXiv:1505.00387 [cs.LG] (ICML 2015),全文:Training Very Deep Networks( arXiv:1507.06228 )
基于梯度下降的算法在网络层数增加时训练越来越困难(并非是梯度消失的问题,因为batch norm解决梯度消失问题).论文受 RNN 中的 LSTM、GRU 的 gate 机制的启发,去掉每一层循环的序列输入,去掉 reset gate (不需要遗忘历史信息),仍使用 gate 控制前一次输出与当前层激活函数之后的输出的融合比例,从而提出了highway networks,加入了称为 information high-ways的shortcut连接,使得信息可以跨层直接原样传递.这使得网络深度理论上几乎可以是无限.
传统网络做的非线性转换(通常是仿射变换+非线性激活函数)是:
\]
highway network添加了两个非线性转换: transform gate \(T(x,W_T)\) ,carry gate \(C(x,W_C)\):
\]
令 \(C = 1 − T\),得到
\]
当\(T(x,W_T)=0\)时,\(y=x\);当\(T(x,W_T)=1\)时,\(y=H(x,W_H)\).因此这个gate可以灵活地控制网络的行为.直观的理解就是每层不完全做非线性特征变换了,将原始特征直接添加到这一层,更有弹性一些.
上边的公式(3)要求$x,y, H(x,W_H),T(x,W_T) $是相同的大小.对于大小不匹配的情况,采用对x 下采样/0值填充 的方式,另外还可使用额外的网络改变x的维度.
论文中设置\(T(x) = σ(W_T^Tx+b_T)∈ (0,1),∀x ∈ R\).
Highway network学习之后自动学习哪些层需要哪些不需要.而ResNet是直接(等比例)相加.
ResNet
论文(Deep Residual Learning for Image Recognition,CVPR 2016)
ResNet与Highway Networks的区别是Highway Networks增加了额外的参数,而ResNet不需要;Highway Networks,当carry gate接近于0时,残差功能接近关闭状态.而ResNet的残差函数总是开启.
ResNet 的动机是网络degradation退化问题,即传统网络随着层数增多,准确率不升反降.原因是当模型变复杂时,SGD的优化变得更加困难.
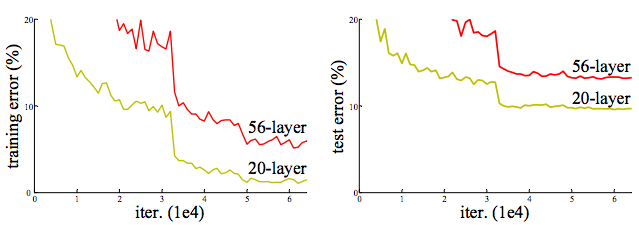
图 Cifar-10 上的training/testing error. 网络从20层加到56层,error却上升了。
优势:ResNet使用Identity mapping在不额外增加参数的情况下,收敛速度更快.
Identity mapping(恒等映射)
在网络中某一位置添加一条 shortcut connection,将前层的特征直接传递过来,这个新连接称为Identity mapping.如下图所示:
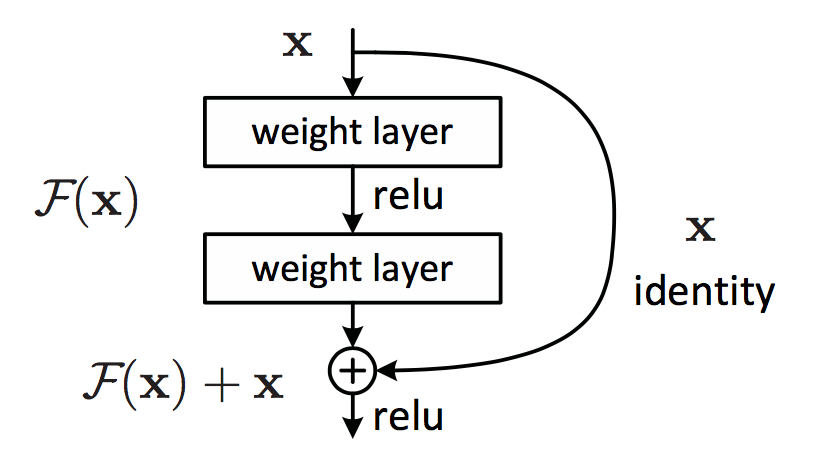
Identity mapping反向求导时正好是单位矩阵I.
