[C#]Google Chrome 书签导出并生成 MHTML 文件
目的
因为某些原因需要将存放在 Google Chrome 内的书签导出到本地,所幸 Google Chrome 提供了导出书签的功能。
分析
首先在 Google Chrome 浏览器当中输入 chrome://bookmarks 来到书签管理页面,找到最右侧的三个点,选择导出书签,导出的文件是一个 HTML 文件,里面包含了所有书签的层级结构等信息。
使用 Notepad++ 打开该文件之后可以看到里面的内容如下:
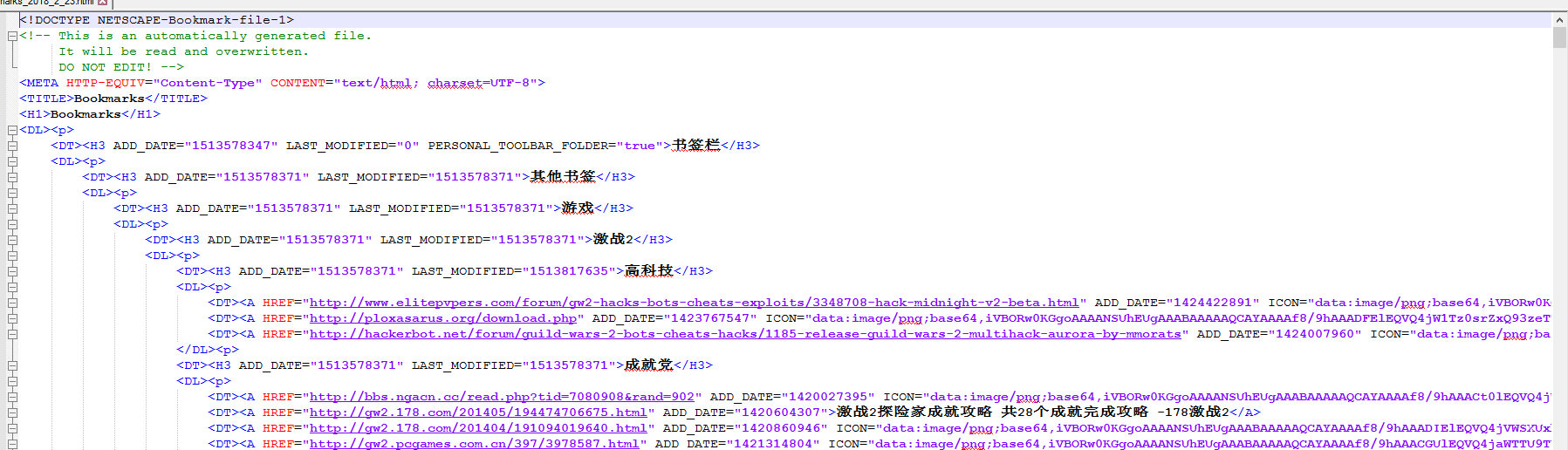
粗略一看貌似没什么问题,其实在里面的 <DT> 与 <P> 都缺少了闭合标签,所以在解析的时候需要将其去除掉。去除掉之后的 HTML 文件结构大概像这样:
<DL>
<H3>文件夹标题</H3>
<DL>
<H3>子文件夹标题</H3>
<A HREF="书签地址">子文件夹书签1</A>
<A HREF="书签地址">子文件夹书签2</A>
</DL>
<A HREF="书签地址">书签1</A>
<A HREF="书签地址">书签2</A>
</DL>
可以很明显看到这里是有一个层级关系的,所以我们可以通过递归来生成一个树形模型,生成之后,再遍历这个模型来根据这个树形结构来创建 MHTML 文件,并且进行归类。
实现
操作 HTML 文件在 .Net 下有一个很方便的第三方库,名字叫做 HtmlAgilityPack,通过这个库我们可以很方便地操作 HTML 文档,就跟 DOM 一样方便,而且它支持 XPath 选取。
项目地址:http://html-agility-pack.net/
GitHub 地址:https://github.com/zzzprojects/html-agility-pack
Nuget 地址:https://www.nuget.org/packages/HtmlAgilityPack/
通过 Nuget 安装该包到项目当中,引入HtmlAgilityPack命名空间,就可以开始编写代码了。
1.编写 HtmlResolver 解析器
建立一个 HtmlResolver 类,该类用于解析 Chrome 导出的书签:
public class HtmlResolver
{
private HtmlDocument _htmlDocument = new HtmlDocument();
/// <summary>
/// 初始化 HTML 解析器
/// </summary>
/// <param name="htmlPath">Google Chrome 导出的书签 HTML 路径</param>
public HtmlResolver(string htmlPath)
{
using (FileStream htmlFileStream = File.Open(htmlPath, FileMode.Open))
{
using (StreamReader htmlReader = new StreamReader(htmlFileStream))
{
// 移除干扰标签
string htmlStr = htmlReader.ReadToEnd();
htmlStr = htmlStr.Replace(@"<DT>", string.Empty).Replace(@"<p>", string.Empty);
// 加载 HTML
_htmlDocument.LoadHtml(htmlStr);
}
}
}
}
在对象初始化的时候要求提供 Google Chrome 导出的书签 HTML 文件路径,并且读入 HTML 文件数据的时候移除掉之前所说的 <DT> 与 <P> 标签,方便后面 HtmlAgilityPack 进行解析,移除之后,HtmlDocument 通过 HTML String 初始化。
2.创建书签模型
当我们递归完成之后需要将数据存储在书签模型当中,方便后面生成 MHTML 文件的时候使用。
/// <summary>
/// 书签模型
/// </summary>
public class BookMarkModel
{
/// <summary>
/// 初始化书签模型
/// </summary>
/// <param name="name">书签名称</param>
/// <param name="path">书签路径</param>
/// <param name="url">绑定的 URL</param>
/// <param name="childNodes">子节点集合</param>
public BookMarkModel(string name, string path, string url = null, List<BookMarkModel> childNodes = null)
{
Name = name;
Url = url;
ChildNodes = childNodes;
Path = path;
}
/// <summary>
/// 书签名称
/// </summary>
public string Name { get; set; }
/// <summary>
/// 绑定的 URL
/// </summary>
public string Url { get; set; }
/// <summary>
/// 书签路径
/// </summary>
public string Path { get; set; }
/// <summary>
/// 子节点集合,如果没有则为 NULL
/// </summary>
public List<BookMarkModel> ChildNodes { get; set; }
}
该模型是一个典型的树形结构,之后我们就开始递归生成书签模型了。
3.递归生成树形模型
递归算法自己一直不太会写,写好这一个递归方法基本都花费了半天的时间
[C#]Google Chrome 书签导出并生成 MHTML 文件的更多相关文章
- Google Chrome 书签导出并生成 MHTML 文件
目的 因为某些原因需要将存放在 Google Chrome 内的书签导出到本地,所幸 Google Chrome 提供了导出书签的功能. 分析 首先在 Google Chrome 浏览器当中输入 ch ...
