sklearn_收入模型
python信用评分卡建模(附代码,博主录制)

数据源
https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.names
fnlwgt (final weight)
Description of fnlwgt (final weight)
|
| The weights on the CPS files are controlled to independent estimates of the
| civilian noninstitutional population of the US. These are prepared monthly
| for us by Population Division here at the Census Bureau. We use 3 sets of
| controls.
| These are:
| 1. A single cell estimate of the population 16+ for each state.
| 2. Controls for Hispanic Origin by age and sex.
| 3. Controls by Race, age and sex.
|
| We use all three sets of controls in our weighting program and "rake" through
| them 6 times so that by the end we come back to all the controls we used.
|
| The term estimate refers to population totals derived from CPS by creating
| "weighted tallies" of any specified socio-economic characteristics of the
| population.
|
| People with similar demographic characteristics should have
| similar weights. There is one important caveat to remember
| about this statement. That is that since the CPS sample is
| actually a collection of 51 state samples, each with its own
| probability of selection, the statement only applies within
| state.
fnlwgt的描述(最终重量)
当前人口调查(CPS)档案中的权重受到对美国民间非机构人口的独立估计的控制。这些是由人口司每月为我们在人口普查局这里准备的。我们使用3套控件。这些是:
单个细胞估计每个州16岁以上的人口。
按年龄和性别控制西班牙裔。
按种族,年龄和性别控制。
我们在加权程序中使用所有三组控件,并通过它们“耙”6次,最终我们回到所有我们使用的控件。术语“估计”指的是通过创建人口任何特定社会经济特征的“加权统计”来源于CPS的人口总数。具有相似人口特征的人应具有相似的权重。要记住这个声明有一个重要的警告。这就是说,由于CPS样本实际上是51个状态样本的集合,每个样本都有自己的选择概率,所以该语句仅适用于状态。
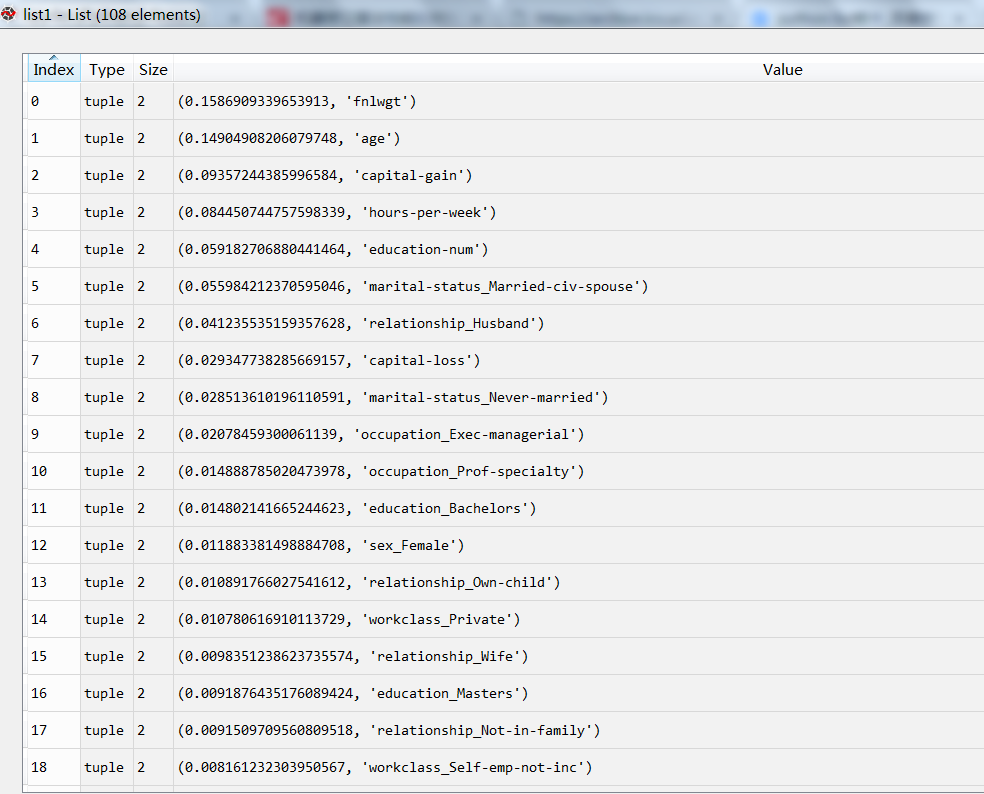