假设优化残差映射F(x) 比优化原来的映射 H(x)容易(实验结果证实了这一点)。F(x)+x 可以通过 shortcut connections 来实现,如下图所示:
如果\(\mathbb x\)和\(\mathcal F\)的维度相同,那么:
\]
如果不相同,则需要对shortcut connection的x进行线性投射使维度相同,从而能够相加:
\]
加法操作作用的两个tensor具有相同的结构大小,在channel方向上将对应的feature map相加合并.
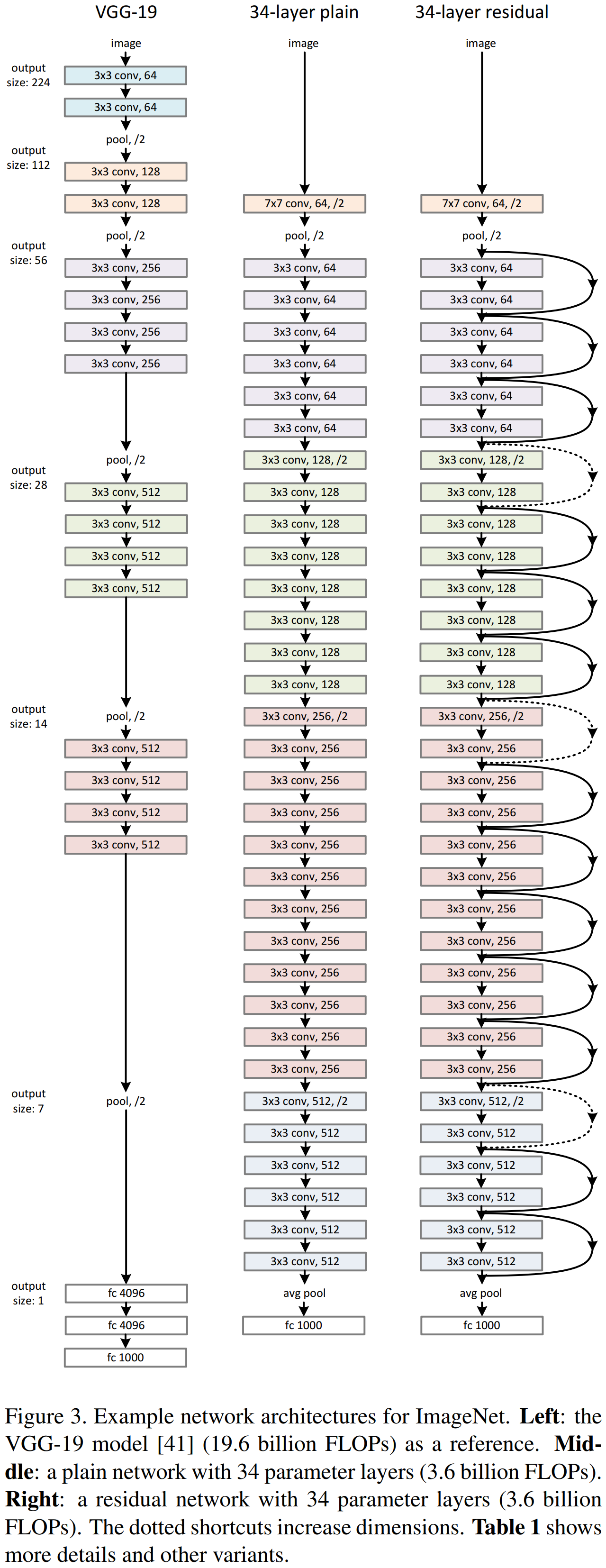
Plain Network
Plain Network 主要是受 VGG 网络启发,主要采用3x3滤波器,遵循两个设计原则:
- 输出相同特征图尺寸的卷积层,有相同个数的滤波器(stride=1使得输出尺寸不变)
- 通过stride=2降采样后特征图尺寸缩小一半,增加一倍的滤波器个数使每层卷积的计算复杂度相同(以特征图大小56->28为例,56的卷积操作数为(56x56x64)x(3x3x64),而64的卷积操作数为(28x28x128)x(3x3x128),计算量相等,当然stride=2的conv层计算量减半).
