Python爬虫——request实例:爬取网易云音乐华语男歌手top10歌曲
requests是python的一个HTTP客户端库,跟urllib,urllib2类似,但比那两个要简洁的多,至于request库的用法,
推荐一篇不错的博文:https://cuiqingcai.com/2556.html
话不多说,先说准备工作:
1,下载需要的库:request,BeautifulSoup( 解析html和xml字符串),xlwt(将爬取到的数据存入Excel表中)
2,至于BeautifulSoup 解析html方法,推荐一篇博文:http://blog.csdn.net/u013372487/article/details/51734047
3,re库,我们要用正则表达式来筛选爬取到的内容
好的,开始爬:
首先我们找到网易云音乐华语男歌手页面入口的URL:url = 'http://music.163.com/discover/artist/cat?id=1001'
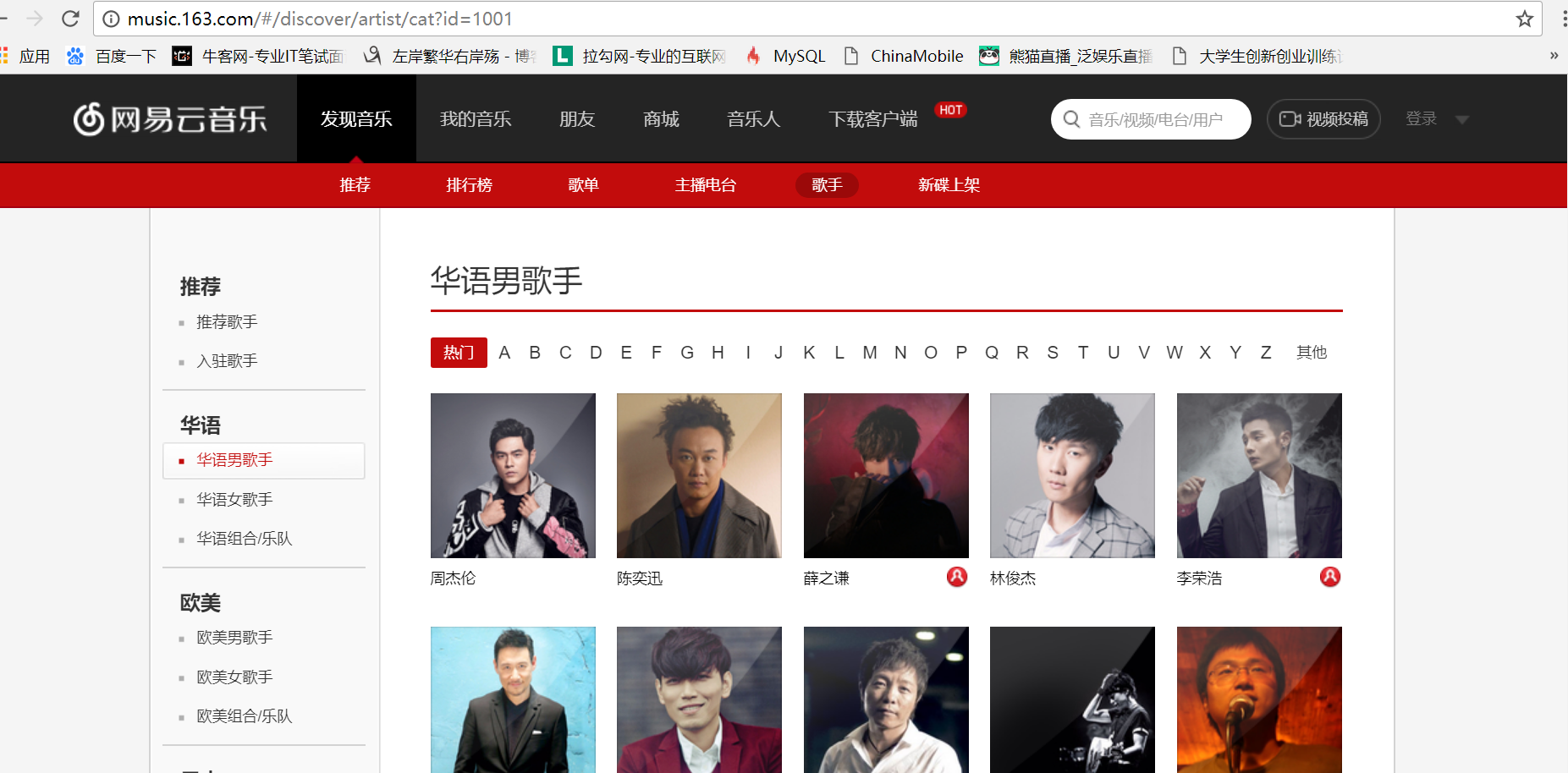
把整个网页爬取下来: html= requests.get(url).text
soup = BeautifulSoup(html,'html.parser'
我们要找到进入top10歌手页面的url,用浏览器的开发者工具,我们发现歌手的信息
都在<div class="u-cover u-cover-5">......</div>这个标签里面,如图:
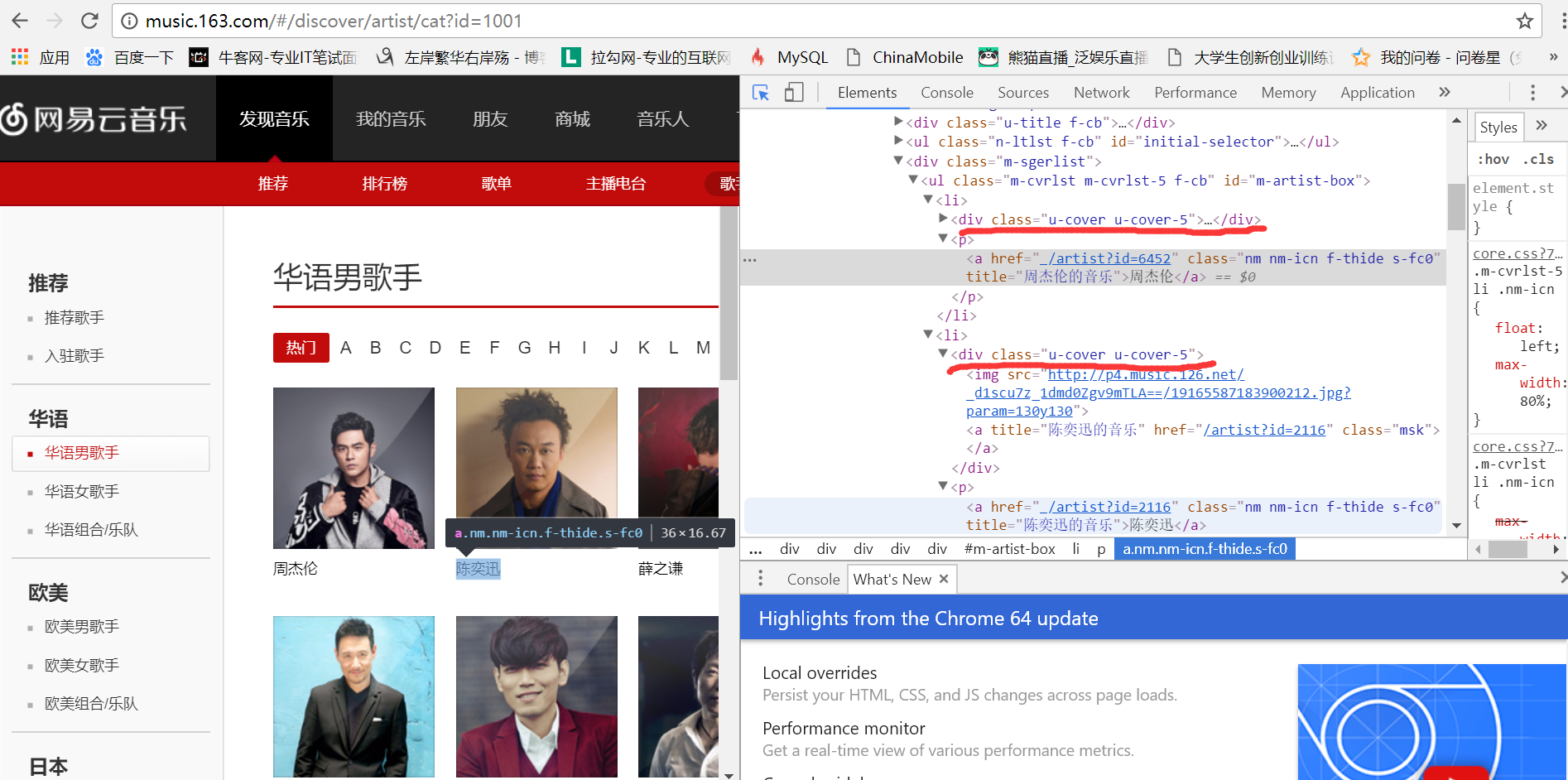
于是,我们把top10歌手的信息筛选出来:
top_10 = soup.find_all('div',attrs = {'class':'u-cover u-cover-5'})
singers = []
for i in top_10:
singers.append(re.findall(r'.*?<a class="msk" href="(/artist\?id=\d+)" title="(.*?)的音乐"></a>.*?',str(i))[0])
获取到歌手的信息后,依次进入歌手的界面,把他们的热门歌曲爬取并写入Excel表中,原理同上
附上完整代码:
import xlwt
import requests
from bs4 import BeautifulSoup
import re url = 'http://music.163.com/discover/artist/cat?id=1001'#华语男歌手页面
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
html=r.text #获取整个网页 soup = BeautifulSoup(html,'html.parser') #
top_10 = soup.find_all('div',attrs = {'class':'u-cover u-cover-5'})
#print(top_10) singers = []
for i in top_10:
singers.append(re.findall(r'.*?<a class="msk" href="(/artist\?id=\d+)" title="(.*?)的音乐"></a>.*?',str(i))[0])
#print(singers) url = 'http://music.163.com'
for singer in singers:
try:
new_url = url + str(singer[0])
#print(new_url)
songs=requests.get(new_url).text
soup = BeautifulSoup(songs,'html.parser')
Info = soup.find_all('textarea',attrs = {'style':'display:none;'})[0]
songs_url_and_name = soup.find_all('ul',attrs = {'class':'f-hide'})[0]
#print(songs_url_and_name)
datas = []
data1 = re.findall(r'"album".*?"name":"(.*?)".*?',str(Info.text))
data2 = re.findall(r'.*?<li><a href="(/song\?id=\d+)">(.*?)</a></li>.*?',str(songs_url_and_name)) for i in range(len(data2)):
datas.append([data2[i][1],data1[i],'http://music.163.com/#'+ str(data2[i][0])])
#print(datas)
book = xlwt.Workbook()
sheet1=book.add_sheet('sheet1',cell_overwrite_ok = True)
sheet1.col(0).width = (25*256)
sheet1.col(1).width = (30*256)
sheet1.col(2).width = (40*256)
heads=['歌曲名称','专辑','歌曲链接']
count=0 for head in heads:
sheet1.write(0,count,head)
count+=1 i=1
for data in datas:
j=0
for k in data:
sheet1.write(i,j,k)
j+=1
i+=1
book.save(str(singer[1])+'.xls')#括号里写存入的地址 except:
continue
Python爬虫——request实例:爬取网易云音乐华语男歌手top10歌曲的更多相关文章
- 如何用Python网络爬虫爬取网易云音乐歌曲
今天小编带大家一起来利用Python爬取网易云音乐,分分钟将网站上的音乐down到本地. 跟着小编运行过代码的筒子们将网易云歌词抓取下来已经不再话下了,在抓取歌词的时候在函数中传入了歌手ID和歌曲名两 ...
- python网络爬虫&&爬取网易云音乐
#爬取网易云音乐 url="https://music.163.com/discover/toplist" #歌单连接地址 url2 = 'http://music.163.com ...
- python爬虫+词云图,爬取网易云音乐评论
又到了清明时节,用python爬取了网易云音乐<清明雨上>的评论,统计词频和绘制词云图,记录过程中遇到一些问题 爬取网易云音乐的评论 一开始是按照常规思路,分析网页ajax的传参情况.看到 ...
- 爬取网易云音乐评论!python 爬虫入门实战(六)selenium 入门!
