Hadoop系列008-HDFS的数据流
本人微信公众号,欢迎扫码关注!

HDFS的数据流
1 HDFS写数据流程
1.1 剖析文件写入

1)客户端向namenode请求上传文件,namenode检查目标文件是否已存在,父目录是否存在。
2)namenode返回是否可以上传。
3)客户端请求第一个 block上传到哪几个datanode服务器上。
4)namenode返回3个datanode节点,分别为dn1、dn2、dn3。
5)客户端请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成
6)dn1、dn2、dn3逐级应答客户端
7)客户端开始往dn1上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,dn1收到一个packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答
8)当一个block传输完成之后,客户端再次请求namenode上传第二个block的服务器。(重复执行3-7步)
1.2 网络拓扑概念
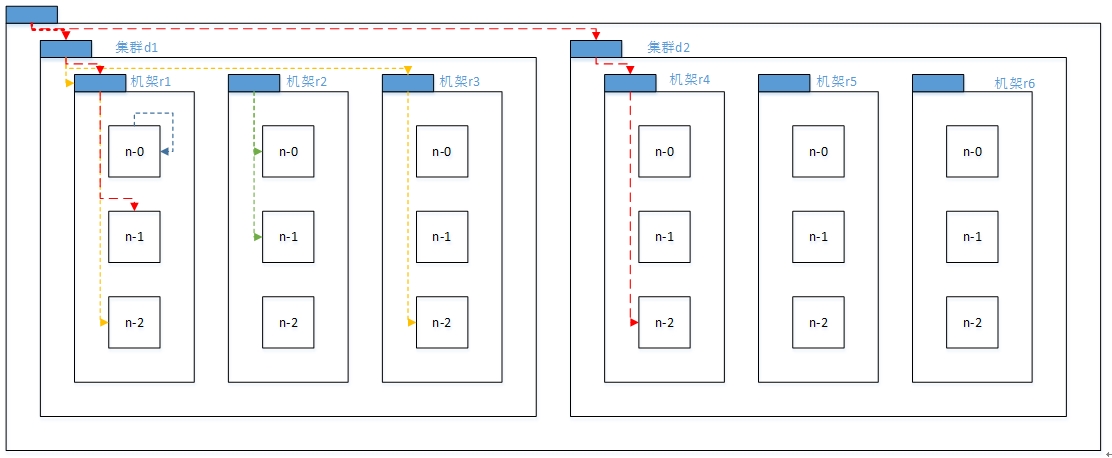
在本地网络中,两个节点被称为“彼此近邻”是什么意思?在海量数据处理中,其主要限制因素是节点之间数据的传输速率——带宽很稀缺。这里的想法是将两个节点间的带宽作为距离的衡量标准。
节点距离:两个节点到达最近的共同祖先的距离总和。
例如,假设有数据中心d1机架r1中的节点n1。该节点可以表示为/d1/r1/n1。利用这种标记,这里给出四种距离描述。
Distance(/d1/r1/n1, /d1/r1/n1)=0(同一节点上的进程)
Distance(/d1/r1/n1, /d1/r1/n2)=2(同一机架上的不同节点)
Distance(/d1/r1/n1, /d1/r3/n2)=4(同一数据中心不同机架上的节点)
Distance(/d1/r1/n1, /d2/r4/n2)=6(不同数据中心的节点)
1.3 机架感知(副本节点选择)
1.3.1 官方地址
http://hadoop.apache.org/docs/r2.7.3/hadoop-project-dist/hadoop-common/RackAwareness.html
1.3.2 低版本Hadoop复本节点选择
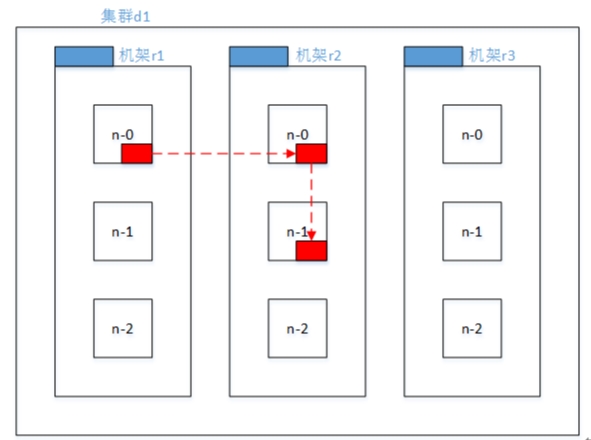
- 第一个复本在client所处的节点上。如果客户端在集群外,随机选一个。
- 第二个复本和第一个复本位于不相同机架的随机节点上。
- 第三个复本和第二个复本位于相同机架,节点随机。
1.3.3 Hadoop2.7.2副本节点选择
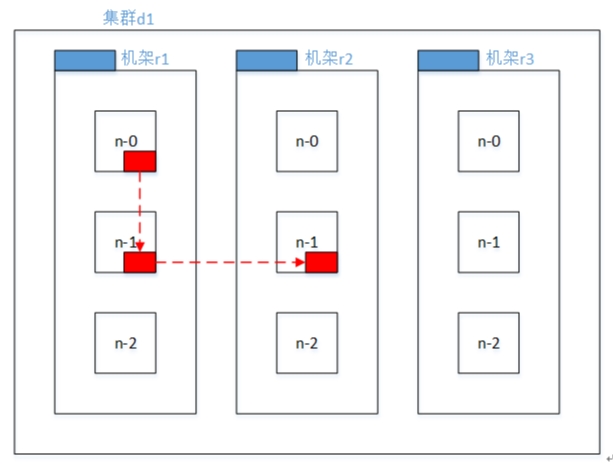
- 第一个副本在client所处的节点上。如果客户端在集群外,随机选一个。
- 第二个副本和第一个副本位于相同机架,随机节点。
- 第三个副本位于不同机架,随机节点。
1.3.4 自定义机架感知
(0)环境准备
(a)数据节点的量
[rack1]:hadoop102、hadoop103
[rack2]:hadoop104、hadoop105
(b)增加一个数据节点
(1)克隆一个节点
(2)启动新节点
