JavaEE Day03 MySQL约束
- 排序查询
- 聚合函数
- 分组查询
- 分页查询
SELECT * FROM student ORDER BY math ASC;-- 升序
SELECT * FROM student ORDER BY math DESC;-- 降序
SELECT * FROM student ORDER BY math;-- 默认升序
-- 按照数学成绩排名,如果数学成绩一样,则按照英语成绩排名(升序)
SELECT * FROM student ORDER BY math ASC, english ASC;-- 默认升序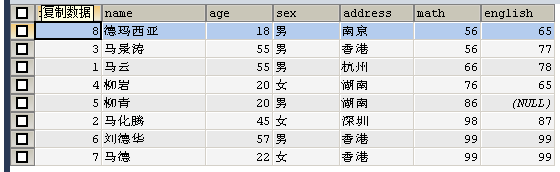
- count:计算个数
- 一般选择非空的列--主键
- count(*)
- max:计算最大值
- min:计算最小值
- sum:计算和
- avg:计算平均值
- 选择不包含非空的列进行计算
- 使用IFNULL函数
-- 聚合函数
SELECT COUNT(ENGLISH) FROM STUDENT;-- 7,单行单列
-- 排除null不够合理,可以将null值换成0
SELECT COUNT(IFNULL(ENGLISH,0)) FROM STUDENT;-- 8,单行单列
SELECT COUNT(*) FROM STUDENT;-- 一般不允许写*,而是写主键
SELECT COUNT(ID) FROM STUDENT;
SELECT MAX(MATH) FROM STUDENT;
SELECT MAX(MATH) FROM STUDENT;
SELECT SUM(MATH) FROM STUDENT;
SELECT AVG(MATH) FROM STUDENT;- 语法:group by 分组字段;
- 注意
- 分组之后查询的字段:分组字段/聚合函数
- WHERE和HAVING的区别 ?
- where在分组之前进行限定,如果不满足条件,则不参与分组
- having在分组之后进行限定,如果不满足结果,则不会被查询出来
- where后不能跟聚合函数,having可以进行聚合函数的判断
-- 分组查询之后,不能加其他的字段
-- 按照性别分组,分别查询男、女同学的平均分
SELECT SEX, AVG(MATH) FROM STUDENT GROUP BY SEX;-- 不能出现个人信息,只能出现整体
SELECT NAME, AVG(MATH) FROM STUDENT GROUP BY SEX;-- 查第一条,没有意义
SELECT SEX, AVG(MATH) ,COUNT(ID) FROM STUDENT GROUP BY SEX;-- 人数
-- 分数低于70的,不进行分组
-- 分组前,限定分组的条件
-- 按照性别分组,分别查询男、女同学的平均分,分数低于70分的人,不参与分组
SELECT SEX, AVG(MATH) ,COUNT(ID) FROM STUDENT WHERE MATH>70 GROUP BY SEX;-- 人数
-- 分组后再进行限定
-- 按照性别分组,分别查询男、女同学的平均分,分数低于70分的人,不参与分组;分组之后,人数要大于2个人
SELECT SEX, AVG(MATH) ,COUNT(ID) FROM STUDENT WHERE MATH>70 GROUP BY SEX HAVING COUNT(ID)>2;-- 人数
-- 换写法,起别名
SELECT SEX, AVG(MATH) ,COUNT(ID) 人数 FROM STUDENT WHERE MATH>70 GROUP BY SEX HAVING 人数>2;-- 人数,一般写英文- 语法:limit 开始的索引, 每页查询的条数;