- Android手机同步电脑端google chrome书签
我先声明:文中FQ 都是博客园自动将中文(fan qiang)转换为FQ的,并不是我本来写的就是FQ~~ 手机和电脑都必须要能登录google(Xee:几乎所有做开发的人都每天的生活都离不开谷歌了,可 ...
- powerdesigner连接数据库 导出数据 生成PDM文件 傻瓜试教程
也可下载文档:http://download.csdn.net/detail/shutingwang/6378665
- Google Chrome Plus——绿色便携多功能谷歌浏览器
我更新浏览器的时候一般没有时间更新这个帖子,所以具体请看我网盘下载链接里面的更新日志,请自行查看最新版本下载,谢谢. 近期更新日期:2016.8.15(此时间可能不是最新,请看我网盘里面的更新日志) ...
- 360chrome,google chrome浏览器使用jquery.ajax加载本地html文件
使用360chrome和google chrome浏览器加载本地html文件时,会报错,提示: XMLHttpRequest cannot load file:///Y:/jswg/code/html ...
- java导出生成csv文件
首先我们需要对csv文件有基础的认识,csv文件类似excel,可以使用excel打开,但是csv文件的本质是逗号分隔的,对比如下图: txt中显示: 修改文件后缀为csv后显示如下: 在java中我 ...
- Google Chrome 自定义协议(PROTOCOL)问题的处理
最近在使用谷歌浏览器的时候遇到了自定义协议(PROTOCOL)的问题,比较折腾,特此记录,希望我浪费生命换来的结果能够帮助读到此文的朋友少浪费一点宝贵的时间! 由于某些原因,电脑里一直没有安装阿里旺旺 ...
- google浏览器如何导出书签
首先打开浏览器点右侧的自定义及控制Google chrome. 点击书签-书签管理器 打开书签管理器界面中· 点击书签管理器的整理 最下面的将书签导出到html文件.. 弹出另存为对话 ...
- 手机chrome书签文件导出教程
重大发现!!!本人亲自测试可以导出chrome书签文件登录下面的链接https://takeout.google.com/settings/takeout/custom/chrome?pli=1
随机推荐
- [mysql] MySQL解压缩安装步骤
以前装的MySQL出问题了,只好卸载了. 又下载了一个mysql-5.6.24-win32.1432006610.zip.msi文件直接安装就行了.这里需要解压到指定目录,配置后可使用. 环境变量配置 ...
- node.js与比特币(typescript实现)
BTC中的utxo模型 BTC中引入了许多创新的概念与技术,区块链.PoW共识.RSA加密.萌芽阶段的智能合约等名词是经常被圈内人所提及,诚然这些创新的实现使得BTC变成了一种有可靠性和安全性保证的封 ...
- SSH相关知识
SSH(Secure Shell, 安全Shell协议)是一种加密的网络传输协议,经常用于安全的远程登录. SSH只是一种协议,可以有多种实现. OPENSSH是一种应用广泛的实现. sshd是dae ...
- (译文)掌握JavaScript基础--理解this关键字的新思路
普通函数 下面这种就是普通函数 function add(x, y) { return x + y; } 每个普通函数被调用的时候,都相当于有一个this参数传进来. 内部函数this不会是外部函数传 ...
- Kettle 初始配置数据量类型资源库
PS:有段时间不使用Kettle了,但总遇到小伙伴问起,写一篇记录下. 文档使用版本:KETTLE 7.0 Kettle资源库可分为文件与数据库,文件型只需要配置好存放路径就行,这边介绍的是配置数据库 ...
- Hibernate——配置并访问数据库
Hibernate,对于java来说很重要的一个东西,用于持久层.之前看了很多配置的,都不行,自己来写一个配置成功的. 环境:jdk1.8,eclipse-jee-oxygen,mysql-conne ...
- Welcome to StackEdit!
Welcome to StackEdit! Hey!our first Markdown document in StackEdit1. Don't delete me, I'm very helpf ...
- django搭建web (三) admin.py -- 待续
demo 关于模型myQuestion,myAnswer将在后述博客提及 # -*- coding: utf-8 -*- from __future__ import unicode_literals ...
- Hibernate实体类注解解释
Hibernate注解1.@Entity(name="EntityName")必须,name为可选,对应数据库中一的个表2.@Table(name="",cat ...
- WebApi 方法的参数类型总结。
1:[HttpGet] ①:get方法之无参数. [HttpGet] public IHttpActionResult GetStudentInfor() { List<StudentMode ...