(3)修改克隆的ip和主机名
(4)在hadoop102上ssh到新节点
(5)修改xsync.sh和xcall.sh文件
(6)修改hadoop102 slaves文件,再分发
(1)创建类实现DNSToSwitchMapping接口
public class MyDNSToSwichMapping implements DNSToSwitchMapping {
// 传递的是客户端的ip列表,返回机架感知的路径列表
public List<String> resolve(List<String> names) { ArrayList<String> lists = new ArrayList<String>();
if (names != null && names.size() > 0) {
for (String name : names) {
int ip = 0;
// 获取ip地址
if (name.startsWith("hadoop")) {
String no = name.substring(6);
// hadoop102
ip = Integer.parseInt(no);
} else if (name.startsWith("192")) {
// 192.168.10.102
ip = Integer.parseInt(name.substring(name.lastIndexOf(".") + 1));
} // 定义机架
if (ip < 104) {
lists.add("/rack1/" + ip);
} else {
lists.add("/rack2/" + ip);
}
}
} // 把ip地址打印出来
try {
FileOutputStream fos = new FileOutputStream("/home/atguigu/name.txt"); for (String name : lists) {
fos.write((name + "\r\n").getBytes());
}
fos.close();
} catch (Exception e) {
e.printStackTrace();
}
return lists;
}
public void reloadCachedMappings() {
}
public void reloadCachedMappings(List<String> names) {
}
}
(2)配置core-site.xml
默认的:
<!-- Topology Configuration -->
<property>
<name>net.topology.node.switch.mapping.impl</name>
<value>org.apache.hadoop.net.ScriptBasedMapping</value>
</property>
配置后的
<!-- Topology Configuration -->
<property>
<name>net.topology.node.switch.mapping.impl</name>
<value>com.atguigu.hdfs.MyDNSToSwichMapping</value>
</property>
(3)分发core-site.xml