- 公式:开始的索引=(当前的页码-1)*每页显示的条数
- 分页操作的limit是一个MySQL的“方言”【Oracle用的是rownumber】
-- 分页查询
-- 百度为您找到约3000000条记录
SELECT * FROM student;
-- 共8条,每页显示3条
SELECT * FROM STUDENT LIMIT 0,3;-- 第一页的前三条
SELECT * FROM STUDENT LIMIT 3,3;-- 编号为4记录开始的索引,每页显示的数据【第二页】
SELECT * FROM STUDENT LIMIT 6,3;-- 【第三页】
-- 公式:开始的索引=(当前的页码-1)*每页显示的条数
-- 公式计算 第三页=(3-1)*3- 对表中的数据进行限定,保证数据的正确性、有效性和完整性
- 分类
- 主键约束:primary key
- 非空约束:not null
- 唯一约束:unique
- 外键约束:foreign key
- 创建表时添加约束
-- 约束
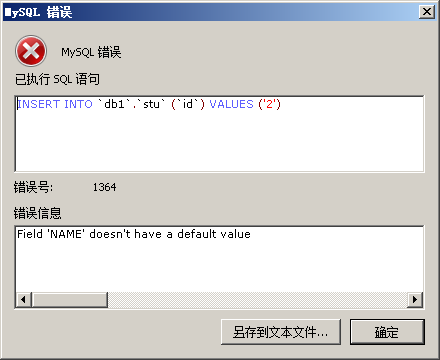
-- 1.创建表添加非空约束
CREATE TABLE stu(
id INT,
NAME VARCHAR(20) NOT NULL -- NAME为非空
);- 创建表完之后,添加非空约束
- 删除name的非空约束
-- 删除name的非空约束
ALTER TABLE STU MODIFY NAME VARCHAR(20);
-- 2.创建表之后,添加非空约束
-- 添加非空约束
ALTER TABLE STU MODIFY NAME VARCHAR(20) NOT NULL;
SELECT * FROM STU;- 注意
- 唯一约束可以有NULL值,但是只能有一条记录为null
- 创建表时,创建唯一约束
-- 在创建表时创建唯一约束
CREATE TABLE STU(
id INT,
phone_number VARCHAR(20) UNIQUE -- 手机号
);
-- 在表创建完之后添加唯一约束
ALTER TABLE stu MODIFY phone_number VARCHAR(20) UNIQUE; - 删除唯一约束
ALTER TABLE stu DROP INDEX phone_number;- 注意
- 含义:非空且唯一
- 一张表只能有一个字段为主键
- 主键就是表中记录的唯一标识
- 创建表时,添加主键约束
CREATE TABLE STU(
id INT PRIMARY KEY, -- 给id添加主键约束
NAME VARCHAR(20)
);
SELECT * FROM STU; - 创建完表后,添加主键
-- 删除主键
ALTER TABLE STU MODIFY ID INT;-- 执行成功但不会生效
-- 正确方式
ALTER TABLE STU DROP PRIMARY KEY;-- 表中只有一个主键
-- 创建完表之后,添加主键
ALTER TABLE STU MODIFY ID INT PRIMARY KEY;
- 概念:如果某一列是数值类型的,使用auto_increment可以来完成值的自动增长
- 在创建表时添加主键约束,并且完成 主键自增长
CREATE TABLE STU(
id INT PRIMARY KEY AUTO_INCREMENT, -- 给id添加主键约束
NAME VARCHAR(20)
);
SELECT * FROM STU;
INSERT INTO STU VALUES(10,'CCC');
INSERT INTO STU VALUES(NULL,'CCC');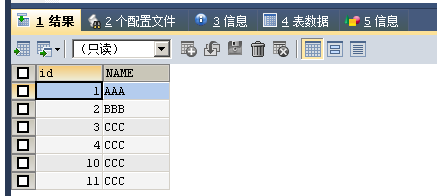
