【项目实战】Kaggle电影评论情感分析
前言
这几天持续摆烂了几天,原因是我自己对于Kaggle电影评论情感分析的这个赛题敲出来的代码无论如何没办法运行,其中数据变换的维度我无法把握好,所以总是在函数中传错数据。今天痛定思痛,重新写了一遍代码,终于成功。
从国籍分类入手
在这个题目之前,给了一个按照姓名分类国籍的写法
https://www.bilibili.com/video/BV1Y7411d7Ys?p=13
按照这个写法我来写这个赛题,代码以及注释如下
'''''''''
构建一个RNN分类器
任务:一个名称分类器,根据输入的名字判断其国籍,数据集有Name与Country
在这个场景中,由于输出无法通过线性层映射到某个维度,所以可以只用hn来连接线性层,对这个输入做一个18维的分类
'''''''''
import csv
import gzip
import torch
import matplotlib.pyplot as plt
import numpy as np
from torch.nn.utils.rnn import pack_padded_sequence
from torch.utils.data import Dataset, DataLoader
device = torch.device('cuda:0')
HIDDEN_SIZE = 100
BATCH_SIZE = 256
N_LAYER = 2
N_EPOCHS = 100
N_CHARS = 128 # 字符集字典维度
class NameDataset(Dataset): #数据集类
def __init__(self,is_train_set = True):
filename = 'names_train.csv.gz' if is_train_set else 'names_test.csv.gz'
with gzip.open(filename,'rt') as f:
reader = csv.reader(f)
rows = list(reader)
self.names = [row[0] for row in rows] # 把名字字符串存到列表
self.len = len(self.names) # 数据集长度
self.countries = [row[1] for row in rows] # 所有国家字符串存到列表
self.country_list = list(sorted(set(self.countries))) # unique国家列表
self.country_dict = self.getCountryDict()
self.country_num = len(self.country_list) # unique国家数
def __getitem__(self,index):
return self.names[index],self.country_dict[self.countries[index]]
# 返回名称和国家,国家先通过index找到国家,再通过字典映射返回国家的序号
def __len__(self):
return self.len
def getCountryDict(self): # 把unique国家做成字典
country_dict = dict()
for idx,counrty_name in enumerate(self.country_list,0):
country_dict[counrty_name] = idx
return country_dict
def idx2country(self,index):
return self.country_list[index]
def getCountriesNum(self):
return self.country_num # 返回unique国家数
trainset = NameDataset(is_train_set=True)
trainloader = DataLoader(trainset,batch_size=BATCH_SIZE,shuffle=True)
testset = NameDataset(is_train_set=False)
testloader = DataLoader(testset,batch_size=BATCH_SIZE,shuffle=False)
N_COUNTRY = trainset.getCountriesNum()
class RNNClassifier(torch.nn.Module):
def __init__(self,input_size,hidden_size,output_size,n_layers=1,bidirectional=True):
super(RNNClassifier, self).__init__()
self.hidden_size = hidden_size
self.n_layers = n_layers
self.n_directions = 2 if bidirectional else 1
self.embedding = torch.nn.Embedding(input_size,hidden_size) # inputs_size是名称字符集长度
self.gru = torch.nn.GRU(hidden_size,hidden_size,n_layers,bidirectional=bidirectional)
self.fc = torch.nn.Linear(hidden_size*self.n_directions,output_size) # output_size是N_COUNTRY
def _init_hidden(self,batch_size):
hidden = torch.zeros(self.n_layers*self.n_directions,batch_size,self.hidden_size)
#layers*batch_size*hidden_size
return hidden.to(device)
def forward(self,input,seq_lengths):
input = input.t() # b*s to s*b
batch_size = input.size(1)