对比原始数据和imputer处理后数据
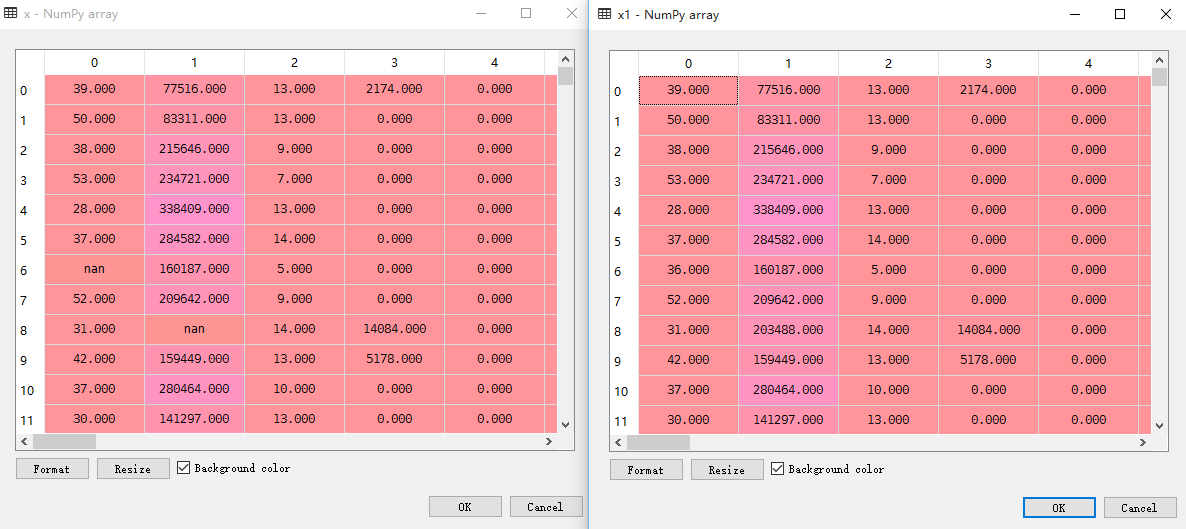
数据集里删除了几个值,作为缺失数据
最后逻辑回归准确率8%左右

# -*- coding: utf-8 -*-
"""
Created on Tue Aug 14 10:34:11 2018 @author: zhi.li04 哑变量可以解决分类变量得缺失数据
连续变量缺失数据必须用Imputer 函数处理
"""
import pandas as pd
from sklearn import metrics
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import Imputer
#读取文件
readFileName="income.xlsx" #读取excel
data=pd.read_excel(readFileName) #data=data[['age','workclass','education','sex','hours-per-week','occupation','income']]
data_dummies=pd.get_dummies(data) #存入Excel
#data_dummies.to_excel("data_dummies.xlsx")
print('features after one-hot encoding:\n',list(data_dummies.columns))
#features_test=data_dummies.ix[:,"age":'occupation_Transport-moving']
features=data_dummies.ix[:,"age":'native-country_ Yugoslavia']
x=features.values #缺失数据处理
imp = Imputer(missing_values='NaN', strategy='most_frequent', axis=0)
imp.fit(x)
#x1是处理缺失数据后的值
x1=imp.transform(x) y=data_dummies['income_ >50K'].values
x_train,x_test,y_train,y_test=train_test_split(x1,y,random_state=0)
logreg=LogisticRegression()
logreg.fit(x_train,y_train)
print("logistic regression:")
print("accuracy on the training subset:{:.3f}".format(logreg.score(x_train,y_train)))
print("accuracy on the test subset:{:.3f}".format(logreg.score(x_test,y_test)))
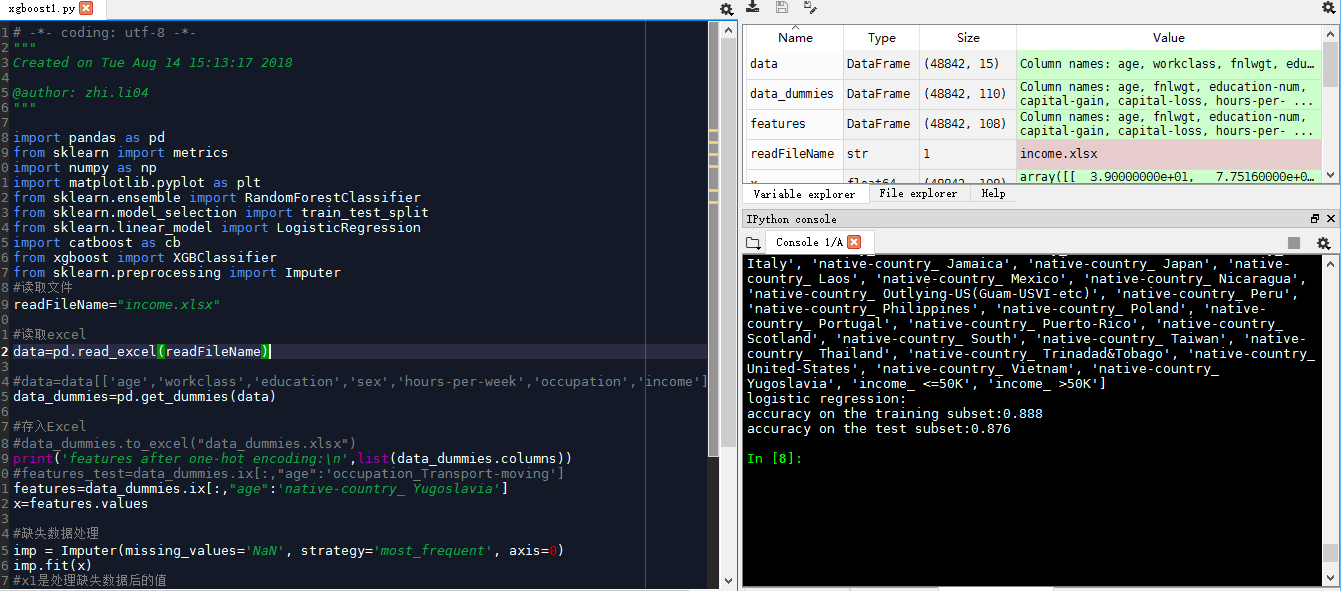
catboost.py
准确率达到0.88左右
# -*- coding: utf-8 -*-
"""
Created on Tue Aug 14 15:02:43 2018 @author: zhi.li04
""" import pandas as pd
from sklearn import metrics
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
