寻找U2OS中表达的基因及其promoter并用于后续annotation
方法1.RNA-seq得到不同表达程度基因
方法2. 直接download U2OS_gene.csv https://cancer.sanger.ac.uk/cell_lines/download
最开始excel直接选用25%最高和25%最低,U2OS细胞共~16000基因,故复制前4000行的gene symbol并存为txt;
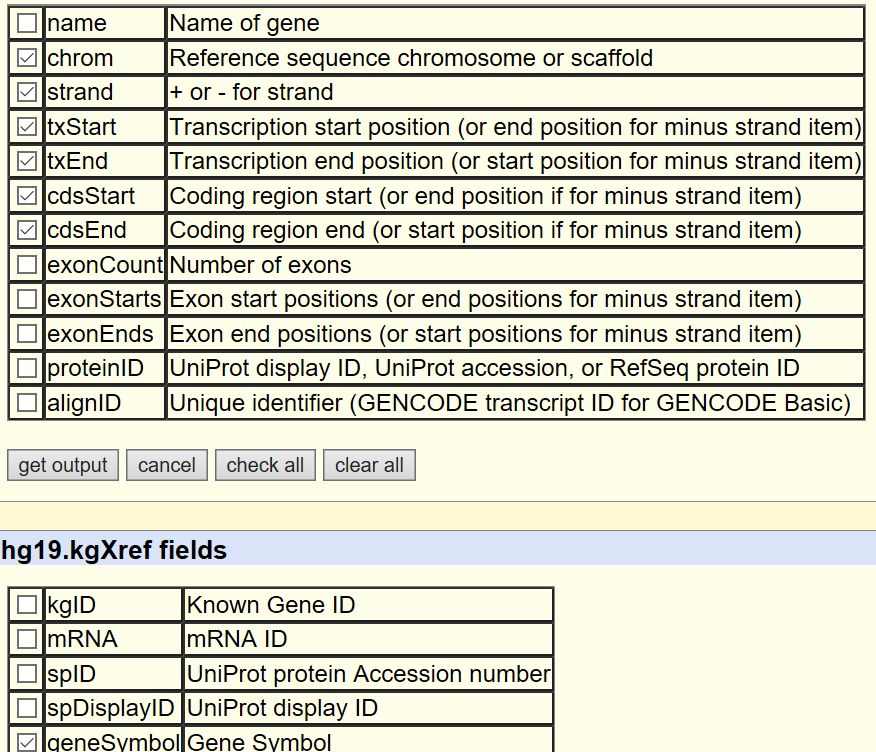
table browser下载'group:Genes and gene prediction; track:UCSC genes; outpu format:selected fileds from primary and related tables' then getoutput,如下图选择
问题出现在grep -wFf 25%_most_highly_expressed_gene_name.txt hg19_geneid_genesymbol.txt > 25%_most_highly_expressed_geneid.txt总是没有输出
trouble shooting首先检查代码,自定义两个文件1.txt 2.txt然后 grep -wFf 1.txt 2.txt成功;
然后检查输入文件hg19_geneid_genesymbol.txt,自定义基因文件(随便选几个U2OS/non-U2OS基因 vi gene.txt),grep -wFf gene.txt hg19_geneid_genesymbol.txt成功;
最后发现问题出在25%_most_highly_expressed_gene_name.txt,最开始得到这个文件是直接从csv中copy and paste,但csv是 comma delimited,所以复制事实上连,一起复制了
#$ head U2OS_genes.csv

#$ head 25%_most_highly_expressed_gene_name.txt

事实上在做grep的时候是“ ,MED6, ”,因此无法匹配 hg19_geneid_genesymbol.txt,这也是为什么grep 'MED6' hg19_geneid_genesymbol.txt 可以work的原因
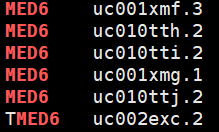
正确做法
#0.6是第4000个基因的zscore
awk -F',' '$5 > 0.6 {print $3}' U2OS_genes.csv > 25%_most_highly_expressed_gene_name.txt
0.6有点过低,做zscore散点图可发现用2更为合理
awk -F',' '$5 > 2 {print $3}' U2OS_genes.csv > highest_expressed_gene_name.txt

更为准确的方法是用R quantile得到合适Z score筛选得到most_expressed 和 least_expressed
grep -wFf highest_expressed_genesym.txt gene_hg19.bed > highest_expressed_gene.bed
PS:head gene_hg19.bed