- 删除自动增长
-- 删除自动增长
ALTER TABLE STU MODIFY ID INT;
INSERT INTO STU VALUES(12,'CCC');-- 可以
INSERT INTO STU VALUES(NULL,'CCC');-- 不可以
-- 添加自动增长
ALTER TABLE STU MODIFY ID INT AUTO_INCREMENT;
INSERT INTO STU VALUES(NULL,'CCC');-- 可以
CREATE TABLE emp (
id INT PRIMARY KEY AUTO_INCREMENT,-- 号码
NAME VARCHAR(30),
age INT,-- 年龄
dep_name VARCHAR(30),-- 部门名称
dep_location VARCHAR(30)-- 部门地址
);
-- 添加数据
INSERT INTO emp (NAME, age, dep_name, dep_location) VALUES ('张三', 20, '研发部', '广州');
INSERT INTO emp (NAME, age, dep_name, dep_location) VALUES ('李四', 21, '研发部', '广州');
INSERT INTO emp (NAME, age, dep_name, dep_location) VALUES ('王五', 20, '研发部', '广州');
INSERT INTO emp (NAME, age, dep_name, dep_location) VALUES ('老王', 20, '销售部', '深圳');
INSERT INTO emp (NAME, age, dep_name, dep_location) VALUES ('大王', 22, '销售部', '深圳');
INSERT INTO emp (NAME, age, dep_name, dep_location) VALUES ('小王', 18, '销售部', '深圳');
SELECT * FROM EMP;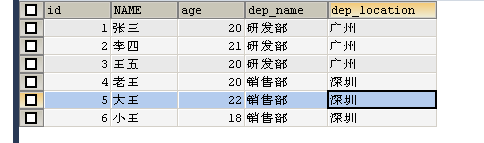
-- 解决方案:分成 2 张表
-- 创建部门表(id,dep_name,dep_location)
-- 一方,主表
CREATE TABLE department(
id INT PRIMARY KEY AUTO_INCREMENT,
dep_name VARCHAR(20),
dep_location VARCHAR(20)
);
-- 创建员工表(id,name,age,dep_id)
-- 多方,从表
CREATE TABLE employee(
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(20),
age INT,
dep_id INT -- 外键对应主表的主键
)
-- 添加 2 个部门
INSERT INTO department VALUES(NULL, '研发部','广州'),(NULL, '销售部', '深圳');
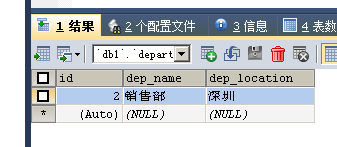
SELECT * FROM department;
-- 添加员工,dep_id 表示员工所在的部门
INSERT INTO employee (NAME, age, dep_id) VALUES ('张三', 20, 1);
INSERT INTO employee (NAME, age, dep_id) VALUES ('李四', 21, 1);
