Python四步实现决策树ID3算法,参考机器学习实战
一、编写计算历史数据的经验熵函数
from math import log
def calcShannonEnt(dataSet):
numEntries = len(dataSet)
labelCounts = {}
for elem in dataSet: #遍历数据集中每条样本的类别标签,统计每类标签的数量
currentLabel = elem[-1]
if currentLabel not in labelCounts.keys(): #如果当前标签不在字典的key值中,则初始化该标签对应的值为0
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1 #计数+1
shannonEnt = 0.0
for key in labelCounts:#开始计算历史数据的经验熵
prob = float(labelCounts[key])/numEntries#每类标签在全部历史数据中所占概率
shannonEnt -= prob * log(prob,2) #log base 2
return shannonEnt
二、按照指定特征和其特征值来划分数据集
参数axis指定是第几个特征,value是该特征什么值,这个函数会在第三步的函数和第四步里被调用,主要作用在相应步结束后介绍
def splitDataSet(dataSet, axis, value):
retDataSet = []
for elem in dataSet:
if elem[axis] == value:
reducedFeatElem=elem[:axis]
reducedFeatElem.extend(elem[axis+1:])
retDataSet.append(reducedFeatElem)
return retDataSet
三、计算每个特征的熵,求得信息增益,返回使得信息增益最大的特征
比较难理解的就是第二个for迭代中的内容,会在这个函数编写结束后解释,其他的解释就直接注释在代码中了
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) - 1 #统计特征数目
baseEntropy = calcShannonEnt(dataSet) #计算历史数据的经验熵
bestInfoGain = 0.0; bestFeature = -1
for i in range(numFeatures): #迭代所有特征
featList = [sample[i] for sample in dataSet]#创建所有样本中每一个样本的这个特征的取值
uniqueVals = set(featList) #获得该特征的取值集合,即剔除重复的特征取值
newEntropy = 0.0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet)/float(len(dataSet))
newEntropy += prob * calcShannonEnt(subDataSet)#按照条件经验熵熵的公式计算i列特征取值为value的条件下的条件经验熵
infoGain = baseEntropy - newEntropy #计算信息增益
if (infoGain > bestInfoGain): #与目前最大的信息增益比较
bestInfoGain = infoGain #更新最大信息增益
bestFeature = i #更新使得信息增益最大的特征列i
return bestFeature #returns an integer
chooseBestFeatureToSplit函数调用splitDataSet的作用就是获得axis列特征的取值为value的样本,splitDataSet函数返回值长度用于计算axis列特征取值为value时的样本占全部样本数量的概率,返回值作为参数传递给calcShannonEnt函数可以计算axis列特征取值为value时的经验熵
四、递归构建决策树
递归结束的条件是:程序已经遍历完样本数据的全部特征列或者所有实例样本属于同一类(即标签类别相同)
另外,如果所有实例样本标签类别相同则得到一个叶子节点
(一)定义叶子节点中的实例类别
主要是当划分数据集的全部属性已经处理完,该叶子节点中的实例样本的类别标签不是唯一的,如何定义该叶子节点的最终类别,此时采用多数表决的方法决定
import operator
def majorityCnt(classList):
classCount={}
for classlabel in classList:
if classlabel not in classCount.keys():
classCount[classlabel] = 0
classCount[vote] += 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
(二)、构造决策树
参数dataSet为传入的数据集,labels为特征名
def createTree(dataSet,labels):
