数据集偏斜 - class skew problem - 以SVM松弛变量为例
原文
接下来要说的东西其实不是松弛变量本身,但由于是为了使用松弛变量才引入的,因此放在这里也算合适,那就是惩罚因子C。回头看一眼引入了松弛变量以后的优化问题:

注意其中C的位置,也可以回想一下C所起的作用(表征你有多么重视离群点,C越大越重视,越不想丢掉它们)。这个式子是以前做SVM的人写的,大家也就这么用,但没有任何规定说必须对所有的松弛变量都使用同一个惩罚因子,我们完全可以给每一个离群点都使用不同的C,这时就意味着你对每个样本的重视程度都不一样,有些样本丢了也就丢了,错了也就错了,这些就给一个比较小的C;而有些样本很重要,决不能分类错误(比如中央下达的文件啥的,笑),就给一个很大的C。
当然实际使用的时候并没有这么极端,但一种很常用的变形可以用来解决分类问题中样本的“偏斜”问题。
先来说说样本的偏斜问题,也叫数据集偏斜(unbalanced),它指的是参与分类的两个类别(也可以指多个类别)样本数量差异很大。比如说正类有10,000个样本,而负类只给了100个,这会引起的问题显而易见,可以看看下面的图:
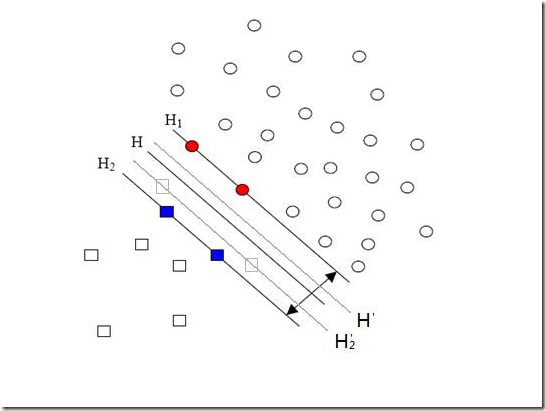
方形的点是负类。H,H1,H2是根据给的样本算出来的分类面,由于负类的样本很少很少,所以有一些本来是负类的样本点没有提供,比如图中两个灰色的方形点,如果这两个点有提供的话,那算出来的分类面应该是H’,H2’和H1,他们显然和之前的结果有出入,实际上负类给的样本点越多,就越容易出现在灰色点附近的点,我们算出的结果也就越接近于真实的分类面。但现在由于偏斜的现象存在,使得数量多的正类可以把分类面向负类的方向“推”,因而影响了结果的准确性。
对付数据集偏斜问题的方法之一就是在惩罚因子上作文章,想必大家也猜到了,那就是给样本数量少的负类更大的惩罚因子,表示我们重视这部分样本(本来数量就少,再抛弃一些,那人家负类还活不活了),因此我们的目标函数中因松弛变量而损失的部分就变成了:

其中i=1…p都是正样本,j=p+1…p+q都是负样本。libSVM这个算法包在解决偏斜问题的时候用的就是这种方法。
那C+和C-怎么确定呢?它们的大小是试出来的(参数调优),但是他们的比例可以有些方法来确定。咱们先假定说C+是5这么大,那确定C-的一个很直观的方法就是使用两类样本数的比来算,对应到刚才举的例子,C-就可以定为500这么大(因为10,000:100=100:1嘛)。
但是这样并不够好,回看刚才的图,你会发现正类之所以可以“欺负”负类,其实并不是因为负类样本少,真实的原因是负类的样本分布的不够广(没扩充到负类本应该有的区域)。说一个具体点的例子,现在想给政治类和体育类的文章做分类,政治类文章很多,而体育类只提供了几篇关于篮球的文章,这时分类会明显偏向于政治类,如果要给体育类文章增加样本,但增加的样本仍然全都是关于篮球的(也就是说,没有足球,排球,赛车,游泳等等),那结果会怎样呢?虽然体育类文章在数量上可以达到与政治类一样多,但过于集中了,结果仍会偏向于政治类!所以给C+和C-确定比例更好的方法应该是衡量他们分布的程度。比如可以算算他们在空间中占据了多大的体积,例如给负类找一个超球——就是高维空间里的球啦——它可以包含所有负类的样本,再给正类找一个,比比两个球的半径,就可以大致确定分布的情况。显然半径大的分布就比较广,就给小一点的惩罚因子。
但是这样还不够好,因为有的类别样本确实很集中,这不是提供的样本数量多少的问题,这是类别本身的特征(就是某些话题涉及的面很窄,例如计算机类的文章就明显不如文化类的文章那么“天马行空”),这个时候即便超球的半径差异很大,也不应该赋予两个类别不同的惩罚因子。
看到这里读者一定疯了,因为说来说去,这岂不成了一个解决不了的问题?然而事实如此,完全的方法是没有的,根据需要,选择实现简单又合用的就好(例如libSVM就直接使用样本数量的比)。