hidden = self._init_hidden(batch_size)
embedding = self.embedding(input)
gru_input = pack_padded_sequence(embedding,seq_lengths.cpu())
# 这是gru和lstm可以接受的一种输入, PackedSequence object
output,hidden = self.gru(gru_input,hidden)
if self.n_directions == 2:
hidden_cat = torch.cat((hidden[-1],hidden[-2]),dim=1)
else:
hiddden_cat = hidden[-1]
fc_output = self.fc(hidden_cat)
return fc_output
def name2list(name):
arr = [ord(c) for c in name]
return arr,len(arr)
# 返回输入名字的asci码值的列表,和名字长度
def make_tensors(names,countries): # 把输入数据处理为tensor
sequences_and_lengths = [name2list(name) for name in names]
name_sequences = [sl[0] for sl in sequences_and_lengths]
seq_lengths = torch.LongTensor([sl[1] for sl in sequences_and_lengths]) # seq_lengths to longTensor
countries = countries.long() # index of country to longTensor
# make tensor of name, batchsize*seqlen
seq_tensor = torch.zeros(len(name_sequences),seq_lengths.max()).long()
# 这一句先生成一个二维全0张量,高是名称序列数,宽是最长的名字长度,做成longTensor
for idx,(seq,seq_len) in enumerate(zip(name_sequences,seq_lengths),0):
seq_tensor[idx, :seq_len] = torch.LongTensor(seq) # 复制到上面的全0张量中
# sort sequences by length to use pack_padded_sequence
seq_lengths,perm_idx = seq_lengths.sort(dim=0,descending=True)
# torch中tensor类的tensor返回的是排完序列和索引
seq_tensor = seq_tensor[perm_idx]
countries = countries[perm_idx]
return seq_tensor.to(device),seq_lengths.to(device),countries.to(device)
classifier = RNNClassifier(N_CHARS,HIDDEN_SIZE,N_COUNTRY,N_LAYER,True).to(device)
#classifier = classifier.to(device)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(classifier.parameters(),lr=0.001)
#start = time.time()
def trainModel():
total_loss = 0
for i,(names,countries) in enumerate(trainloader,1): # i从1开始数
inputs,seq_lengths,target = make_tensors(names,countries)
output = classifier(inputs,seq_lengths) # 这是送的forward的参数.
loss = criterion(output,target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
if i%10 == 0:
print(f'Epoch{epoch}',end='')
print(f'[{i*len(inputs)}/{len(trainset)}]',end='')
print(f'loss={total_loss/(i*len(inputs))}')
return total_loss
def testModel():
correct = 0
total = len(testset)
print('evaluating trained model ...')
with torch.no_grad():
for i,(names,countries) in enumerate(testloader,1):
inputs,seq_lengths,target = make_tensors(names,countries)
output = classifier(inputs,seq_lengths)
pred = output.max(dim=1,keepdim=True)[1]
correct += pred.eq(target.view_as(pred)).sum().item()
percent = '%.2f' % (100*correct/total)
print(f'Test set: Accuracy{correct}/{total} {percent}%')
return correct/total
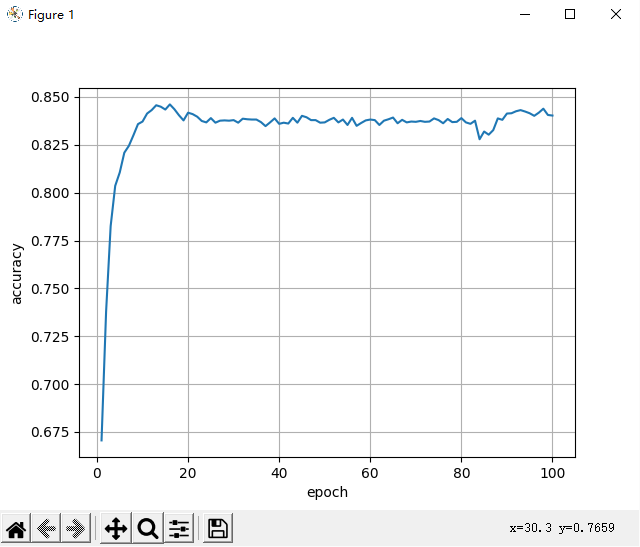
print('Training for %d epochs...' % N_EPOCHS)
acc_list = []
for epoch in range(1,30):
trainModel()
acc = testModel()
acc_list.append(acc)
