K-means算法性能评估及其优化
1、 SSE误差平方和(Sum of Square due to Error):
聚类情况:
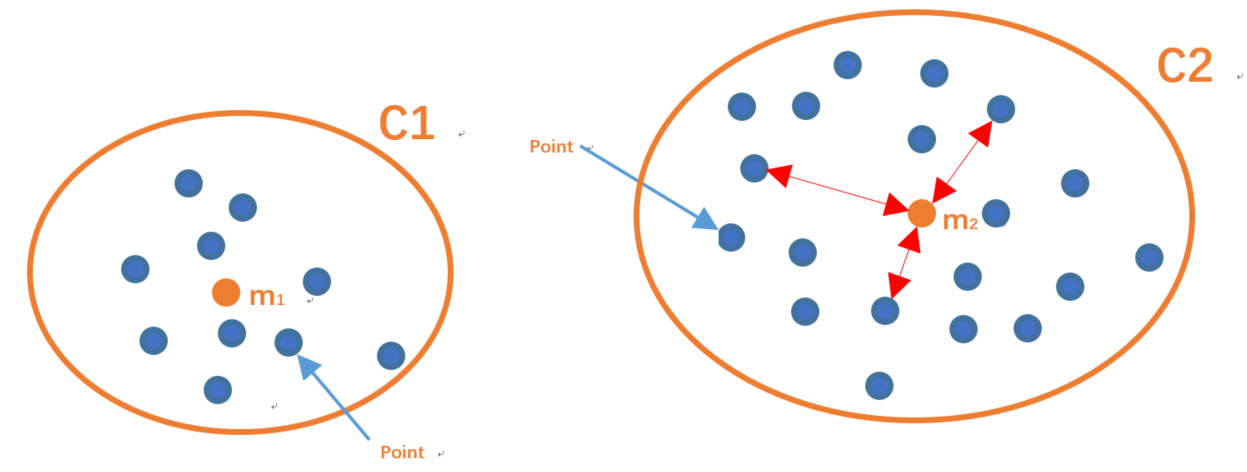
计算公式:
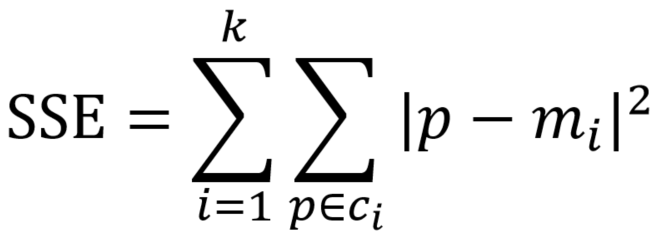
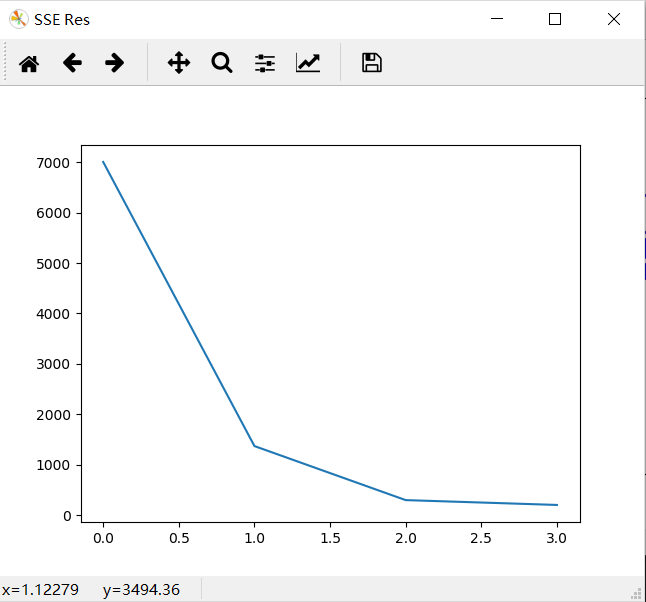
注:SSE参数计算的内容为当前迭代得到的中心位置到各自中心点簇的欧式距离总和,这个值越小表示当前的分类效果越好!