说到爬虫,第一时间可能就会想到网易云音乐的评论.网易云音乐评论里藏了许多宝藏,那么让我们一起学习如何用 python 挖宝藏吧! 既然是宝藏,肯定是用要用钥匙加密的.打开 Chrome 分析 Head ...
- python爬虫:了解JS加密爬取网易云音乐
python爬虫:了解JS加密爬取网易云音乐 前言 大家好,我是"持之以恒_liu",之所以起这个名字,就是希望我自己无论做什么事,只要一开始选择了,那么就要坚持到底,不管结果如何 ...
- 用Python爬取网易云音乐热评
用Python爬取网易云音乐热评 本文旨在记录Python爬虫实例:网易云热评下载 由于是从零开始,本文内容借鉴于各种网络资源,如有侵权请告知作者. 要看懂本文,需要具备一点点网络相关知识.不过没有关 ...
- Python爬取网易云音乐歌手歌曲和歌单
仅供学习参考 Python爬取网易云音乐网易云音乐歌手歌曲和歌单,并下载到本地 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经做 ...
- python爬取网易云音乐歌曲评论信息
网易云音乐是广大网友喜闻乐见的音乐平台,区别于别的音乐平台的最大特点,除了“它比我还懂我的音乐喜好”.“小清新的界面设计”就是它独有的评论区了——————各种故事汇,各种金句频出.我们可以透过歌曲的评 ...
- python3爬虫应用--爬取网易云音乐(两种办法)
一.需求 好久没有碰爬虫了,竟不知道从何入手.偶然看到一篇知乎的评论(https://www.zhihu.com/question/20799742/answer/99491808),一时兴起就也照葫 ...
随机推荐
- Web自动化之Headless Chrome开发工具库
命令行运行Headless Chrome Chrome 安装(需要带梯子) 下载地址 几个版本的比较 Chromium 不是Chrome,但Chrome的内容基本来源于Chromium,这个是开源的版 ...
- Redis 设置开机启动
1. 将下列代码保存为文件redis, 置于 /etc/init.d 下面 ########################### # chkconfig: 2345 90 10 redis服务必须在 ...
- bash文件的详细解读
一.bash的分类 1. 按生效范围分类 全局生效 /etc/profile /etc/profile.d/*.sh /etc/bashrc 个人用户生效 ~/.bash_profile ~/.bas ...
- JavaScript预编译原理分析
一直对变量对象,活动对象,预编译,变量提升,执行上下文的时间顺序有着凌乱的认识,但是这些对理解JS语法有着很重要的作用.读了很多人的文章,都没有一个特别清晰的把这些写出来. 今天主要总结一下现阶段自己 ...
- 面向对象的线程池Threadpool的封装
线程池是一种多线程处理形式,预先创建好一定数量的线程,将其保存于一个容器中(如vector), 处理过程中将任务添加到队列,然后从容器中取出线程后自动启动这些任务,具体实现如下. 以下是UML图,展示 ...
- FusionCharts饼图中label值太长怎么解决
FusionCharts饼图中label值太长怎么解决 1.使用hoverText属性 <?xml version="1.0" encoding="UTF-8&qu ...
- Linux显示登录Shell信息
Linux显示登录Shell信息 youhaidong@youhaidong-ThinkPad-Edge-E545:~$ finger -p Login Name Tty Idle Login Tim ...
- Openstack_O版(otaka)部署_Nova部署
控制节点配置 1. 建库建用户 CREATE DATABASE nova_api; CREATE DATABASE nova; GRANT ALL PRIVILEGES ON nova_api.* T ...
- Codeforces Round #425 (Div. 2) D.Misha, Grisha and Underground
我奇特的脑回路的做法就是 树链剖分 + 树状数组 树状数组是那种 区间修改,区间求和,还有回溯的 当我看到别人写的是lca,直接讨论时,感觉自己的智商收到了碾压... #include<cmat ...
- UEFI模式 Thinkpad t470p Ubuntu 16.04 LTS
准备阶段 使用官方推荐的Rufus制作U盘启动盘 在Windows 10系统下压缩出来一些空间(60G),不要分配盘符 系统设置 在Bios中关闭secure boot (设置为Disenabled) ...