classList = [example[-1] for example in dataSet]#获取传入数据集的类别标签列表
if classList.count(classList[0]) == len(classList): #当传入数据集的类且标签全部相同时停止递归
return classList[0]
if len(dataSet[0]) == 1: #当传入的数据集只剩一个标签列时(每次调用划分数据集函数splitDataSet时都会删除一个特征列)停止递归
return majorityCnt(classList) #返回标签列表中类别数量最多的类别
bestFeat = chooseBestFeatureToSplit(dataSet) #调用chooseBestFeatureToSplit选择最优特征
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel:{}} #使用字典存储每次迭代中的最优特征
del(labels[bestFeat])
featValues = [sample[bestFeat] for sample in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels[:] #copy all of labels, so trees don't mess up existing labels
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value),subLabels)
return myTree
createTree函数难理解的部分在for迭代里,作用就是对于当前最优特征的不同取值构建分支,每一个特征取值可以构建出一个分支,具体是利用for循环对于当前最优特征的每个取值value下,递归调用createTree函数,参数为调用splitDataSet函数(以当前最优特征列,以及最优特征取值作为参数)返回dataSet中满足最优特征对应的列取值为value剔除了该最优特征列的样本数据集
def createDataSet():
dataSet = [[1, 1, 'yes'],
[1, 1, 'yes'],
[1, 0, 'no'],
[0, 1, 'no'],
[0, 1, 'no']]
labels = ['no surfacing','flippers']
#change to discrete values
return dataSet, labels
测试:
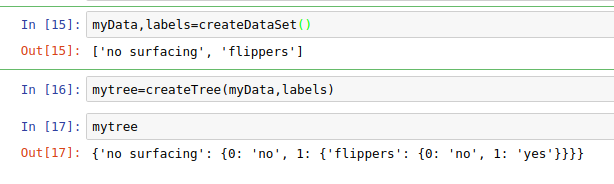
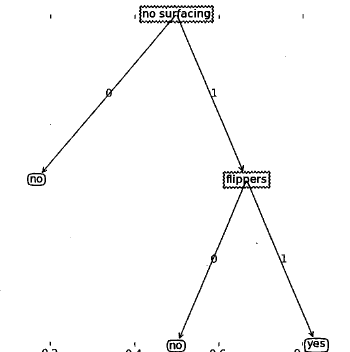
mytree字典的含义如图:
五、利用以上实现的算法实现决策树分类,需要递归遍历整棵决策树
def classify(inputTree,featLabels,testVec):
firstStr = inputTree.keys()[0]
secondDict = inputTree[firstStr]
featIndex = featLabels.index(firstStr)#为了确定某个特征在数据集的位置
key = testVec[featIndex]
valueOfFeat = secondDict[key]
if isinstance(valueOfFeat, dict):
classLabel = classify(valueOfFeat, featLabels, testVec)
else: classLabel = valueOfFeat
return classLabel
测试:
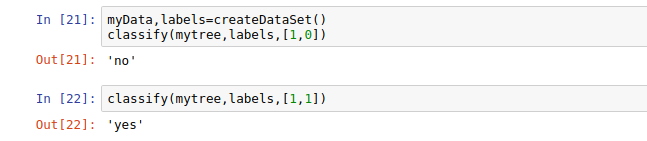
对应数据集标签可以看到分类正确,结束啦^.^
Python四步实现决策树ID3算法,参考机器学习实战的更多相关文章
- 机器学习之决策树(ID3)算法与Python实现
机器学习之决策树(ID3)算法与Python实现 机器学习中,决策树是一个预测模型:他代表的是对象属性与对象值之间的一种映射关系.树中每个节点表示某个对象,而每个分叉路径则代表的某个可能的属性值,而每 ...
- 决策树---ID3算法(介绍及Python实现)
决策树---ID3算法 决策树: 以天气数据库的训练数据为例. Outlook Temperature Humidity Windy PlayGolf? sunny 85 85 FALSE no ...
- 02-21 决策树ID3算法
目录 决策树ID3算法 一.决策树ID3算法学习目标 二.决策树引入 三.决策树ID3算法详解 3.1 if-else和决策树 3.2 信息增益 四.决策树ID3算法流程 4.1 输入 4.2 输出 ...
- 数据挖掘之决策树ID3算法(C#实现)
决策树是一种非常经典的分类器,它的作用原理有点类似于我们玩的猜谜游戏.比如猜一个动物: 问:这个动物是陆生动物吗? 答:是的. 问:这个动物有鳃吗? 答:没有. 这样的两个问题顺序就有些颠倒,因为一般 ...