数据集偏斜 - class skew problem - 以SVM松弛变量为例的更多相关文章
- Relation Extraction中SVM分类样例unbalance data问题解决 -松弛变量与惩罚因子
转载自:http://blog.csdn.net/yangliuy/article/details/8152390 1.问题描述 做关系抽取就是要从产品评论中抽取出描述产品特征项的target短语以及 ...
- 7. SVM松弛变量
我们之前讨论的情况都是建立在样例线性可分的假设上,当样例线性不可分时,我们可以尝试使用核函数来将特征映射到高维,这样很可能就可分了.然而,映射后我们也不能100%保证可分.那怎么办呢,我们需要将模型进 ...
- Python实现鸢尾花数据集分类问题——基于skearn的SVM
Python实现鸢尾花数据集分类问题——基于skearn的SVM 代码如下: # !/usr/bin/env python # encoding: utf-8 __author__ = 'Xiaoli ...
- SVM松弛变量-记录毕业论文3
上一篇博客讨论了高维映射和核函数,也通过例子说明了将特征向量映射到高维空间中可以使其线性可分.然而,很多情况下的高维映射并不能保证线性可分,这时就可以通过加入松弛变量放松约束条件.同样这次的记录仍然通 ...
- SVM python小样例
SVM有很多种实现,但是本章只关注其中最流行的一种实现,即序列最小化(SMO)算法在此之后,我们将介绍如何使用一种称为核函数的方式将SVM扩展到更多的数据集上基于最大间隔的分割数据优点:泛化错误率低, ...
- SVM学习(五):松弛变量与惩罚因子
https://blog.csdn.net/qll125596718/article/details/6910921 1.松弛变量 现在我们已经把一个本来线性不可分的文本分类问题,通过映射到高维空间而 ...
- SVM学习(续)核函数 & 松弛变量和惩罚因子
SVM的文章可以看:http://www.cnblogs.com/charlesblc/p/6193867.html 有写的最好的文章来自:http://www.blogjava.net/zhenan ...
- SVM学习(续)
SVM的文章可以看:http://www.cnblogs.com/charlesblc/p/6193867.html 有写的最好的文章来自:http://www.blogjava.net/zhenan ...
- 【转】 SVM算法入门
课程文本分类project SVM算法入门 转自:http://www.blogjava.net/zhenandaci/category/31868.html (一)SVM的简介 支持向量机(Supp ...
随机推荐
- 不显示cmd窗口运行jar包
今天,打开导出的jar包,发现并不能运行,查看jar包中的META-INF文件夹下的MANIFEST.MF文件,发现MANIFEST.MF中并没有Main-Class,于是,就手动添加相应的信息,本项 ...
- bzoj1001--最大流转最短路
http://www.lydsy.com/JudgeOnline/problem.php?id=1001 思路:这应该算是经典的最大流求最小割吧.不过题目中n,m<=1000,用最大流会TLE, ...
- ListView初探
一.ListView介绍 在Android开发中ListView是比较常用的控件,常用于以列表的形式显示数据集及根据数据的长度自适应显示. ListView通常有两个主要功能点: (1)将数据集填充到 ...
- 每次新建项目出现appcompat_v7 解决方法
ADT升级版本后每次新建项目出现appcompat_v7 , 解决方案如下 问题生成:
- css图片精灵
<ul> <li class="top"> <em>01</em> <p><a href="http:/ ...
- Mybatis的基本操作案列增加以及源码的分析(二)
一.构建一个框架的项目的思路 首先我们先建立一个web项目,我们需要jar,mybatis-config.xml和studentDao.xml的配置随后就是dao.daoimpl.entity.的架构 ...
- 负载均衡之LVS集群
h3 { color: rgb(255, 255, 255); background-color: rgb(30,144,255); padding: 3px; margin: 10px 0px } ...
- ArcGIS Engine开发之鹰眼视图
鹰眼是GIS软件的必备功能之一.它是一个MapControl控件,主要用来表示数据视图中的地理范围在全图中的位置. 鹰眼一般具有的功能: 1)鹰眼视图与数据视图的地理范围保持同步. 2)数据视图的当前 ...
- DevExpress VCL v16.1.3发布
ExpressPDFViewer # BC3840:包含action标题和action提示的 Action classes 和 resource strings 重命名: class名称末尾中包含'A ...
- Newtonsoft.Json 自定义 解析协议
在开发web api的时候 遇到一个要把string未赋值默认为null的情况改成默认为空字符串的需求 这种情况就需要自定义json序列话的 解析协议了 Newtonsoft.Json默认的解析协议是 ...