INSERT INTO employee (NAME, age, dep_id) VALUES ('王五', 20, 1);
INSERT INTO employee (NAME, age, dep_id) VALUES ('老王', 20, 2);
INSERT INTO employee (NAME, age, dep_id) VALUES ('大王', 22, 2);
INSERT INTO employee (NAME, age, dep_id) VALUES ('小王', 18, 2);
SELECT * FROM employee;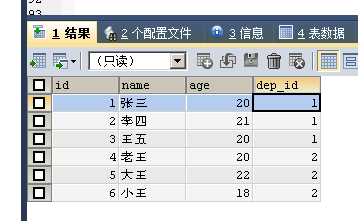
- 在创建表时,可以添加外键
- 语法:
create table 表名(
……
外键列
constraint 外键名称 foreign key 外键列名称 reference 主表名称(主表的列名称)
);
CREATE TABLE department(
id INT PRIMARY KEY AUTO_INCREMENT,
dep_name VARCHAR(20),
dep_location VARCHAR(20)
);
-- 创建员工表(id,name,age,dep_id)
-- 多方,从表
CREATE TABLE employee(
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(20),
age INT,
dep_id INT, -- 外键对应主表的主键
CONSTRAINT emp_dept_fk FOREIGN KEY (dep_id) REFERENCES department(id)
);
-- 添加 2 个部门
INSERT INTO department VALUES(NULL, '研发部','广州'),(NULL, '销售部', '深圳');
SELECT * FROM department;
-- 添加员工,dep_id 表示员工所在的部门
INSERT INTO employee (NAME, age, dep_id) VALUES ('张三', 20, 1);
INSERT INTO employee (NAME, age, dep_id) VALUES ('李四', 21, 1);
INSERT INTO employee (NAME, age, dep_id) VALUES ('王五', 20, 1);
INSERT INTO employee (NAME, age, dep_id) VALUES ('老王', 20, 2);
INSERT INTO employee (NAME, age, dep_id) VALUES ('大王', 22, 2);
INSERT INTO employee (NAME, age, dep_id) VALUES ('小王', 18, 2);
SELECT * FROM employee;
DROP TABLE DEPARTMENT;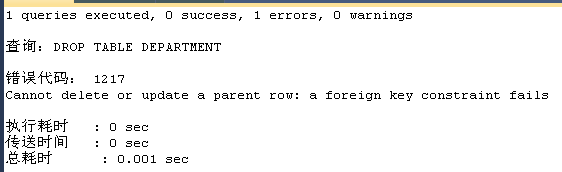
- 删除外键
-- 删除外键
ALTER TABLE employee DROP FOREIGN KEY emp_dept_fk; - 创建表之后,添加外键
-- 添加外键
ALTER TABLE employee ADD CONSTRAINT emp_dept_fk FOREIGN KEY (dep_id) REFERENCES department(id);如果表中有约束的数据,则添加失败。
SELECT * FROM department;
SELECT * FROM employee;