Residual Network
在 plain network 中加入 shortcut connections 构成了ResNet.对于shortcut的连接方式,论文提出了三个选项:
A. 使用恒等映射,如果residual block的输入输出维度不一致,对增加的维度用0来填充;
B. 在block输入输出维度一致时使用恒等映射,不一致时使用线性投影以保证维度一致(使用一层Conv+BatchNorm即可);
C. 对于所有的block均使用线性投影。
对这三个选项都进行了实验,发现虽然C的效果好于B的效果好于A的效果,但是差距很小,因此线性投影并不是必需的,而使用0填充时,可以保证模型的复杂度最低,这对于更深的网络是更加有利的。并且由于A方法不需要额外的参数,所以在层数较高时选择使用A.
Deeper Bottleneck结构:
对于更深的网络使用三层的残差结构,如下图所示,使用两个1x1的卷积先降维再增加维度,减少了3x3卷积层的个数及其输入输出维度,这个较小维度的3x3卷积即为bottleneck.图示的两种结构设计有相近的时间复杂度.
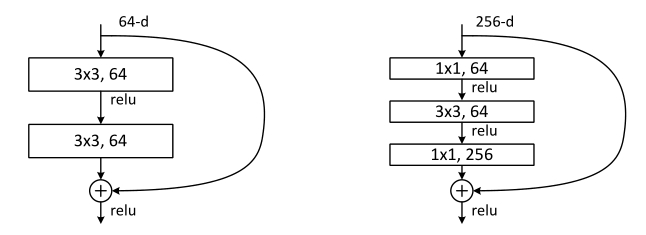
无参数的Identity shortcut对于bottleneck结构尤为重要,如果替换成有参数的投射,模型大小和复杂度将会增加.
论文中给出的18,34,50,101,152层网络如下表所示:
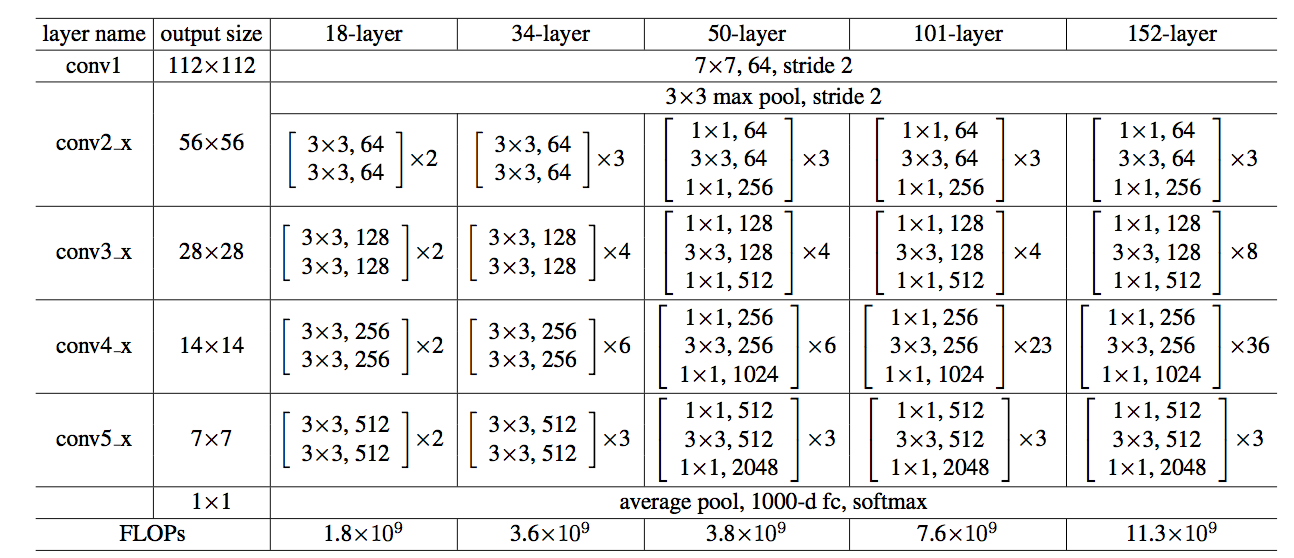
Plain Network,Residual Network与VGG-19的区别:
关于degradation
论文指出网络的退化不太可能是梯度消失造成的,因为网络中使用了BatchNorm层来保持信号的传播.具体原因尚不明确,需要后续研究.
实验发现通过更多的迭代次数(3x),仍然是degradation.
ResNet解读
参考论文作者另一篇论文Identity Mappings in Deep Residual Networks对ResNet的解读,