import catboost as cb
from sklearn.preprocessing import Imputer
#读取文件
readFileName="income.xlsx" #读取excel
data=pd.read_excel(readFileName) #data=data[['age','workclass','education','sex','hours-per-week','occupation','income']]
data_dummies=pd.get_dummies(data) #存入Excel
#data_dummies.to_excel("data_dummies.xlsx")
print('features after one-hot encoding:\n',list(data_dummies.columns))
#features_test=data_dummies.ix[:,"age":'occupation_Transport-moving']
features=data_dummies.ix[:,"age":'native-country_ Yugoslavia']
x=features.values #缺失数据处理
imp = Imputer(missing_values='NaN', strategy='most_frequent', axis=0)
imp.fit(x)
#x1是处理缺失数据后的值
x1=imp.transform(x) y=data_dummies['income_ >50K'].values
x_train,x_test,y_train,y_test=train_test_split(x1,y,random_state=0)
cb=cb.CatBoostClassifier()
cb.fit(x_train,y_train)
print("logistic regression:")
print("accuracy on the training subset:{:.3f}".format(cb.score(x_train,y_train)))
print("accuracy on the test subset:{:.3f}".format(cb.score(x_test,y_test)))
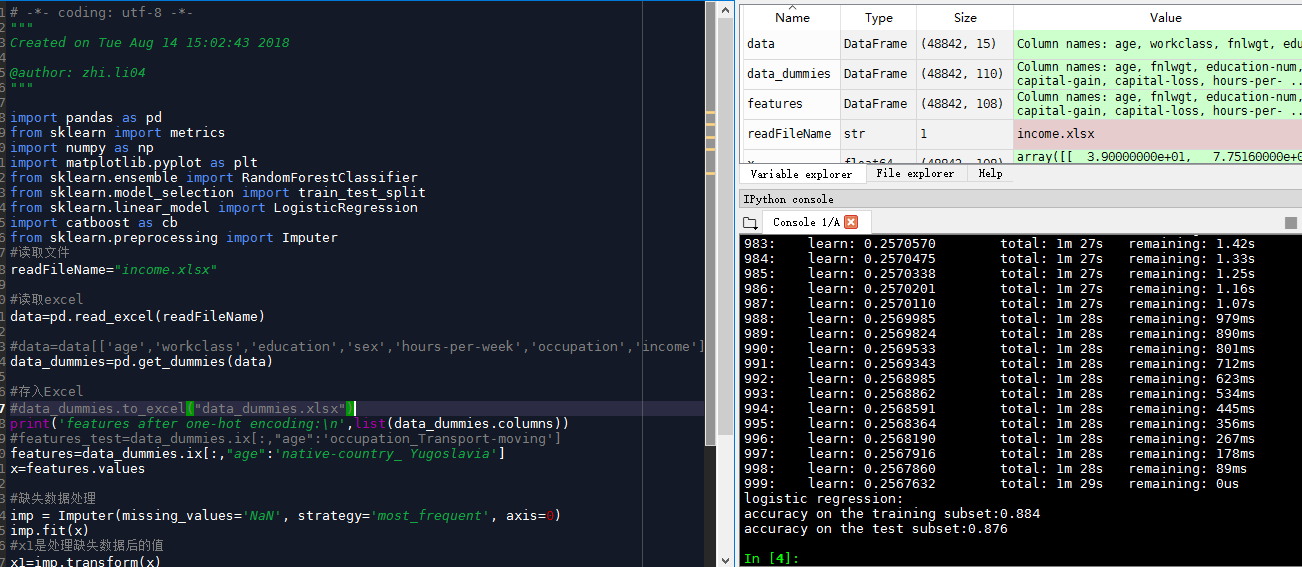
lightgbm1.py
准确性0.87左右
# -*- coding: utf-8 -*-
"""
Created on Tue Aug 14 15:24:14 2018 @author: zhi.li04
""" import pandas as pd
from sklearn import metrics
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
import catboost as cb
from xgboost import XGBClassifier
import lightgbm as lgb
from sklearn.preprocessing import Imputer
#读取文件
readFileName="income.xlsx" #读取excel
data=pd.read_excel(readFileName) #data=data[['age','workclass','education','sex','hours-per-week','occupation','income']]