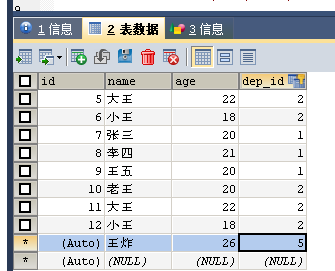
-- 想把研发部id改为5
-- 修改employee表,将原先id为1的置为空
UPDATE employee SET dep_id=NULL WHERE dep_id=1;
SELECT * FROM employee;
UPDATE employee SET dep_id=5 WHERE dep_id IS NULL;
-- 级联操作,修改apartment,自动生效-- 添加外键,设置级联更新
-- 删除外键
ALTER TABLE employee DROP FOREIGN KEY emp_dept_fk;
-- 查看是否删掉 ,可以使用架构设计器/数据实际测试
-- 添加外键,并设置级联更新
ALTER TABLE employee ADD CONSTRAINT emp_dept_fk FOREIGN KEY (dep_id) REFERENCES department(id) ON UPDATE CASCADE;-- 级联删除
-- 删除外键
ALTER TABLE employee DROP FOREIGN KEY emp_dept_fk;
-- 添加外键,并设置级联更新
ALTER TABLE employee ADD CONSTRAINT emp_dept_fk FOREIGN KEY (dep_id) REFERENCES department(id) ON UPDATE CASCADE ON DELETE CASCADE;- 一对一:
- 如:人和身份证【一一对应】
- 分析:一个人只有一个身份证,一个身份证只能对应一个人
- 一对多/多对一:
- 如:部门和员工
- 分析 :一个部门有多个员工,一个员工只能对应一个部门
- 多对多:
- 如:学生和课程
- 分析:一个学生可以选择多门课程,一个课程也可以被多个学生选择
- 下一节学习如何表示这些关系
- 一对多(多对一)
- 图示:部门和员工
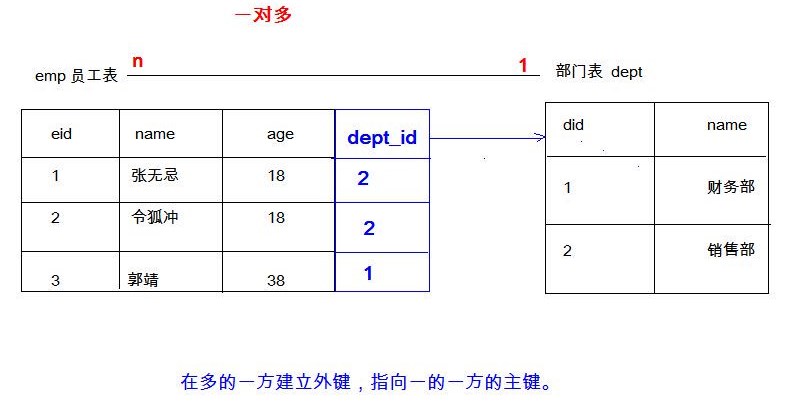
- 设计方案:在员工表添加外键指向部门表的主键(在多的一方建立指向一的一方主键的外键)
- 多表关系_多对多关系实现
- 图示:学生和课程
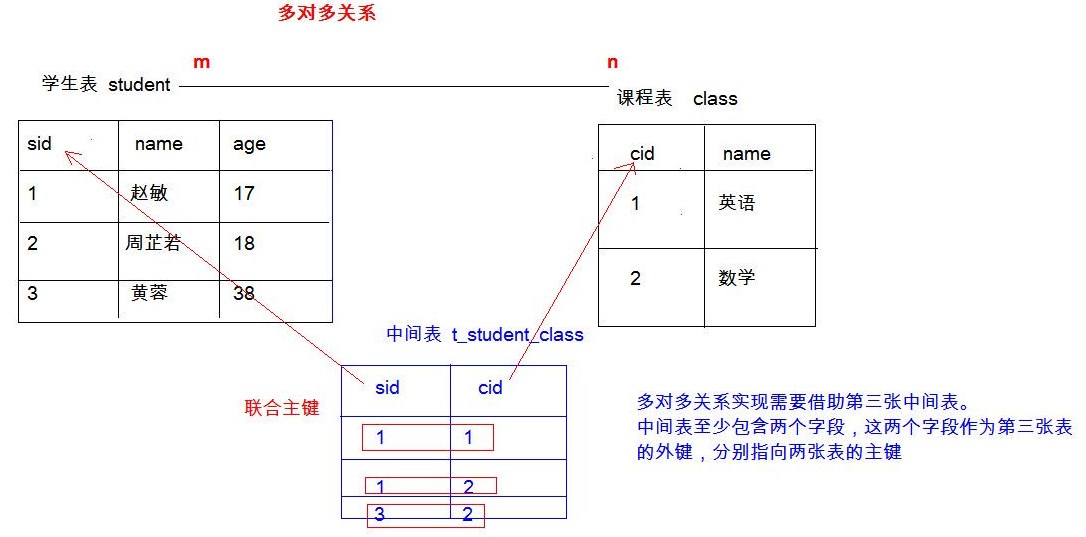
- 实现方式(借助中间表)
第三张表的两个字段作为外键,分别指向另外两张表的主键
这两个字段可以作为联合主键 - 多表关系_一对一关系实现
- 图示
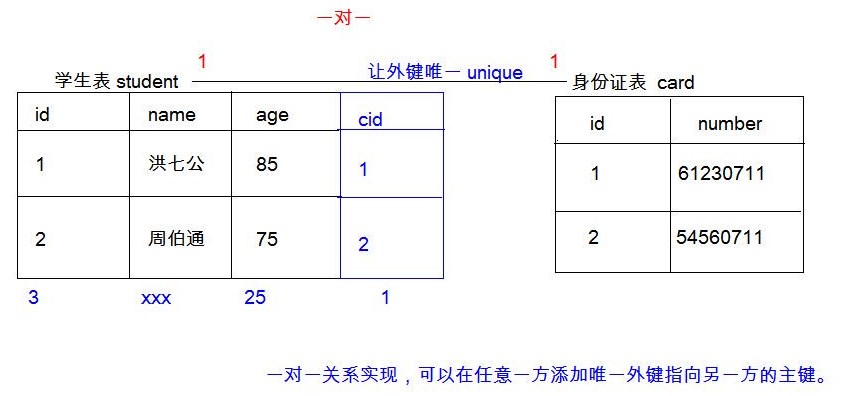
- 实现方式
一个学生对应一个身份证,一个身份证对应一个学生
可以在任意一方添加外键,指向对方的主键 - 如果有第三条记录,外键也指向1,是合法的,但这样就不是一对一关系了
解决方式:对外键加unique约束 - 问题:一对一的关系,如何保证多个外键值不指向同一个数据。
答案:对外键那一列添加unique约束【可以合并为一张表】
途牛旅游网站的实体
- 旅游线路分类
- 旅游线路
- 用户
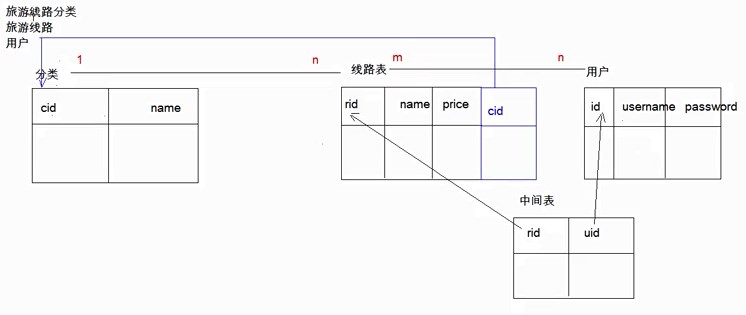
-- 创建旅游线路分类表 tab_category
-- cid 旅游线路分类主键,自动增长
-- cname 旅游线路分类名称非空,唯一,字符串 100
CREATE TABLE tab_category (
cid INT PRIMARY KEY AUTO_INCREMENT,
cname VARCHAR(100) NOT NULL UNIQUE
);
-- 添加旅游线路分类数据:
INSERT INTO tab_category (cname) VALUES ('周边游'), ('出境游'), ('国内游'), ('港澳游');