参数描述:
- P表示点位置(x,y)。
- Mi为中心点的位置。
- SSE表示了,当前的分类情况的中心点到自身分类簇的点的位置的总和。
使用方法:
在聚类算法迭代的过程中,我们通过计算当前得到的中心点情况下的SSE值来评估现在的分类效果,如果SSE值在某次迭代之后大大减小就说明聚类过程基本完成,不需要太多次的迭代了,
Code:
# K-means Algorithm processing the point
Point_Total = 100 # 某一种类型的总点数
Error_Threshold = 0.1 Point_A = (4, 3) # 高斯二维分布中心点
Point_S_A = (np.random.normal(Point_A[0], 1, Point_Total),np.random.normal(Point_A[1], 1, Point_Total)) # 构造高斯二维分布散点 Point_B = (-3,2) # 高斯二维分布中心点
Point_S_B = (np.random.normal(Point_B[0], 1, Point_Total),np.random.normal(Point_B[1], 1, Point_Total)) # 构造高斯二维分布散点 Point_O = np.hstack((Point_S_A,Point_S_B)) # 所有的点合并在一起 Origin_A = [Point_O[0][0],Point_O[1][0]] # 取得K-means算法的起始分类点
Origin_B = [Point_O[0][20],Point_O[1][20]] # 设置K-means算法的起始分类点 plt.figure("实时分类") # 创建新得显示窗口
plt.ion() # 持续刷新当前窗口的内容,不需要使用plt.show()函数
plt.scatter(Point_O[0],Point_O[1],c='k') # 所有的初始数据显示为黑色
plt.scatter(Origin_A[0],Origin_A[1],c='b',marker='D') # 显示第一类分类点的位置
plt.scatter(Origin_B[0],Origin_B[1],c='r',marker='*') # 显示第二类分类点的位置 Status_A = False # 设置A类别分类未完成False
Status_B = False # 设置B类别分类未完成False CiSum_List = []
while not Status_A and not Status_B: # 开始分类
Class_A = [] # 分类结果保存空间
Class_B = [] # 分类结果保存空间
print("Seperating the point...")
CASum = 0
CBSum = 0
for i in range(Point_Total*2): # 开始计算分类点到所有点的欧式距离(注意只需要使用平方和即可,不需要sqrt浪费时间)
d_A = np.power(Origin_A[0]-Point_O[0][i], 2) + np.power(Origin_A[1]-Point_O[1][i], 2) # 计算距离
d_B = np.power(Origin_B[0]-Point_O[0][i], 2) + np.power(Origin_B[1]-Point_O[1][i], 2) # 计算距离
if d_A > d_B:
Class_B.append((Point_O[0][i],Point_O[1][i])) # 将距离当前点较近的数据点包含在自己的空间中
plt.scatter(Point_O[0][i],Point_O[1][i],c='r') # 更新新的点的颜色
CBSum += d_B
else:
Class_A.append((Point_O[0][i],Point_O[1][i])) # 将距离当前点较近的数据点包含在自己的空间中
plt.scatter(Point_O[0][i],Point_O[1][i],c='b') # 更新新的点的颜色
CASum =+ d_A
plt.pause(0.08) # 显示暂停0.08s CiSum = CASum + CBSum
CiSum_List.append(CiSum) # 统计计算SSE的值 A_Shape = np.shape(Class_A)[0] # 取得当前分类为A集合的点的总数
B_Shape = np.shape(Class_B)[0] # 取得当前分类为B集合的点的总数
Temp_x = 0
Temp_y = 0
for p in Class_A: # 计算A集合的质心
Temp_x += p[0]
Temp_y += p[1]
error_x = np.abs(Origin_A[0] - Temp_x/A_Shape) # 求平均得到重心-质心
error_y = np.abs(Origin_A[1] - Temp_y/A_Shape)
print("The error Of A:(",error_x,",",error_y,")") # 显示当前位置和质心的误差
if error_x < Error_Threshold and error_y < Error_Threshold:
Status_A = True # 误差满足设定的误差阈值范围,将A集合的状态设置为OK-True
else:
Origin_A[0] = Temp_x/A_Shape # 求平均得到重心-质心
Origin_A[1] = Temp_y/A_Shape
plt.scatter(Origin_A[0],Origin_A[1],c='g',marker='*') # the Map-A
print("Get New Center Of A:(",Origin_A[0],",",Origin_A[1],")") # 显示中心坐标点 Temp_x = 0
Temp_y = 0
for p in Class_B: # 计算B集合的质心
Temp_x += p[0]
Temp_y += p[1]
error_x = np.abs(Origin_B[0] - Temp_x/B_Shape) # 求平均得到重心-质心
error_y = np.abs(Origin_B[1] - Temp_y/B_Shape)
print("The error Of B:(",error_x,",",error_y,")")
if error_x < Error_Threshold and error_y < Error_Threshold:
Status_B = True # 误差满足设定的误差阈值范围,将B集合的状态设置为OK-True
else:
Origin_B[0] = Temp_x/B_Shape # 求平均得到重心-质心
Origin_B[1] = Temp_y/B_Shape
plt.scatter(Origin_B[0],Origin_B[1],c='y',marker='x') # the Map-B
print("Get New Center Of B:(",Origin_B[0],",",Origin_B[1],")") # 显示中心坐标点 print("Finished the divide!")