data_dummies=pd.get_dummies(data) #存入Excel
#data_dummies.to_excel("data_dummies.xlsx")
print('features after one-hot encoding:\n',list(data_dummies.columns))
#features_test=data_dummies.ix[:,"age":'occupation_Transport-moving']
features=data_dummies.ix[:,"age":'native-country_ Yugoslavia']
x=features.values #缺失数据处理
imp = Imputer(missing_values='NaN', strategy='most_frequent', axis=0)
imp.fit(x)
#x1是处理缺失数据后的值
x1=imp.transform(x) y=data_dummies['income_ >50K'].values
x_train,x_test,y_train,y_test=train_test_split(x1,y,random_state=0)
clf=lgb.LGBMClassifier()
clf.fit(x_train,y_train)
print("logistic regression:")
print("accuracy on the training subset:{:.3f}".format(clf.score(x_train,y_train)))
print("accuracy on the test subset:{:.3f}".format(clf.score(x_test,y_test)))
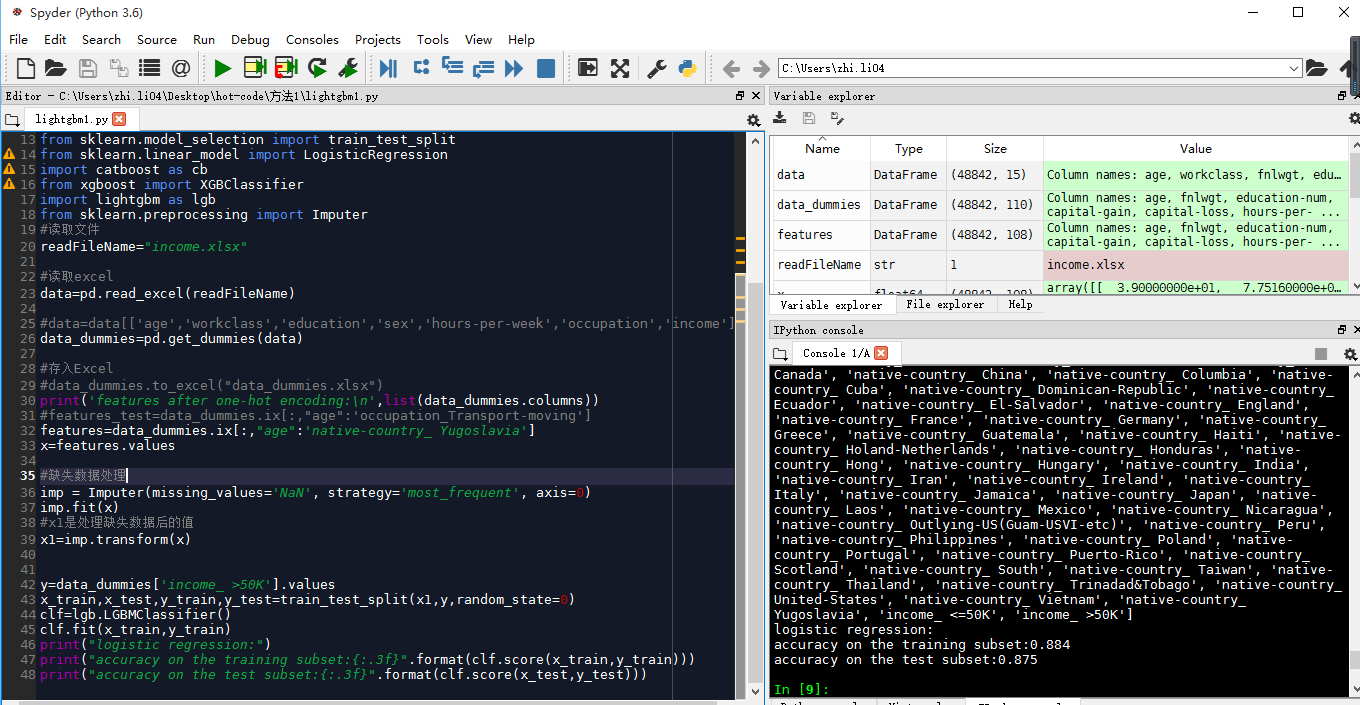
xgboost模型
准确率0.87左右
# -*- coding: utf-8 -*-
"""
Created on Tue Aug 14 15:13:17 2018 @author: zhi.li04
""" import pandas as pd
from sklearn import metrics
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
import catboost as cb
from xgboost import XGBClassifier
from sklearn.preprocessing import Imputer
#读取文件
readFileName="income.xlsx" #读取excel
data=pd.read_excel(readFileName) #data=data[['age','workclass','education','sex','hours-per-week','occupation','income']]
data_dummies=pd.get_dummies(data) #存入Excel
#data_dummies.to_excel("data_dummies.xlsx")
print('features after one-hot encoding:\n',list(data_dummies.columns))
#features_test=data_dummies.ix[:,"age":'occupation_Transport-moving']
features=data_dummies.ix[:,"age":'native-country_ Yugoslavia']