epoch = np.arange(1,len(acc_list)+1,1)
acc_list = np.array(acc_list)
plt.plot(epoch,acc_list)
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.grid()
plt.show()
好,下面我们进入赛题部分
赛题理解
赛题以及数据的下载地址如下:https://www.kaggle.com/c/sentiment-analysis-on-movie-reviews
数据就是给出id,评论内容,以及标注好的情感极性,然后经过训练,测试集传入模型判断测试集评论的情感,给出csv格式文件,来进行评分,数据长得就是下面这个样子:
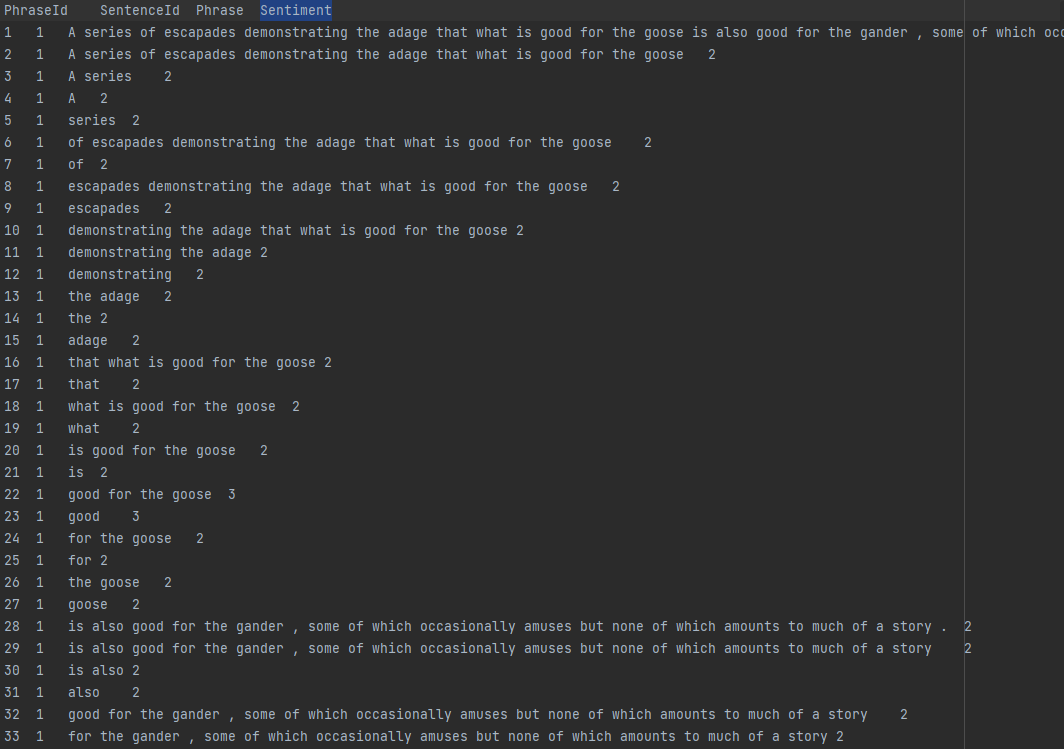
数据处理
由于给出的是tsv格式,所以我们用pandas自带的read来读取,只需要把phrase和sentiment取出来就行了,代码如下:
class NameDataset(Dataset): #数据集类
def __init__(self, is_train_set=True):
train = pd.read_csv('train.tsv', sep='\t') # 分隔符是空格
self.phrase = train['Phrase']
self.sentiment = train['Sentiment']
self.len = len(self.phrase)
def __getitem__(self, index):
return self.phrase[index], self.sentiment[index]
def __len__(self):
return self.len
由于评论是string字符,我们需要把它转成可以被接受的向量
def phrase2list(phrase):
arr = [ord(c) for c in phrase]
return arr, len(arr)
## 用ASCILL编码来转换字符
def make_tensors(phrase, sentiment):
sequences_and_lengths = [phrase2list(phrase) for phrase in phrase]
phrase_sequences = [sl[0] for sl in sequences_and_lengths]
seq_lengths = torch.LongTensor([sl[1] for sl in sequences_and_lengths])
sentiment = sentiment.long()
seq_tensor = torch.zeros(len(phrase_sequences), seq_lengths.max()).long()
for idx, (seq, seq_len) in enumerate(zip(phrase_sequences, seq_lengths), 0):
seq_tensor[idx, :seq_len] = torch.LongTensor(seq)
seq_lengths, prem_idx = seq_lengths.sort(dim=0, descending=True)
seq_tensor = seq_tensor[prem_idx]
sentiment = sentiment[prem_idx]
return seq_tensor.to(device), seq_lengths.to(device), sentiment.to(device)
然后测试集是不需要转变sentiment的,因为根本没有,所以在搞一个专门给测试集传字符
def make_tensors1(phrase):
sequences_and_lengths = [phrase2list(phrase) for phrase in phrase]
phrase_sequences = [sl[0] for sl in sequences_and_lengths]
seq_lengths = torch.LongTensor([sl[1] for sl in sequences_and_lengths])
seq_tensor = torch.zeros(len(phrase_sequences), seq_lengths.max()).long()
for idx, (seq, seq_len) in enumerate(zip(phrase_sequences, seq_lengths), 0):
seq_tensor[idx, :seq_len] = torch.LongTensor(seq)
seq_lengths, prem_idx = seq_lengths.sort(dim=0, descending=True)
seq_tensor = seq_tensor[prem_idx]
_, index = prem_idx.sort(descending=False)
return seq_tensor.to(device), seq_lengths.to(device), index
设计模型
首先我们确定一些超参数
device = torch.device('cuda:0')
NUM_CHARS = 128
HIDDEN_SIZE = 100
NUM_CLASS = 5
NUM_LAYERS = 2
NUM_EPOCHS = 30
BATCH_SIZE = 512
然后我们使用GRU
class RNNClassifier(torch.nn.Module):
def __init__(self, input_size, hidden_size, output_size, n_layers=1, bidirectional=True):
super(RNNClassifier, self).__init__()
self.hidden_size = hidden_size
self.n_layers = n_layers
self.n_direction = 2 if bidirectional else 1
self.embedding = torch.nn.Embedding(input_size, hidden_size)