一个基因有不同的cds
https://www.jianshu.com/p/cc5cd7053d6e
寻找U2OS中表达的基因及其promoter并用于后续annotation的更多相关文章
- 逆向知识第八讲,if语句在汇编中表达的方式
逆向知识第八讲,if语句在汇编中表达的方式 一丶if else的最简单情况还原(无分支情况) 高级代码: #include "stdafx.h" int main(int argc ...
- 寻找数组中的第K大的元素,多种解法以及分析
遇到了一个很简单而有意思的问题,可以看出不同的算法策略对这个问题求解的优化过程.问题:寻找数组中的第K大的元素. 最简单的想法是直接进行排序,算法复杂度是O(N*logN).这么做很明显比较低效率,因 ...
- 利用Manacher算法寻找字符串中的最长回文序列(palindrome)
寻找字符串中的最长回文序列和所有回文序列(正向和反向一样的序列,如aba,abba等)算是挺早以前提出的算法问题了,最近再刷Leetcode算法题的时候遇到了一个(题目),所以就顺便写下. 如果用正反 ...
- 实现一个算法,寻找字符串中出现次数最少的、并且首次出现位置最前的字符 如"cbaacfdeaebb",符合要求的是"f",因为他只出现了一次(次数最少)。并且比其他只出现一次的字符(如"d")首次出现的位置最靠前。
实现一个算法,寻找字符串中出现次数最少的.并且首次出现位置最前的字符如"cbaacfdeaebb",符合要求的是"f",因为他只出现了一次(次数最少).并且比其 ...
- [经典算法题]寻找数组中第K大的数的方法总结
[经典算法题]寻找数组中第K大的数的方法总结 责任编辑:admin 日期:2012-11-26 字体:[大 中 小] 打印复制链接我要评论 今天看算法分析是,看到一个这样的问题,就是在一堆数据 ...
- 寻找数组中第K大数
1.寻找数组中的第二大数 using System; using System.Collections.Generic; using System.Linq; using System.Text; u ...
- C语言中表达n次方
C语言中表达n次方可以用pow函数. 函数原型:double pow(double x, double y) 功 能:计算x^y的值 返 回 值:计算结果 举例: double a; a = p ...
- Java实现 蓝桥杯 算法训练 寻找数组中最大值
算法训练 寻找数组中最大值 时间限制:1.0s 内存限制:512.0MB 提交此题 问题描述 对于给定整数数组a[],寻找其中最大值,并返回下标. 输入格式 整数数组a[],数组元素个数小于1等于10 ...
- WPF:指定的命名连接在配置中找不到、非计划用于 EntityClient 提供程序或者无效的解决方法
文/嶽永鹏 WPF 数据绑定中绑定到ENTITY,如果把数据文件做成一个类库,在UI文件中去应用它,可能遇到下面这种情况. 指定的命名连接在配置中找不到.非计划用于 EntityClient 提供程序 ...
随机推荐
- jmeter之JDBC Request各种数据库配置
URL和JDBC驱动: Datebase Driver class Database URL MySQL com.mysql.jdbc.Driver jdbc:mysql://host:port/{d ...
- DWM1000 三基站一标签定位HEX
蓝点DWM1000 模块已经打样测试完毕,有兴趣的可以申请购买了,更多信息参见 蓝点论坛 HEX 下载链接参见论坛:http://bphero.com.cn/forum.php?mod=viewthr ...
- js小笔记
1.let ,const,var 区别 let:块级作用域,if,for,用完就不存在了. const:用来定义常量. var: 声明的变量在它所声明的整个函数都是可见的. 2.==和===的区别 1 ...
- css 控制文字显示两行,多余用省略号 手机端
p { width:100px; position:relative; line-height:20px; /*行高为高度的一半,这样就是两行*/ height:40px; overflow:hidd ...
- 日期求星期(java)-蓝桥杯
日期求星期问题(java)-蓝桥杯 1:基姆拉尔森计算公式(计算星期) 公式: int week = (d+2*m+3*(m+1)/5+y+y/4-y/100+y/400)%7; 此处y,m,d指代年 ...
- What's the meaning of unqualified-id?
catch( const std::runtime_error & e) { .... } When compile, met an error: error: expected unqual ...
- Windows 安装JDK
Windows 安装JDK jdk为java开发工具,jre为java运行环境,安装一个jdk版本会把两个一起装 步骤: 1.在官网下载jdk:http://www.oracle.com/techne ...
- day26:静态方法,类方法和反射
1,包内部不要去尝试应用使用相对导入,一定不会成功的,他不支持这个机制,包内导入时一定要用绝对导入 2,复习接口类,抽象类,Python中没有接口类,有抽象类,抽象类是通过abc模块中的metacla ...
- python转换图片格式
在图片所在的路径下,打开命令窗口 bmeps -c picturename.png picturename.eps
- C# Asp.net中简单操作MongoDB数据库(二)
C# Asp.net中简单操作MongoDB数据库(一) , mongodb数据库连接可以回顾上面的篇幅. 1.model类: public class BaseEntity { /// < ...