- 决策树ID3算法[分类算法]
ID3分类算法的编码实现 <?php /* *决策树ID3算法(分类算法的实现) */ /* *求信息增益Grain(S1,S2) */ //-------------------------- ...
- 决策树ID3算法--python实现
参考: 统计学习方法>第五章决策树] http://pan.baidu.com/s/1hrTscza 决策树的python实现 有完整程序 决策树(ID3.C4.5.CART ...
- 机器学习决策树ID3算法,手把手教你用Python实现
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是机器学习专题的第21篇文章,我们一起来看一个新的模型--决策树. 决策树的定义 决策树是我本人非常喜欢的机器学习模型,非常直观容易理解 ...
- Python两步实现关联规则Apriori算法,参考机器学习实战,包括频繁项集的构建以及关联规则的挖掘
.caret, .dropup > .btn > .caret { border-top-color: #000 !important; } .label { border: 1px so ...
- 【Machine Learning in Action --3】决策树ID3算法
1.简单概念描述 决策树的类型有很多,有CART.ID3和C4.5等,其中CART是基于基尼不纯度(Gini)的,这里不做详解,而ID3和C4.5都是基于信息熵的,它们两个得到的结果都是一样的,本次定 ...
随机推荐
- 登录MES系统后台服务的操作
一:使用GIt Bash Here打开服务 文件名:MES-Server-API-SC 输入:yarn server//打开服务 文件名:MES-server-API 输入:yarn local//本 ...
- Linux进阶命令用法
1.tr命令 可以对来自标准输入的字符进行替换.压缩和删除.它可以将一组字符变成另一组字符 选项 -c或——complerment:取代所有不属于第一字符集的字符: -d或——delete:删除所有属 ...
- 自定义类在PropertyGrid上的展示方法
自定义类在PropertyGrid上的展示方法 零.引言 PropertyGrid用来显示某一对象的属性,但是并不是所有的属性都能编辑,基本数据类型(int, double等)和.Net一些封装的类型 ...
- SVN 问题:None of the environment variables SVN_EDITOR, VISUAL or EDITOR are set, and no 'editor-cmd' run-time
问题原因: 没有设置svn编辑器的环境变量,主要是import.commit中填写comment要用 解决办法: 编辑 /etc/bashrc 文件,加入如下一行: export SVN_EDITOR ...
- css知识总结
---# 学习目标:> 1. 学会使用CSS选择器> 2. 熟记CSS样式和外观属性> 3. 熟练掌握CSS各种选择器> 4. 熟练掌握CSS各种选择器> 5. 熟练掌握 ...
- 轮播效果/cursor
cursor属性:改变鼠标中的属性 例如: cursor:pointer(鼠标移动上去变小手) <!doctype html> <html> <head> < ...
- 小程序textarea完美填坑
相信做微信小程序的码友们都被textarea这个原生组件坑过,什么placeholder位置错乱,穿透弹窗或遮罩层,ios上输入法弹起后换行输入内容遮挡,删除输入内容时内容被遮挡等等... 反正综上所 ...
- 与JMeter的第一次亲密接触
postman和JMeters是外部接口测试的两个工具,通过界面化的方法,来实现操作http报文携带的请求字段.VK值.json.cookie.header值及文件.本篇主要介绍JMeter. 测 ...
- [python] python django web 开发 —— 15分钟送到会用(只能送你到这了)
1.安装python环境 1.1 安装python包管理器: wget https://bootstrap.pypa.io/get-pip.py sudo python get-pip.py 1. ...
- emWin录音机,含uCOS-III和FreeRTOS两个版本
第12期:录音机配套例子:V6-921_STemWin提高篇实验_录音机(uCOS-III)V6-922_STemWin提高篇实验_录音机(FreeRTOS) 例程下载地址: http://forum ...