print(CiSum_List) # 统计结果
plt.figure("真实分类")
plt.scatter(Point_S_A[0],Point_S_A[1]) # The Map-A
plt.scatter(Point_S_B[0],Point_S_B[1]) # The Map-A
plt.show() plt.figure("SSE Res")
plt.plot(CiSum_List) # 绘制SSE结果图 plt.pause(15)
plt.show()
结果:
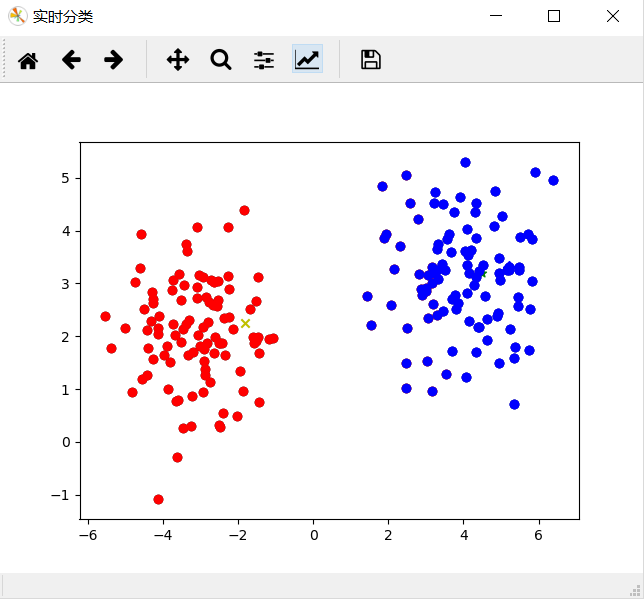
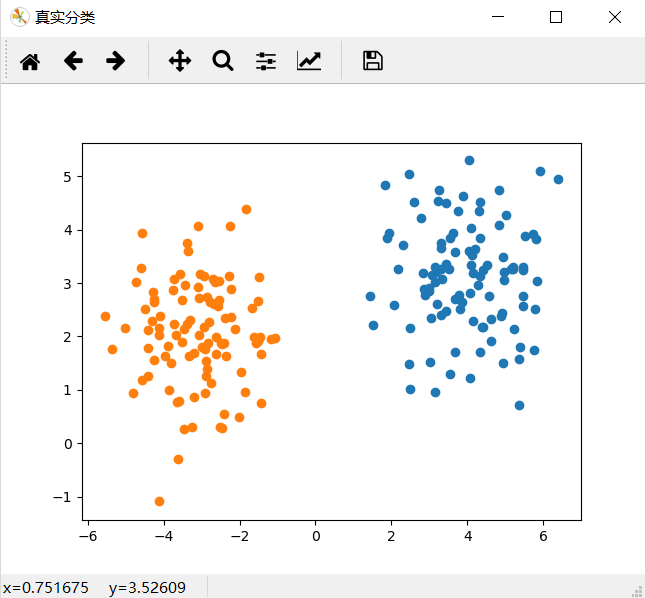
2、 SC系数(Silhouette Cofficient)轮廓系数法:
评估标准描述:结合了聚类的凝聚度(Cohesion)和分离度(Separation),用于评估聚类算法的效果。
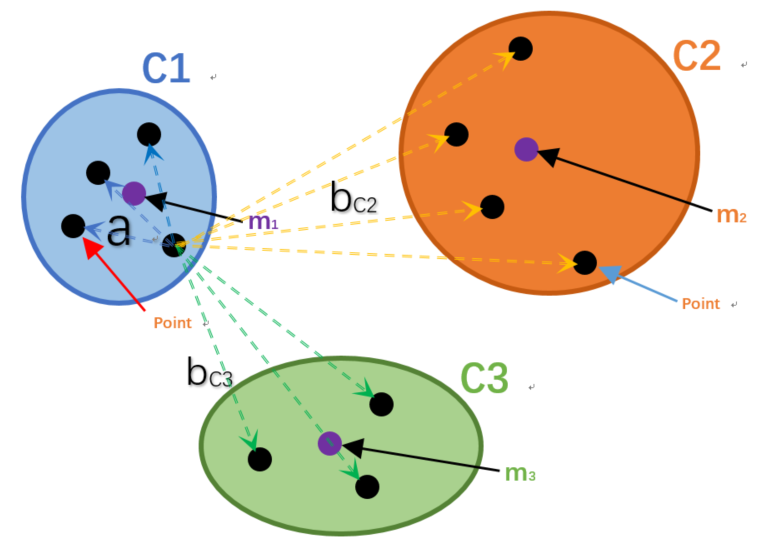
参数描述:
- a表示C1簇中的某一个样本点Xi到自身簇中其他样本点的距离总和的平均值。
- bC2表示样本点Xi 到C2簇中所有样本点的距离总和的平均值。
- bC3表示样本点Xi 到C3簇中所有样本点的距离总和的平均值。
- 我们定义b = min(bC2 ,bC3)
计算公式:
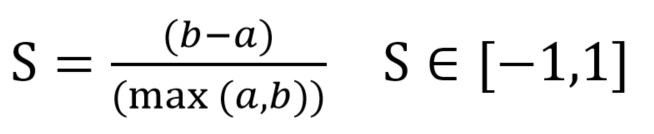
- a:样本Xi到同一簇内其他点不相似程度的平均值
- b:样本Xi到其他簇的平均不相似程度的最小值
使用方法:
每次聚类之后,每一个样本点都会得到一个轮廓系数,当S的取值越靠近1,当前点与周围簇距离较远,结果非常好。
当S的取值为0,说明当前点可能处在两个簇的边界上。