self.gru = torch.nn.GRU(hidden_size, hidden_size, n_layers, bidirectional=bidirectional)
self.fc = torch.nn.Linear(hidden_size*self.n_direction, output_size)
def _init_hidden(self, batch_size):
hidden = torch.zeros(self.n_layers*self.n_direction, batch_size, self.hidden_size)
return hidden.to(device)
def forward(self, input, seq_lengths):
input = input.t()
batch_size = input.size(1)
hidden = self._init_hidden(batch_size)
embedding = self.embedding(input)
gru_input = pack_padded_sequence(embedding, seq_lengths.cpu())
output, hidden = self.gru(gru_input, hidden)
if self.n_direction == 2:
hidden_cat = torch.cat((hidden[-1], hidden[-2]), dim=1)
else:
hidden_cat = hidden[-1]
fc_output = self.fc(hidden_cat)
return fc_output
模型实例化并设计损失函数和优化器
classifier = RNNClassifier(NUM_CHARS, HIDDEN_SIZE, NUM_CLASS, NUM_LAYERS, True).to(device)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(classifier.parameters(), lr=0.001)
模型训练与测试
首先来设计训练函数
def train():
total_loss = 0
for i, (phrase, sentiment) in enumerate(train_loader, 1):
inputs, seq_lengths, target = make_tensors(phrase, sentiment)
output = classifier(inputs, seq_lengths)
loss = criterion(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.zero_grad()
optimizer.step()
total_loss += loss.item()
if i % 10 == 0:
print(f'Epoch{epoch}', end='')
print(f'[{i * len(inputs)}/{len(train_set)}]', end='')
print(f'loss={total_loss / (i * len(inputs))}')
return total_loss
然后设计函数来获取测试集数据
def get_test_set():
test_set = pd.read_csv('test.tsv', '\t')
PhraseId = test_set['PhraseId']
test_Phrase = test_set['Phrase']
return PhraseId, test_Phrase
测试函数设计如下
def testModel():
PhraseId, test_Phrase = get_test_set()
sentiment_list = [] # 定义预测结果列表
batchNum = math.ceil(PhraseId.shape[0] / BATCH_SIZE)
with torch.no_grad():
for i in range(batchNum):
print(i)
if i == batchNum - 1:
phraseBatch = test_Phrase[BATCH_SIZE * i:] # 处理最后不足BATCH_SIZE的情况
else:
phraseBatch = test_Phrase[BATCH_SIZE * i:BATCH_SIZE * (i + 1)]
inputs, seq_lengths, org_idx = make_tensors1(phraseBatch)
output = classifier(inputs, seq_lengths)
sentiment = output.max(dim=1, keepdim=True)[1]
sentiment = sentiment[org_idx].squeeze(1)
sentiment_list.append(sentiment.cpu().numpy().tolist())
sentiment_list = list(chain.from_iterable(sentiment_list)) # 将sentiment_list按行拼成一维列表
result = pd.DataFrame({'PhraseId': PhraseId, 'Sentiment': sentiment_list})
result.to_csv('SA_predict.csv', index=False)
开始跑代码
if __name__ == '__main__':
start = time.time()
print('Training for %d epochs...' % NUM_EPOCHS)
acc_list = []
for epoch in range(1, NUM_EPOCHS + 1):
train()
acc = train()
acc_list.append(acc)
if acc <= min(acc_list):
torch.save(classifier, 'sentimentAnalyst.pkl')
print('Save Model!')