x=features.values #缺失数据处理
imp = Imputer(missing_values='NaN', strategy='most_frequent', axis=0)
imp.fit(x)
#x1是处理缺失数据后的值
x1=imp.transform(x) y=data_dummies['income_ >50K'].values
x_train,x_test,y_train,y_test=train_test_split(x1,y,random_state=0)
clf=XGBClassifier(n_estimators=1000)
clf.fit(x_train,y_train)
print("logistic regression:")
print("accuracy on the training subset:{:.3f}".format(clf.score(x_train,y_train)))
print("accuracy on the test subset:{:.3f}".format(clf.score(x_test,y_test)))
AUC: 0.9107
ACC: 0.8547
Recall: 0.5439
F1-score: 0.6457
Precesion: 0.7944
# -*- coding: utf-8 -*-
"""
Created on Tue Apr 24 22:42:47 2018 @author: Administrator
出现module 'xgboost' has no attribute 'DMatrix'的临时解决方法
初学者或者说不太了解Python才会犯这种错误,其实只需要注意一点!不要使用任何模块名作为文件名,任何类型的文件都不可以!我的错误根源是在文件夹中使用xgboost.*的文件名,当import xgboost时会首先在当前文件中查找,才会出现这样的问题。
所以,再次强调:不要用任何的模块名作为文件名!
"""
import xgboost as xgb
from sklearn.cross_validation import train_test_split
import pandas as pd
import matplotlib.pylab as plt #读取文件
readFileName="income.xlsx" #读取excel
data=pd.read_excel(readFileName)
#data=data[['age','workclass','education','sex','hours-per-week','occupation','income']]
data_dummies=pd.get_dummies(data)
print('features after one-hot encoding:\n',list(data_dummies.columns))
features=data_dummies.ix[:,"age":'native-country_Yugoslavia']
x=features.values
y=data_dummies['income_>50K'].values
x_train,x_test,y_train,y_test=train_test_split(x,y,random_state=0)
names=features.columns dtrain=xgb.DMatrix(x_train,label=y_train)
dtest=xgb.DMatrix(x_test) params={'booster':'gbtree',