当S的取值为负数时,可能这个点呗误分了。
求出所有样本点的轮廓系数之后再求平均值就得到了平均轮廓系数,平均轮廓系数越大,簇内样本距离越近,簇间样本距离越远,聚类效果越好。
Code:
3、CH系数(Calinski Harabasz Index)轮廓系数法:
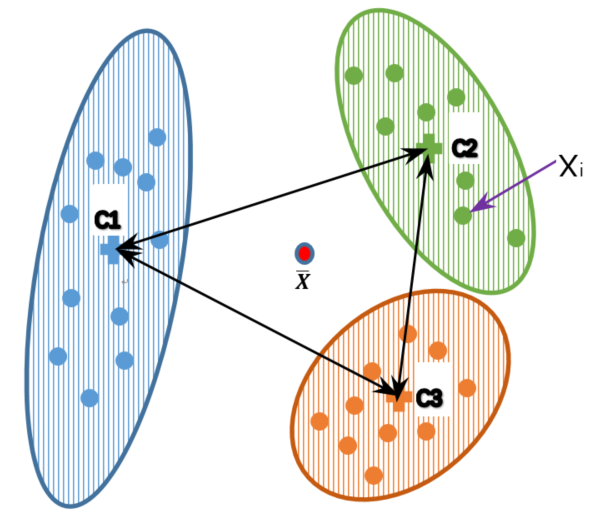
参数描述:
- C1:簇1的中心位置
- C2:簇2的中心位置
- C3:簇3的中心位置
- Xi:簇当中的某一个样本点
- X平均:所有簇当中的样本点的中心位置
计算公式:
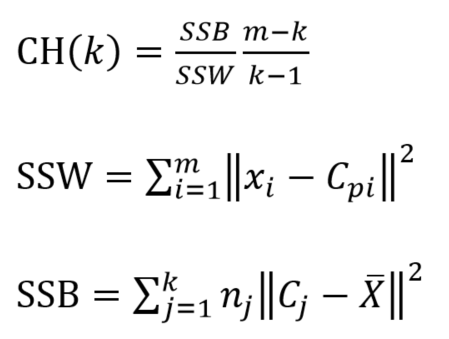

使用方法:
Code:
4、总结:
在我们考量当前的聚类算法的K值选择的问题是,我们会总和汇总上述三种衡量系数来共同确定K值的选择,使得我们选择最好的K值。
如下实例过程,我们来选择合适的K值:
Code:
Result:
分析:
K-means算法性能评估及其优化的更多相关文章
- [转载]Linux服务器性能评估与优化
转载自:Linux服务器性能评估与优化 一.影响Linux服务器性能的因素 1. 操作系统级 CPU 内存 磁盘I/O带宽 网络I/O带宽 2. 程序应用级 二.系统性能评估标准 影响性 ...
- Linux服务器性能评估与优化--转
http://www.itlearner.com/article/4553 一.影响Linux服务器性能的因素 1. 操作系统级 Ø CPU Ø 内存 Ø 磁盘I/ ...
- Linux服务器性能评估与优化(一)
网络内容总结(感谢原创) 1.前言简介 一.影响Linux服务器性能的因素 1. 操作系统级 性能调优是找出系统瓶颈并消除这些瓶颈的过程. 很多系统管理员认为性能调优仅仅是调整一下 ...