SELECT * FROM tab_category;
-- 创建旅游线路表 tab_route
/*
rid 旅游线路主键,自动增长
rname 旅游线路名称非空,唯一,字符串 100
price 价格
rdate 上架时间,日期类型
cid 外键,所属分类
*/
CREATE TABLE tab_route(
rid INT PRIMARY KEY AUTO_INCREMENT,
rname VARCHAR(100) NOT NULL UNIQUE,
price DOUBLE,
rdate DATE,
cid INT,
FOREIGN KEY (cid) REFERENCES tab_category(cid)-- 简化的书写方式,省略了CONSTRAINT 外键名称
-- 系统会自动分配外键名称
);
-- 添加旅游线路数据
INSERT INTO tab_route VALUES
(NULL, '【厦门+鼓浪屿+南普陀寺+曾厝垵 高铁 3 天 惠贵团】尝味友鸭面线 住 1 晚鼓浪屿', 1499,'2018-01-27', 1),
(NULL, '【浪漫桂林 阳朔西街高铁 3 天纯玩 高级团】城徽象鼻山 兴坪漓江 西山公园', 699, '2018-02-22', 3),
(NULL, '【爆款¥1699 秒杀】泰国 曼谷 芭堤雅 金沙岛 杜拉拉水上市场 双飞六天【含送签费 泰风情 广州往返 特价团】', 1699, '2018-01-27', 2),
(NULL, '【经典•狮航 ¥2399 秒杀】巴厘岛双飞五天 抵玩【广州往返 特价团】', 2399, '2017-12-23',2),
(NULL, '香港迪士尼乐园自由行 2 天【永东跨境巴士广东至迪士尼去程交通+迪士尼一日门票+香港如心海景酒店暨会议中心标准房 1 晚住宿】', 799, '2018-04-10', 4);
SELECT * FROM tab_route;-- 用户表
/*
创建用户表 tab_user
uid 用户主键,自增长
username 用户名长度 100,唯一,非空
password 密码长度 30,非空
name 真实姓名长度 100
birthday 生日
sex 性别,定长字符串 1
telephone 手机号,字符串 11
email 邮箱,字符串长度 100
*/
CREATE TABLE tab_user (
uid INT PRIMARY KEY AUTO_INCREMENT,
username VARCHAR(100) UNIQUE NOT NULL,
PASSWORD VARCHAR(30) NOT NULL,
NAME VARCHAR(100),
birthday DATE,
sex CHAR(1) DEFAULT '男',
telephone VARCHAR(11),
email VARCHAR(100)
);
-- 添加用户数据
INSERT INTO tab_user VALUES
(NULL, 'cz110', 123456, '老王', '1977-07-07', '男', '13888888888', '66666@qq.com'),
(NULL, 'cz119', 654321, '小王', '1999-09-09', '男', '13999999999', '99999@qq.com');
SELECT * FROM tab_user;
/*
中间表:关联了用户表和线路表
创建收藏表 tab_favorite
rid 旅游线路 id,外键
date 收藏时间
uid 用户 id,外键
rid 和 uid 不能重复,设置复合主键,同一个用户不能收藏同一个线路两次
*/