#'objective': 'reg:linear',
'objective': 'binary:logistic',
'eval_metric': 'auc',
'max_depth':4,
'lambda':10,
'subsample':0.75,
'colsample_bytree':0.75,
'min_child_weight':2,
'eta': 0.025,
'seed':0,
'nthread':8,
'silent':1} watchlist = [(dtrain,'train')] bst=xgb.train(params,dtrain,num_boost_round=100,evals=watchlist) ypred=bst.predict(dtest) # 设置阈值, 输出一些评价指标
y_pred = (ypred >= 0.5)*1 #模型校验
from sklearn import metrics
print ('AUC: %.4f' % metrics.roc_auc_score(y_test,ypred))
print ('ACC: %.4f' % metrics.accuracy_score(y_test,y_pred))
print ('Recall: %.4f' % metrics.recall_score(y_test,y_pred))
print ('F1-score: %.4f' %metrics.f1_score(y_test,y_pred))
print ('Precesion: %.4f' %metrics.precision_score(y_test,y_pred))
metrics.confusion_matrix(y_test,y_pred)
'''
AUC: 0.9107
ACC: 0.8547
Recall: 0.5439
F1-score: 0.6457
Precesion: 0.7944
Out[28]:
array([[5880, 279],
[ 904, 1078]], dtype=int64)
''' print("xgboost:")
print('Feature importances:{}'.format(bst.get_fscore())) '''
Feature importances:{'f33': 76, 'f3': 273, 'f4': 157, 'f25': 11, 'f0': 167,
'f42': 34, 'f2': 193, 'f5': 132, 'f56': 1, 'f64': 14, 'f24': 11, 'f53': 15,
'f58': 24, 'f39': 2, 'f1': 20, 'f29': 3, 'f35': 9, 'f48': 20, 'f12': 11,
'f65': 3, 'f27': 3, 'f50': 3, 'f26': 7, 'f60': 2, 'f43': 8, 'f85': 1,
'f10': 1, 'f46': 5, 'f11': 1, 'f49': 1, 'f7': 1, 'f52': 3, 'f66': 1,
'f54': 1, 'f23': 1}
'''
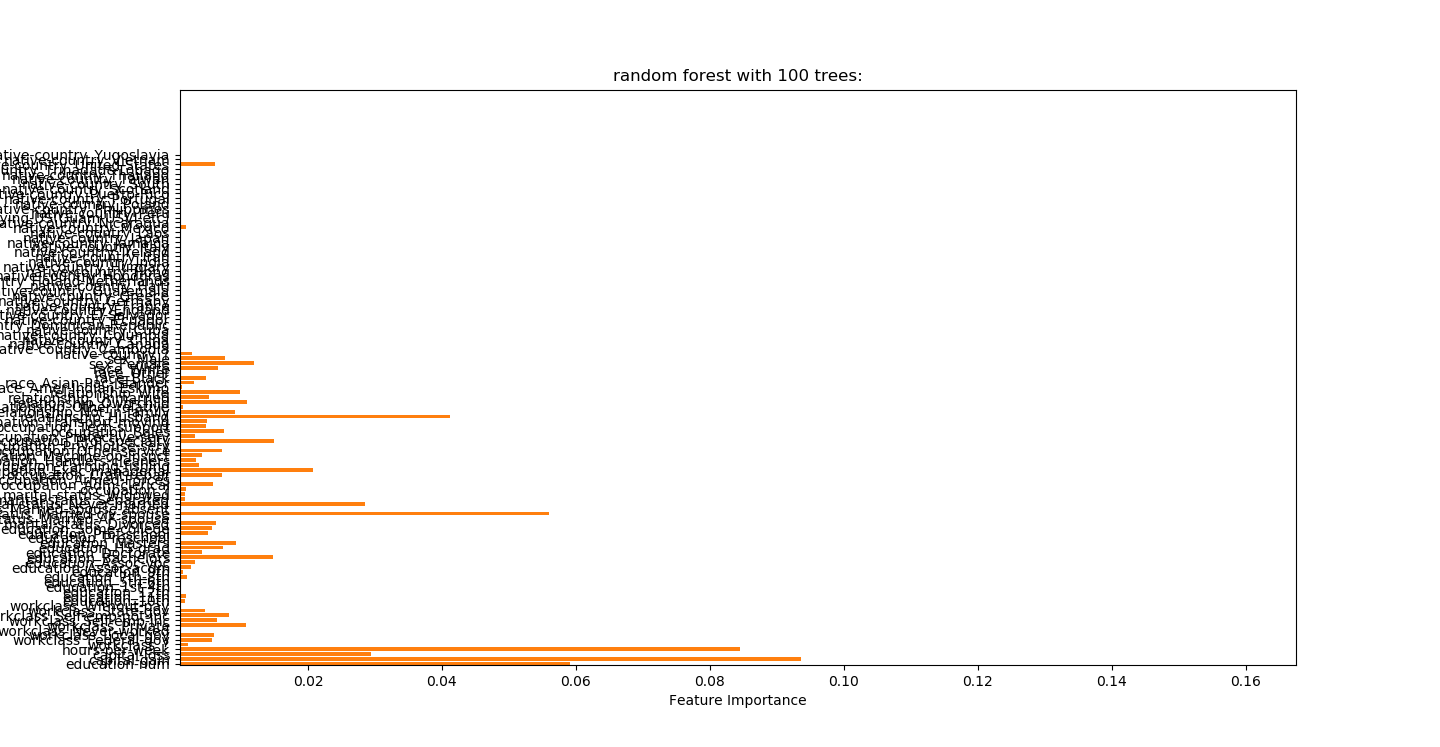
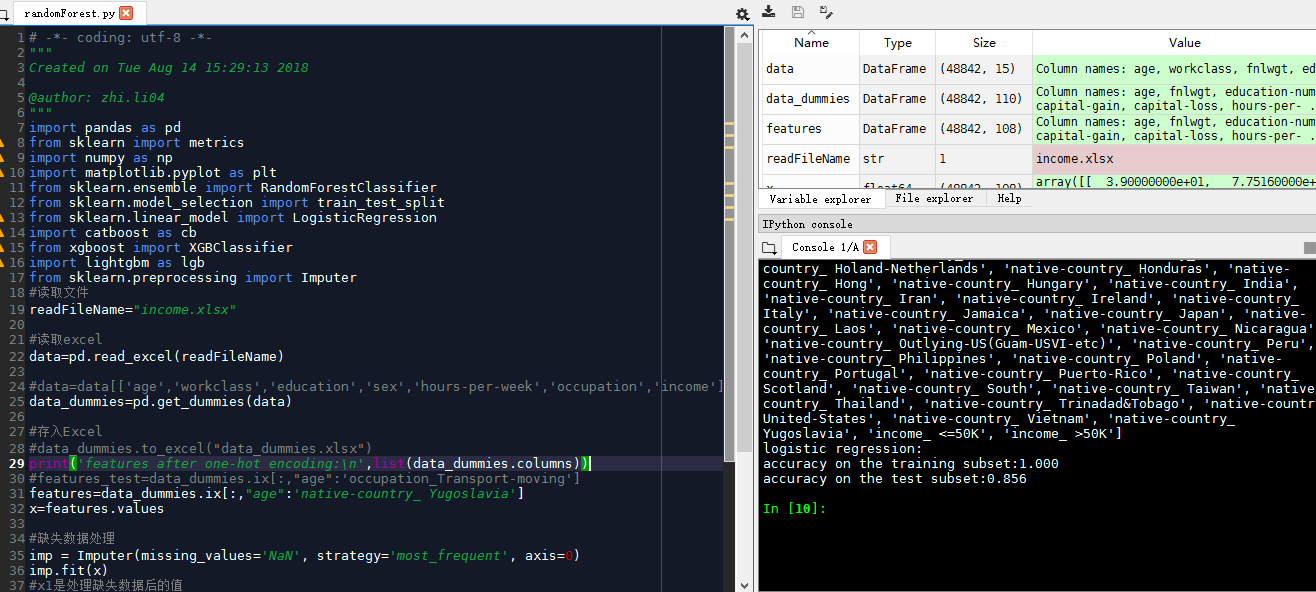
随机森林randomForest.py
0.856左右准确性
# -*- coding: utf-8 -*-
"""
Created on Tue Aug 14 15:29:13 2018 @author: zhi.li04