testModel()
epoch = [epoch + 1 for epoch in range(len(acc_list))]
plt.plot(epoch, acc_list)
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.grid()
plt.show()
结果
淦,跑完忘记截图platshow的图了,但是我上传kaggle,一跑完只有0.2分,哪里出了问题呢
改成14次,这次截图了
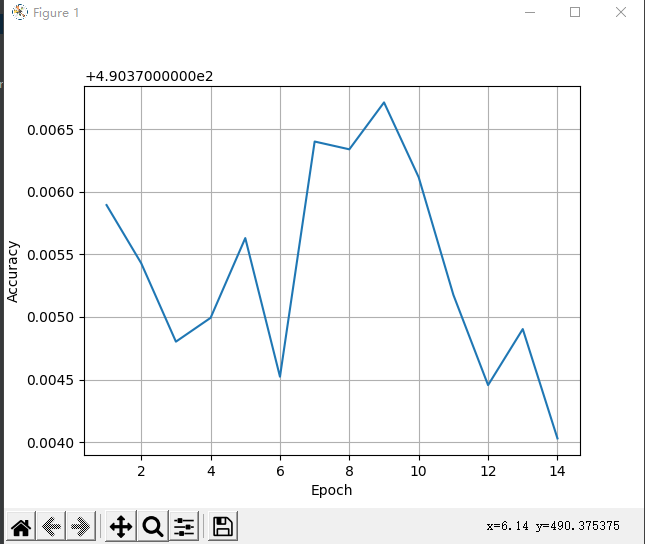
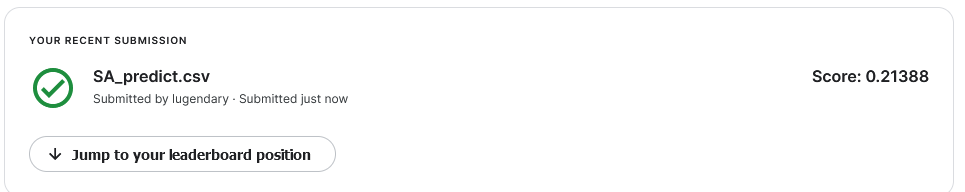
我陷入了沉思
inputs, seq_lengths, target = make_tensors(phrase, sentiment)
output = classifier(inputs, seq_lengths)
loss = criterion(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.zero_grad()
optimizer.step()
total_loss += loss.item()
问题出在这里
我他妈的一不小心多写了一步 optimizer.zero_grad(),结果跑了几个小时都在原地踏步
现在我们用修改后的模型再试一下
跑完十次的结果和分数如下
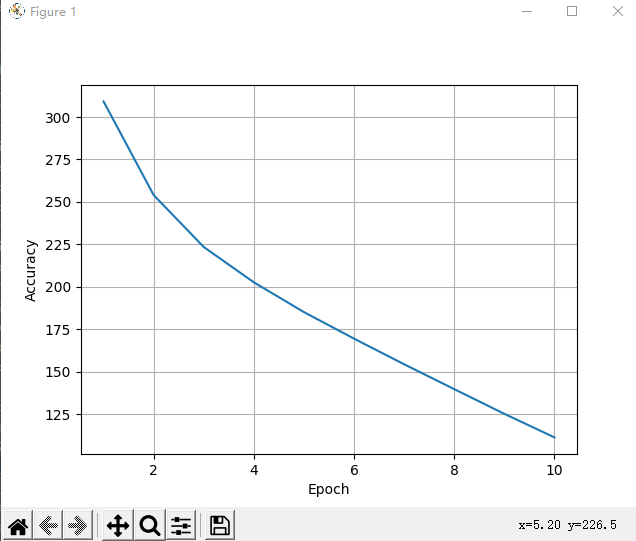

完整代码
import math
from itertools import chain
import torch
import matplotlib.pyplot as plt
import pandas as pd
from torch.nn.utils.rnn import pack_padded_sequence
from torch.utils.data import Dataset, DataLoader
class NameDataset(Dataset): #数据集类
def __init__(self):
self.train = pd.read_csv('train.tsv', sep='\t')
self.phrase = self.train['Phrase']
self.sentiment = self.train['Sentiment']
self.len = self.train.shape[0]
def __getitem__(self, index):
return self.phrase[index], self.sentiment[index]
def __len__(self):
return self.len
device = torch.device('cuda:0')
NUM_CHARS = 128
HIDDEN_SIZE = 128
NUM_LAYERS = 2
NUM_EPOCHS = 10
BATCH_SIZE = 512
train_set = NameDataset()
train_loader = DataLoader(train_set, batch_size=BATCH_SIZE, shuffle=True)
NUM_CLASS = len(set(train_set.sentiment))
class RNNClassifier(torch.nn.Module):
def __init__(self, input_size, hidden_size, output_size, n_layers=1, bidirectional=True):
super(RNNClassifier, self).__init__()
self.hidden_size = hidden_size
self.n_layers = n_layers
self.n_direction = 2 if bidirectional else 1
self.embedding = torch.nn.Embedding(input_size, hidden_size)
self.gru = torch.nn.GRU(hidden_size, hidden_size, n_layers, bidirectional=bidirectional)
self.fc = torch.nn.Linear(hidden_size*self.n_direction, output_size)
def _init_hidden(self, batch_size):
hidden = torch.zeros(self.n_layers*self.n_direction, batch_size, self.hidden_size)
return hidden.to(device)
def forward(self, input, seq_lengths):
input = input.t()
batch_size = input.size(1)
hidden = self._init_hidden(batch_size)