- Linux服务器性能评估与优化
一.影响务器性能因素 影响企业生产环境Linux服务器性能的因素有很多,一般分为两大类,分别为操作系统层级和应用程序级别.如下为各级别影响性能的具体项及性能评估的标准: (1)操作系统级别 内存: C ...
- Linux转发性能评估与优化-转发瓶颈分析与解决方式(补遗)
补遗 关于网络接收的软中断负载均衡,已经有了成熟的方案,可是该方案并不特别适合数据包转发,它对server的小包处理非常好.这就是RPS.我针对RPS做了一个patch.提升了其转发效率. 下面是我转 ...
- Linux转发性能评估与优化(转发瓶颈分析与解决方式)
线速问题 非常多人对这个线速概念存在误解. 觉得所谓线速能力就是路由器/交换机就像一根网线一样. 而这,是不可能的.应该考虑到的一个概念就是延迟. 数据包进入路由器或者交换机,存在一个核心延迟操作,这 ...
- KNN 与 K - Means 算法比较
KNN K-Means 1.分类算法 聚类算法 2.监督学习 非监督学习 3.数据类型:喂给它的数据集是带label的数据,已经是完全正确的数据 喂给它的数据集是无label的数据,是杂乱无章的,经过 ...
- Linux服务器性能评估与优化(二)
网络内容总结(感谢原创) 1.Linux内核参数优化 内核参数是用户和系统内核之间交互的一个接口,通过这个接口,用户可以在系统运行的同时动态更新内核配置,而这些内核参数是通过Linux Proc文件系 ...
- Linux服务器性能评估
一.影响Linux服务器性能的因素 1. 操作系统级 CPU 内存 磁盘I/O带宽 网络I/O带宽 2. 程序应用级 二.系统性能评估标准 影响性能因素 影响性能因素 评判标准 好 坏 糟糕 CPU ...
随机推荐
- MySQL_写锁_lock tables tableName write
pre.环境准备 1.建立两个表S,T,并插入一些数据 --创建表S create table S(d int) engine=innodb; ); --创建表T create table T(c i ...
- Haproxy 安装及配置
Haproxy介绍 HAProxy是一个特别适用于高可用性环境的TCP/HTTP开源的反向代理和负载均衡软件.实现了一种事件驱动,单一进程模型,支持非常大的并发连接,是因为事件驱动模型有更好的资源和时 ...
- 前端面试题整理—React篇
1.说一下React React是Facebook 开发的前端JavaScript库 V层:react并不是完整的MVC框架,而是MVC中的C层 虚拟DOM:react引入虚拟DOM,每当数据变化通过 ...
- 077、跨主机使用Rex-Ray volume (2019-04-24 周三)
参考https://www.cnblogs.com/CloudMan6/p/7630205.html 上一节我们在docker1上创建mysql容器,并使用了 Rex-Ray volume mys ...
- [Android] Android 最全 Intent 传递数据姿势
我们都是用过 Intent,用它来在组件之间传递数据,所以说 Intent 是组件之间通信的使者,一般情况下,我们传递的都是一些比较简单的数据,并且都是基本的数据类型,写法也比较简单,今天我在这里说的 ...
- 一次多个数据库tnsping及登录单点登录需求
[环境介绍] 系统环境:Linux + Oracle 11.2.0.4.0 + python 2.7.10 [背景描述] 需求:因为涉及生产数据库较多,业务夸多个数据库使用.当收到业务有些影响时,数据 ...
- 如何运用jieba库分词
使用jieba库分词 一.什么是jieba库 1.jieba库概述 jieba是优秀的中文分词第三方库,中文文本需要通过分词获得单个词语. 2.jieba库的使用:(jieba库支持3种分词模式) 通 ...
- 使用scrapy选择器selector解析获取百度结果
0x00 概述 需要成功安装scrapy,安装方法与本文无关,不在这多说. 0x01 配置settings 由于百度对于user-agent进行验证,所以需要添加. settings.py中找到DEF ...
- HDU-6031 Innumerable Ancestors(二分+树上倍增)
题意 给一棵树,$m$次询问,每次询问给两个点集问从两个点集中各取一个点的$LCA$的最大深度. 思路 二分答案.对于某个二分过程中得到的$Mid$,如果可行则两个点集在$Mid$所在的深度存在公共的 ...
- redis基础篇
1.redis常见的数据结构 redis是一种以键值对存储的高性能内存数据库,有五种常用的数据类型,string,list,hash,set,zset. 2.redis的过期时间 redis中的key ...