"""
import pandas as pd
from sklearn import metrics
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
import catboost as cb
from xgboost import XGBClassifier
import lightgbm as lgb
from sklearn.preprocessing import Imputer
#读取文件
readFileName="income.xlsx" #读取excel
data=pd.read_excel(readFileName) #data=data[['age','workclass','education','sex','hours-per-week','occupation','income']]
data_dummies=pd.get_dummies(data) #存入Excel
#data_dummies.to_excel("data_dummies.xlsx")
print('features after one-hot encoding:\n',list(data_dummies.columns))
#features_test=data_dummies.ix[:,"age":'occupation_Transport-moving']
features=data_dummies.ix[:,"age":'native-country_ Yugoslavia']
x=features.values #缺失数据处理
imp = Imputer(missing_values='NaN', strategy='most_frequent', axis=0)
imp.fit(x)
#x1是处理缺失数据后的值
x1=imp.transform(x) y=data_dummies['income_ >50K'].values
x_train,x_test,y_train,y_test=train_test_split(x1,y,random_state=0)
clf=RandomForestClassifier(n_estimators=1000,random_state=0)
clf.fit(x_train,y_train)
print("logistic regression:")
print("accuracy on the training subset:{:.3f}".format(clf.score(x_train,y_train)))
print("accuracy on the test subset:{:.3f}".format(clf.score(x_test,y_test)))
python风控建模实战lendingClub(博主录制,catboost,lightgbm建模,2K超清分辨率)
https://study.163.com/course/courseMain.htm?courseId=1005988013&share=2&shareId=400000000398149

微信扫二维码,免费学习更多python资源

sklearn_收入模型的更多相关文章
- 精通Web Analytics 2.0 (5) 第三章:点击流分析的奇妙世界:指标
精通Web Analytics 2.0 : 用户中心科学与在线统计艺术 第三章:点击流分析的奇妙世界:指标 新的Web Analytics 2.0心态:搞定它.新的闪亮系列工具:是的.准备好了吗?当然 ...