embedding = self.embedding(input)
gru_input = pack_padded_sequence(embedding, seq_lengths.cpu())
output, hidden = self.gru(gru_input, hidden)
if self.n_direction == 2:
hidden_cat = torch.cat((hidden[-1], hidden[-2]), dim=1)
else:
hidden_cat = hidden[-1]
fc_output = self.fc(hidden_cat)
return fc_output
def phrase2list(phrase):
arr = [ord(c) for c in phrase]
return arr, len(arr)
def make_tensors(phrase, sentiment):
sequences_and_lengths = [phrase2list(phrase) for phrase in phrase]
phrase_sequences = [sl[0] for sl in sequences_and_lengths]
seq_lengths = torch.LongTensor([sl[1] for sl in sequences_and_lengths])
sentiment = sentiment.long()
seq_tensor = torch.zeros(len(phrase_sequences), seq_lengths.max()).long()
for idx, (seq, seq_len) in enumerate(zip(phrase_sequences, seq_lengths), 0):
seq_tensor[idx, :seq_len] = torch.LongTensor(seq)
seq_lengths, prem_idx = seq_lengths.sort(dim=0, descending=True)
seq_tensor = seq_tensor[prem_idx]
sentiment = sentiment[prem_idx]
return seq_tensor.to(device), seq_lengths.to(device), sentiment.to(device)
def make_tensors1(phrase):
sequences_and_lengths = [phrase2list(phrase) for phrase in phrase]
phrase_sequences = [sl[0] for sl in sequences_and_lengths]
seq_lengths = torch.LongTensor([sl[1] for sl in sequences_and_lengths])
seq_tensor = torch.zeros(len(phrase_sequences), seq_lengths.max()).long()
for idx, (seq, seq_len) in enumerate(zip(phrase_sequences, seq_lengths), 0):
seq_tensor[idx, :seq_len] = torch.LongTensor(seq)
seq_lengths, prem_idx = seq_lengths.sort(dim=0, descending=True)
seq_tensor = seq_tensor[prem_idx]
_, index = prem_idx.sort(descending=False)
return seq_tensor.to(device), seq_lengths.to(device), index
def train():
total_loss = 0
for i, (phrase, sentiment) in enumerate(train_loader, 1):
inputs, seq_lengths, target = make_tensors(phrase, sentiment)
output = classifier(inputs, seq_lengths)
loss = criterion(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
if i % 10 == 0:
print(f'Epoch{epoch}', end='')
print(f'[{i * len(inputs)}/{len(train_set)}]', end='')
print(f'loss={total_loss / (i * len(inputs))}')
return total_loss
def get_test_set():
test_set = pd.read_csv('test.tsv', '\t')
PhraseId = test_set['PhraseId']