xsync /opt/module/hadoop-2.7.2/etc/hadoop/core-site.xml
(4)编译程序,打成jar,分发到所有节点的hadoop的classpath下
cd /opt/module/hadoop-2.7.2/share/hadoop/common/lib
xsync MyDNSSwitchToMapping.jar
(5)重新启动集群
(6)在名称节点hadoop103主机上查看名称
(7)查看结果
(1)在hadoop105节点上传文件到hdfs文件系统,查看复本存放位置
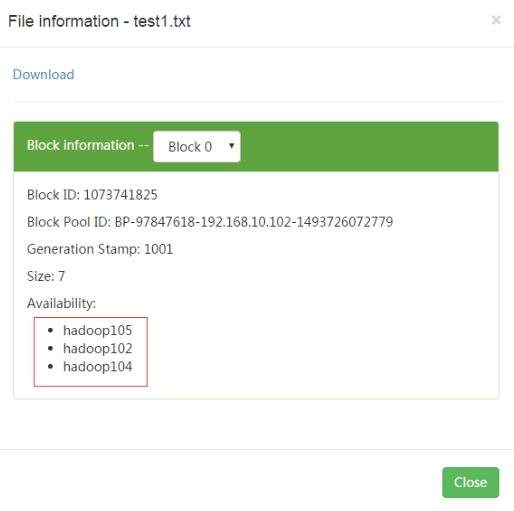
(2)在hadoop102节点上传文件到hdfs文件系统,查看复本存放位置
(3)结论
第一个副本在client所处的节点上。如果客户端在集群外,随机选一个。
第二个副本和第一个副本位于相同机架,随机节点。
第三个副本位于不同机架,随机节点。
2 HDFS读数据流程
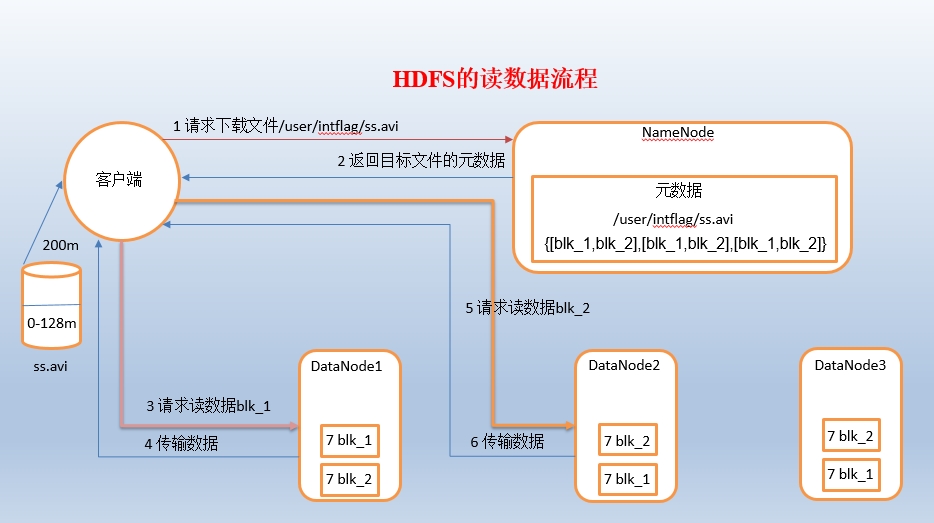
1)客户端向namenode请求下载文件,namenode通过查询元数据,找到文件块所在的datanode地址。
2)挑选一台datanode(就近原则,然后随机)服务器,请求读取数据。
3)datanode开始传输数据给客户端(从磁盘里面读取数据放入流,以packet为单位来做校验)。
4)客户端以packet为单位接收,先在本地缓存,然后写入目标文件。
3 一致性模型
3.1 debug调试如下代码
@Test
public void writeFile() throws Exception{
// 1 创建配置信息对象
Configuration configuration = new Configuration();
fs = FileSystem.get(configuration);
// 2 创建文件输出流
Path path = new Path("hdfs://hadoop102:8020/user/atguigu/hello.txt");
FSDataOutputStream fos = fs.create(path);
// 3 写数据
fos.write("hello".getBytes());
// fos.flush();
fos.hflush();
//
// fos.write("welcome to atguigu".getBytes());
// fos.hsync();
fos.close();
}
3.2 总结
- 写入数据时,如果希望数据被其他client立即可见,调用如下方法
- FsDataOutputStream.hflus(); //清理客户端缓冲区数据,被其他client立即可见
- FsDataOutputStream.hsync(); //清理客户端缓冲区数据,被其他client不能立即可见
Hadoop系列008-HDFS的数据流的更多相关文章
- hadoop系列二:HDFS文件系统的命令及JAVA客户端API
转载请在页首明显处注明作者与出处 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据的一些内容,如hadoop,spark,storm,机器学习等. 当前使用的hadoop版本为2.6 ...