- 云计算服务模型,第 3 部分: 软件即服务(PaaS)
英文原文:Cloud computing service models, Part 3: Software as a Service 软件即服务 (SaaS) 为商用软件提供基于网络的访问.您有可能已 ...
- MaidSafe区块链项目白皮书解读
MaidSafe.net宣布项目SAFE到社区 1. 介绍 现有的互联网基础设施越来越难以应付超过24亿互联网用户的需求,这个数字在2017年预计将增长到36亿.今天的架构中,中央中介(服务器)存储并 ...
- html学习之二(常用标签练习)
<!DOCTYPE html><head> <meta charset="utf-8"> <title>锚点链接</title ...
- 增加收入的 6 种方式(很多公司的模型是:一份时间卖多次。比如网易、腾讯。个人赚取收入的本质是:出售时间)good
个人赚取收入的本质是:出售时间.从这个角度出发,下面的公式可以描述个人收入: 个人收入 = 每天可售时间数量 * 单位时间价格 * 单位时间出售次数 在这个公式里,有三个要素: 每天可出售的时间数量 ...
- sklearn_模型遍历
# _*_ coding = utf_8 _*_ import matplotlib.pyplot as plt import seaborn as sns import pandas as pd f ...
- 用R做逻辑回归之汽车贷款违约模型
数据说明 本数据是一份汽车贷款违约数据 application_id 申请者ID account_number 账户号 bad_ind 是否违约 vehicle_year ...
- R语言解读多元线性回归模型
转载:http://blog.fens.me/r-multi-linear-regression/ 前言 本文接上一篇R语言解读一元线性回归模型.在许多生活和工作的实际问题中,影响因变量的因素可能不止 ...
- 【再探backbone 01】模型-Model
前言 点保存时候不注意发出来了,有需要的朋友将就看吧,还在更新...... 几个月前学习了一下backbone,这段时间也用了下,感觉之前对backbone的学习很是基础,前几天有个园友问我如何将路由 ...
随机推荐
- pthread小结
参考1 https://computing.llnl.gov/tutorials/pthreads/ 参考2 http://man7.org/linux/man-pages/man7/pthreads ...
- 数据库原理 - 序列7 - Binlog与主从复制
本文节选自作者书籍<软件架构设计:大型网站技术架构与业务架构融合之道>.作者微信公众号:架构之道与术.公众号底部菜单有书友群可以加入,与作者和其他读者进行深入讨论.也可以在京东.天猫上购买 ...
- vue(3)—— vue的全局组件、局部组件
组件 vue有局部组件和全局组件,这个组件后期用的会比较多,也是非常重要的 局部组件 template与components属性结合使用挂载 其中 Vmain.Vheader.Vleft.Vconte ...
- 解析SQL Server之任务调度
在前面两篇文章中( 浅谈SQL Server内部运行机制 and 浅谈SQL Server数据内部表现形式 ),我们交流了一些关于SQL Server的一些术语,SQL Sever引擎 与SSMS抽象 ...
- sql 视图学习
视图语句 在 SQL 中,视图是基于 SQL 语句的结果集的可视化的表. 视图包含行和列,就像一个真实的表.视图中的字段就是来自一个或多个数据库中的真实的表中的字段. 您可以向视图添加 SQL 函数. ...
- centos7 永久添加静态路由
查看路由表 ip route show|column -t route -n 永久添加路由 vim /etc/sysconfig/network-scripts/route-ens224 via 17 ...
- Agent Job相关的系统表
参考: http://www.cnblogs.com/CareySon/p/5262311.html msdb中,有三张与Agent Job相关的系统表,需要了解一下 msdb.dbo.sysjobs ...
- vmware 14 新安装centos7 没法联网
vmware14 刚安装好centos7后,想下载安装一些软件发现无法联网,于是就百度了一下.下面 记录下解决方法. 1 确报主机能上网. 2 设置虚拟机网络适配器 3 设置虚拟机网卡 4 修改cen ...
- vue 利用mockJs 模拟数据
工作这几年一直用Java 开发,前端的技术自己也忘得差不多了(实际上自己也不怎么会),最近参与的项目是用VUE + Element-ui + springboot 写的,由于需求没有定,先画一个de ...
- LVM 磁盘分区扩容
前提:将磁盘中未分区磁盘进行分区操作 https://www.cnblogs.com/guoxiangyue/p/10033367.html 然后进行vg扩容 pvcreate /dev/sdc lv ...