test_Phrase = test_set['Phrase']
return PhraseId, test_Phrase
def testModel():
PhraseId, test_Phrase = get_test_set()
sentiment_list = [] # 定义预测结果列表
batchNum = math.ceil(PhraseId.shape[0] / BATCH_SIZE)
with torch.no_grad():
for i in range(batchNum):
if i == batchNum - 1:
phraseBatch = test_Phrase[BATCH_SIZE * i:] # 处理最后不足BATCH_SIZE的情况
else:
phraseBatch = test_Phrase[BATCH_SIZE * i:BATCH_SIZE * (i + 1)]
inputs, seq_lengths, org_idx = make_tensors1(phraseBatch)
output = classifier(inputs, seq_lengths)
sentiment = output.max(dim=1, keepdim=True)[1]
sentiment = sentiment[org_idx].squeeze(1)
sentiment_list.append(sentiment.cpu().numpy().tolist())
sentiment_list = list(chain.from_iterable(sentiment_list)) # 将sentiment_list按行拼成一维列表
result = pd.DataFrame({'PhraseId': PhraseId, 'Sentiment': sentiment_list})
result.to_csv('SA_predict.csv', index=False)
if __name__ == '__main__':
classifier = RNNClassifier(NUM_CHARS, HIDDEN_SIZE, NUM_CLASS, NUM_LAYERS).to(device)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(classifier.parameters(), lr=0.001)
print('Training for %d epochs...' % NUM_EPOCHS)
acc_list = []
for epoch in range(1, NUM_EPOCHS + 1):
train()
acc = train()
acc_list.append(acc)
if acc <= min(acc_list):
torch.save(classifier, 'sentimentAnalyst.pkl')
print('Save Model!')
testModel()
epoch = [epoch + 1 for epoch in range(len(acc_list))]
plt.plot(epoch, acc_list)
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.grid()
plt.show()
其实这里可以感觉到验证集的重要性了,因为你很容易过拟合,所以这里附上大佬写的带验证集的代码链接
https://blog.csdn.net/qq_39187959/article/details/121102959
带有验证集可以让模型达到0.7分
【项目实战】Kaggle电影评论情感分析的更多相关文章
- 基于Keras的imdb数据集电影评论情感二分类
IMDB数据集下载速度慢,可以在我的repo库中找到下载,下载后放到~/.keras/datasets/目录下,即可正常运行.)中找到下载,下载后放到~/.keras/datasets/目录下,即可正 ...
- FastAPI小项目实战:电影列表(Vue3 + FastAPI)
假期过半, FastAPI + Vue3项目实战 视频也算录完了,尽管项目简单(2张表 共7个接口 4个页面) 起因 在6月底的时候开始录制了FastAPI官方文档中的新手教程部分(实际还没有官网文档 ...
- kaggle——Bag of Words Meets Bags of Popcorn(IMDB电影评论情感分类实践)
kaggle链接:https://www.kaggle.com/c/word2vec-nlp-tutorial/overview 简介:给出 50,000 IMDB movie reviews,进行0 ...
- 文本情感分析(一):基于词袋模型(VSM、LSA、n-gram)的文本表示
现在自然语言处理用深度学习做的比较多,我还没试过用传统的监督学习方法做分类器,比如SVM.Xgboost.随机森林,来训练模型.因此,用Kaggle上经典的电影评论情感分析题,来学习如何用传统机器学习 ...