CREATE TABLE tab_favorite (
rid INT,
DATE DATETIME,
uid INT,
-- 创建复合主键
PRIMARY KEY(rid,uid),
FOREIGN KEY (rid) REFERENCES tab_route(rid),
FOREIGN KEY(uid) REFERENCES tab_user(uid)
);
-- 增加收藏表数据
INSERT INTO tab_favorite VALUES (1, '2018-01-01', 1), -- 老王选择厦门
(2, '2018-02-11', 1), -- 老王选择桂林
(3, '2018-03-21', 1), -- 老王选择泰国
(2, '2018-04-21', 2), -- 小王选择桂林
(3, '2018-05-08', 2), -- 小王选择泰国
(5, '2018-06-02', 2); -- 小王选择迪士尼
SELECT * FROM tab_favorite;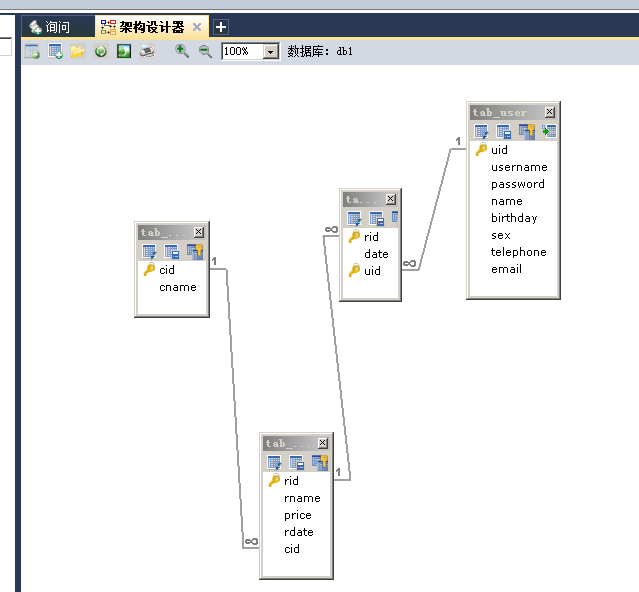
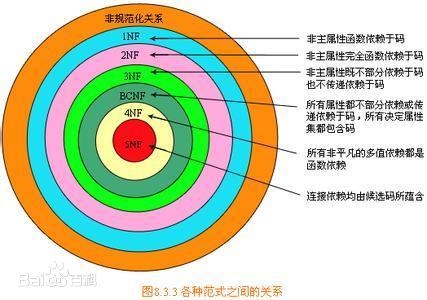
- 第一范式(1NF):每一列都是不可分割的原子数据项,而不能是集合,数组,记录等非原子数据项。
- 第二范式(2NF):在1NF的基础上,非码属性必须完全依赖于候选码(在1NF基础上消除非主属性对主码的部分函数依赖)
- 第三范式(3NF):在2NF基础上,任何非主属性不依赖于其它非主属性(在2NF基础上消除传递依赖)
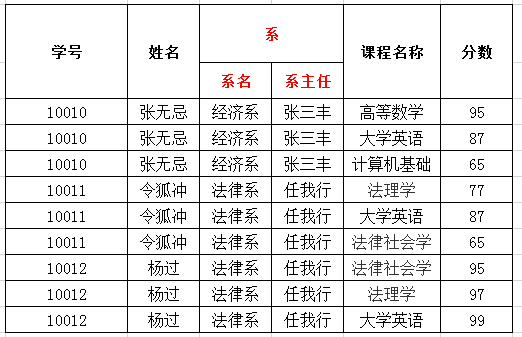
- 第一范式(1NF):每一列都是不可分割的原子数据项,而不能是集合,数组,记录等非原子数据项。
系这一列不是原子项,不满足1NF,应将其拆成两列
所有的数据库表都会满足1NF,无法创建复合
存在的问题
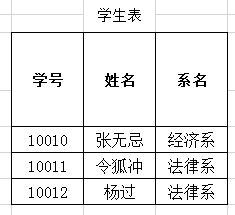
- 存在严重的数据冗余(重复):姓名、系名、系主任
- 数据添加存在问题:添加新开设的系和系主任时,数据不合法
- 数据删除存在问题:张无忌同学毕业了,删除数据会将系的数据 一起删除
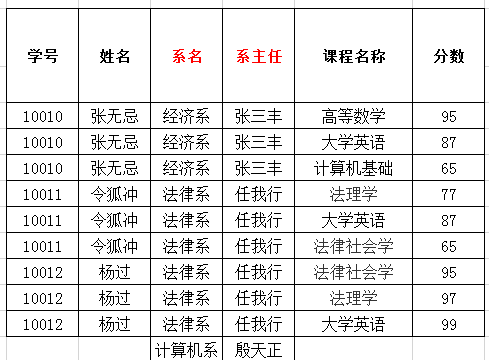
- 第二范式(2NF):在1NF的基础上,非主属性必须完全依赖于码(在1NF基础上消除非主属性对主码的部分函数依赖)
- 几个概念
- 函数依赖:A--->B,如果通过A属性或者属性组的值可以确定唯一B属性的值,则称B依赖于A
例如:学号--->姓名,姓名依赖于学号。学号确定不了分数(分数 不被学号依赖)
学号+课程名称--->分数,分数依赖于学号和课程名称构成的属性组 - 完全函数依赖:A-->B,如果A是一个属性组,则B属性值需要依赖于A属性组中所有的属性值
例如:(学号,课程名称)--->分数 - 部分函数依赖:A-->B,如果A是一个属性组,则B属性值的确定只需要依赖于A属性组中某一些值即可
例如:(学号,课程名称)-->姓名 - 传递函数依赖:A-->B,B-->C,如果通过A属性或者属性组的值可以确定唯一B属性的值,再通过B属性的值可以唯一确定C属性的值,则称C传递依赖于A
例如:学号-->系名-->系主任 - 码:如果在一张表中,一个属性或属性组被其他所有属性完全依赖,则称这个属性或属性组为该表的码
例如:学生信息表中的学号,并未被其他所有属性完全依赖
通过学号和课程名称,可以确定其他属性
(学号,课程名称)为该表中的码 - 主属性:码属性组中的所有属性
- 非主属性:除去码属性组的属性
- 消除部分依赖,实现完全依赖:做表的拆分
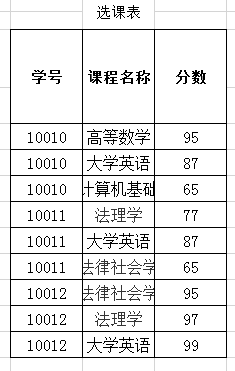