- hadoop系列(二)分布式文件系统HDFS
根据core-site.xml的配置,接下来就可以通过:hdfs://localhost:9000来对hdfs进行操作了. 1.创建输入目录 C:\WINDOWS\system32>hadoop ...
- hadoop系列一:hadoop集群安装
转载请在页首明显处注明作者与出处 http://www.cnblogs.com/zhuxiaojie/p/6384393.html 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据 ...
- hadoop系列三:mapreduce的使用(一)
转载请在页首明显处注明作者与出处 http://www.cnblogs.com/zhuxiaojie/p/7224772.html 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据的 ...
- hadoop系列四:mapreduce的使用(二)
转载请在页首明显处注明作者与出处 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据的一些内容,如hadoop,spark,storm,机器学习等. 当前使用的hadoop版本为2.6 ...
- Hadoop系列007-HDFS客户端操作
title: Hadoop系列007-HDFS客户端操作 date: 2018-12-6 15:52:55 updated: 2018-12-6 15:52:55 categories: Hadoop ...
- Hadoop系列004-Hadoop运行模式(上)
title: Hadoop系列004-Hadoop运行模式(上) date: 2018-11-20 14:27:00 updated: 2018-11-20 14:27:00 categories: ...
- Hadoop 系列(三)Java API
Hadoop 系列(三)Java API <dependency> <groupId>org.apache.hadoop</groupId> <artifac ...
- Hadoop系列之(二):Hadoop集群部署
1. Hadoop集群介绍 Hadoop集群部署,就是以Cluster mode方式进行部署. Hadoop的节点构成如下: HDFS daemon: NameNode, SecondaryName ...
随机推荐
- app与手机其他软件交互测试
针对智能终端应用的服务等级划分方式及实时特性所提出的测试方法.交叉测试又叫事件或冲突测试,是指一个功能正在执行过程中,同时另外一个事件或操作对该过程进行干扰的测试.如:App在前/后台运行状态时与来电 ...
- openfire推送离线聊天信息的插件
插件说明 在手机的聊天应用中,经常出现的一个需求就是把用户的离线消息通过推送系统推送到用户的手机上,为了实现这个功能,本人就开发了本插件,这个openfire 插件是拦截了发给openfire用户的离 ...
- java-直接选择排序
直接选择排序是一种简单的排序方法,它每次从当前待排序的区间中选择出最小的元素,把该元素与该区间的第一个元素交换. 第一次从a[0]~a[n-1]中选取最小值,与a0]交换,第二次从a[1]~a[n-1 ...
- Spring-cloud (九) Hystrix请求合并的使用
前言: 承接上一篇文章,两文本来可以一起写的,但是发现RestTemplate使用普通的调用返回包装类型会出现一些问题,也正是这个问题,两文没有合成一文,本文篇幅不会太长,会说一下使用和适应的场景. ...
- conn.go 源码阅读
), Conn: conn, } return k, v } // 返回远程节点地址 func (self *Connect) Addr() string { ...
- POJ_1066_Treasure Hunt_判断线段相交
POJ_1066_Treasure Hunt_判断线段相交 Description Archeologists from the Antiquities and Curios Museum (ACM) ...
- BZOJ_4176_Lucas的数论_杜教筛+莫比乌斯反演
BZOJ_4176_Lucas的数论_杜教筛+莫比乌斯反演 Description 去年的Lucas非常喜欢数论题,但是一年以后的Lucas却不那么喜欢了. 在整理以前的试题时,发现了这样一道题目“求 ...
- 如何运行vue项目
首先,列出来我们需要的东西: node.js环境(npm包管理器) vue-cli 脚手架构建工具 cnpm npm的淘宝镜像 安装node.js 从node.js官网下载并安装node,安 ...
- 优化:mysql查询最近一条记录
下策--查询出结果后将时间排序后取第一条 select * from a where create_time<="2017-03-29 19:30:36" order by ...
- ReentrantLock之非公平锁源码分析
本文分析的ReentrantLock所对应的Java版本为JDK8. 在阅读本文前,读者应该知道什么是CAS.自旋. 由于ReentrantLock的公平锁和非公平锁中有许多共同代码,本文只会对这两种 ...