- 文本情感分析(二):基于word2vec、glove和fasttext词向量的文本表示
上一篇博客用词袋模型,包括词频矩阵.Tf-Idf矩阵.LSA和n-gram构造文本特征,做了Kaggle上的电影评论情感分类题. 这篇博客还是关于文本特征工程的,用词嵌入的方法来构造文本特征,也就是用 ...
- 基于情感词典的python情感分析
近期老师给我们安排了一个大作业,要求根据情感词典对微博语料进行情感分析.于是在网上狂找资料,看相关书籍,终于搞出了这个任务.现在做做笔记,总结一下本次的任务,同时也给遇到有同样需求的人,提供一点帮助. ...
- 【API进阶之路】帮公司省下20万调研费!如何巧用情感分析API实现用户偏好调研
摘要:自从学习API后,仿佛解锁了新技能,可别小看了一个小小的API接口,用好了都是能力无穷.这不,用情感分析API来做用户偏好调研,没想到这么一个小创意给公司省了20万调研费用. 上次借着高考热点整 ...
- GraphQL + React Apollo + React Hook 大型项目实战(32 个视频)
GraphQL + React Apollo + React Hook 大型项目实战(32 个视频) GraphQL + React Apollo + React Hook 大型项目实战 #1 介绍「 ...
- kaggle之电影评论文本情感分类
电影文本情感分类 Github地址 Kaggle地址 这个任务主要是对电影评论文本进行情感分类,主要分为正面评论和负面评论,所以是一个二分类问题,二分类模型我们可以选取一些常见的模型比如贝叶斯.逻辑回 ...
随机推荐
- Codeforces Round #780 (Div. 3)
A. Vasya and Coins 题目链接 题目大意 Vasya 有 a 个 1-burle coin,有 b 个 2-burle coin,问他不能通过不找钱支付的价格的最小值. 思路 如果 a ...
- 注册器机制Registry
在众多深度学习开源库的代码中经常出现Registry代码块,例如OpenMMlab,facebookresearch和BasicSR中都使用了注册器机制.这块的代码经常会让新使用这些库的初学者感到一头 ...
- labview从入门到出家3--制作和调用子VI
当程序越写越大的时候,我们会发现代码界面会比较乱(线太多),那要怎么做可以让代码更简洁一点,我只管直接调用某个功能函数,而不需要在一个VI上面去实现这个功能函数呢?--子VI.好比C语言里面的Main ...
- filebeat + logstash 日志采集链路配置
1. 概述 一个完整的采集链路的流程如下: 所以要进行采集链路的部署需要以下几个步聚: nginx的配置 filebeat部署 logstash部署 kafka部署 kudu部署 下面将详细说明各个部 ...
- ajax04_实现关键字联想和自动补全
用ajax实现关键字联想和自动补全 遇到的小坑 回调函数相对window.onload的摆放位置 给回调函数addData传数据时,如何操作才能将数据传进去 代码实现 前端代码 <!DOCTYP ...
- C++ 内存模型 write_x_read_y 试例构造
之前一段时间偶然在 B 站上刷到了南京大学蒋炎岩(jyy)老师在直播操作系统网课.点进直播间看了一下发现这个老师实力非凡,上课从不照本宣科,而且旁征博引又不吝于亲自动手演示,于是点了关注.后来开始看其 ...
- Jetpack Compose学习(8)——State及remeber
原文地址: Jetpack Compose学习(8)--State状态及remeber关键字 - Stars-One的杂货小窝 之前我们使用TextField,使用到了两个关键字remember和mu ...
- SkiaSharp 之 WPF 自绘 投篮小游戏(案例版)
此案例主要是针对光线投影法碰撞检测功能的示例,顺便做成了一个小游戏,很简单,但是,效果却很不错. 投篮小游戏 规则,点击投篮目标点,就会有一个球沿着相关抛物线,然后,判断是否进入篮子里,其实就是一个矩 ...
- Javaweb05-Ajax
1.基于jQuery的Ajax 1.1 基本Ajax 参数 说明 url 请求地址 type 请求类型 data 请求参数 dataType 返回参数 success 成功处理函数 error 错误处 ...
- Luogu3694 邦邦的大合唱站队 (状压DP)
状态由\(从前往后排好的长度\)和\(排好的团队\)决定,\(DP\)方程挺有思考价值的. #include <iostream> #include <cstdio> #inc ...