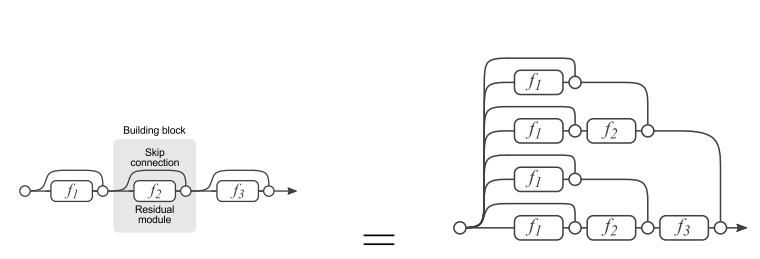
残差网络单元其中可以分解成右图的形式,从图中可以看出,残差网络其实是由多种路径组合的一个网络,直白了说,残差网络其实是很多并行子网络的组合,整个残差网络其实相当于一个多人投票系统(Ensembling)。
ResNet只是表面上看起来很深,事实上网络却很浅。
所示ResNet真的解决了深度网络的梯度消失的问题了吗?似乎没有,ResNet其实就是一个多人投票系统。
代码实现
caffe中实现特征的加法,用Eltwise层的SUM operation即可:
layer {
name: "Eltwise3"
type: "Eltwise"
bottom: "Eltwise2"
bottom: "Convolution7"
top: "Eltwise3"
eltwise_param {
operation: SUM
}
}
深度学习基础网络 ResNet的更多相关文章
- 深度学习基础系列(九)| Dropout VS Batch Normalization? 是时候放弃Dropout了
Dropout是过去几年非常流行的正则化技术,可有效防止过拟合的发生.但从深度学习的发展趋势看,Batch Normalizaton(简称BN)正在逐步取代Dropout技术,特别是在卷积层.本文将首 ...
- 算法工程师<深度学习基础>
<深度学习基础> 卷积神经网络,循环神经网络,LSTM与GRU,梯度消失与梯度爆炸,激活函数,防止过拟合的方法,dropout,batch normalization,各类经典的网络结构, ...
- 深度学习基础系列(五)| 深入理解交叉熵函数及其在tensorflow和keras中的实现
在统计学中,损失函数是一种衡量损失和错误(这种损失与“错误地”估计有关,如费用或者设备的损失)程度的函数.假设某样本的实际输出为a,而预计的输出为y,则y与a之间存在偏差,深度学习的目的即是通过不断地 ...
- [笔记] 基于nvidia/cuda的深度学习基础镜像构建流程 V0.2
之前的[笔记] 基于nvidia/cuda的深度学习基础镜像构建流程已经Out了,以这篇为准. 基于NVidia官方的nvidia/cuda image,构建适用于Deep Learning的基础im ...
- TensorFlow深度学习基础与应用实战高清视频教程
TensorFlow深度学习基础与应用实战高清视频教程,适合Python C++ C#视觉应用开发者,基于TensorFlow深度学习框架,讲解TensorFlow基础.图像分类.目标检测训练与测试以 ...
- 深度学习基础(CNN详解以及训练过程1)
深度学习是一个框架,包含多个重要算法: Convolutional Neural Networks(CNN)卷积神经网络 AutoEncoder自动编码器 Sparse Coding稀疏编码 Rest ...
- 深度学习基础(五)ResNet_Deep Residual Learning for Image Recognition
ResNet可以说是在过去几年中计算机视觉和深度学习领域最具开创性的工作.在其面世以后,目标检测.图像分割等任务中著名的网络模型纷纷借鉴其思想,进一步提升了各自的性能,比如yolo,Inception ...
- 深度学习基础(三)NIN_Network In Network
该论文提出了一种新颖的深度网络结构,称为"Network In Network"(NIN),以增强模型对感受野内local patches的辨别能力.与传统的CNNs相比,NIN主 ...
- 机器学习&深度学习基础(目录)
从业这么久了,做了很多项目,一直对机器学习的基础课程鄙视已久,现在回头看来,系统的基础知识整理对我现在思路的整理很有利,写完这个基础篇,开始把AI+cv的也总结完,然后把这么多年做的项目再写好总结. ...
随机推荐
- [Note] Stream Computing
Stream Computing 概念对比 静态数据和流数据 静态数据,例如数据仓库中存放的大量历史数据,特点是不会发生更新,可以利用数据挖掘技术和 OLAP(On-Line Analytical P ...
- SSH服务端配置、优化加速、安全防护
CentOS7自带的SSH服务是OpenSSH中的一个独立守护进程SSHD.由于使用telnet在网络中是明文传输所以用其管理服务器是非常不安全的不安全,SSH协议族可以用来对服务器的管理以及在计算机 ...
- mysql数据库 索引 事务和事务回滚
mysql索引 索引相当于书的目录优点:加快数据的查询速度缺点:占物理存储空间,添加,删除,会减慢写的速度 查看表使用的索引 mysql> show index from 表名\G;(\G分行显 ...
- Ubuntu16.04安装搜狗输入法后有黑边问题的解决方法
apt-get install compton compton -b
- plx9030触发pci中断
if(((SWAB_16(PLX_INT(0x4C)))&0x04)==0x04) { ErrNo = *(UINT16*)(g_MemBase+0XFFFE*2); /*logMsg(&qu ...
- 图像采集系统的Camera Link标准接口设计
高速数据采集系统可对相机采集得到的实时图像进行传输.实时处理,同时实现视频采集卡和计算机之间的通信.系统连接相机的接口用的是Camera Link接口,通过Camera Link接口把实时图像高速传输 ...
- Struts 有哪些常用标签库
Struts 有哪些常用标签库 1.html标签库 2.bean标签库 3.logic标签库
- 异常-----freemarker.template.TemplateException:Error executing macro:mainSelect
1.错误描述 freemarker.template.TemplateException:Error executing macro:mainSelect require parameter:id i ...
- 从html页面加载顺序来更好的理解jquery初始化
一,html页面加载顺序 1,用户输入网址(假设是个html页面,并且是第一次访问),浏览器向服务器发出请求,服务器返回html文件:2,浏览器开始载入html代码,发现<head>标签内 ...
- 手机端仿ios的三级联动脚本四
二,脚本 <script> $("#city-picker").cityPicker({ title: "选择省市区/县", onChange: f ...