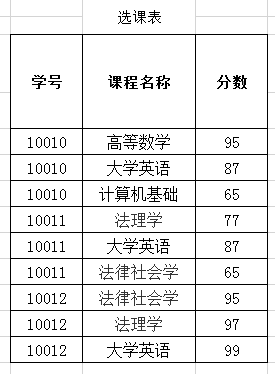 (学号,课程名称)是主属性组/码
(学号,课程名称)是主属性组/码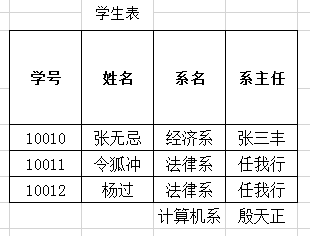 (学号)是主属性/码
(学号)是主属性/码 - 仍存在问题:
- .数据添加存在问题:添加新开设的系和系主任时,数据不合法
- 数据删除存在问题:张无忌同学毕业了,删除数据,会将系的数据一起删除。
- 第三范式(3NF):在2NF基础上,任何非主属性不依赖于其它非主属性(在2NF基础上消除传递依赖)
- 是否有传递依赖:学号-->系名-->系主任
- 解决:

- 消除了传递依赖 ,消除了上述添加和删除问题
- 总结
- 1NF:原子项
- 2NF:消除非主属性的部分依赖
- 3NF:消除传递依赖
- 语法:
- 备份:mysqldum -u用户名 -p密码 (数据库名)> 保存的路径


- 还原
- 登录数据库
- 创建数据库
- 使用数据库
- 执行文件:source 文件路径

JavaEE Day03 MySQL约束的更多相关文章
- day03 mysql外键 表的三种关系 单表查询 navicat
day03 mysql navicat 一.完整性约束之 外键 foreign key 一个表(关联表: 是从表)设置了外键字段的值, 对应的是另一个表的一条记录(被关联表: 是主 ...
- day03 MySQL数据库之主键与外键
day03 MySQL数据库之主键与外键 昨日内容回顾 针对库的基本SQL语句 # 增 create database meng; # 查 show databases; shwo create da ...
- MySQL 约束的讲解
MySQL 约束 作用:保证数据的完整性和一致性按照约束的作用范围分为:表级约束和行级约束.常见的约束类型包括: Not null(非空约束) Primary key (主键约束) Unique ke ...
- MySQL 约束和数据库设计
1.MySQL 约束: 1.约束的概念: 约束是一种限制,它通过对表的行或列的数据做出限制,来确保表的数据的完整性.唯一性. MySQL中,常用的几种约束: 约束类型: 非空 主键 唯一 外键 默认值 ...
- MySQL 约束
MySQL中约束保存在information_schema数据库的table_constraints中,可以通过该表查询约束信息: 约束主要完成对数据的检验,保证数据库数据的完整性:如果有相互依赖数据 ...
- MySQL约束
MySQL中约束保存在information_schema数据库的table_constraints中,可以通过该表查询约束信息: 常用5种约束: not null: 非空约束,指定某列不为空 uni ...
- SQLServer与MySQL约束/索引命名的一些差异总结
约束是数据库完整性的保证,主要分为:主键/外键/唯一键/默认值/check等类别,约束是一个逻辑概念,表示数据的某些特性(不能为空,唯一,必须满足某些条件等等),索引是一个逻辑与物理概念的结合,逻辑上 ...
- mysql约束以及数据库的修改
一.约束 1.约束保证数据完整性和一致性. 2.约束分为表级约束和列级约束. (1)表级约束(约束针对于两个或两个以上的字段使用) (2)列级约束(针对于一个字段使用) 3.约束类型有: (1)NOT ...
- MySQL 约束、表连接、表关联、索引
一.外键: 1.什么是外键 2.外键语法 3.外键的条件 4.添加外键 5.删除外键 1.什么是外键: 主键:是唯一标识一条记录,不能有重复的,不允许为空,用来保证数据完整性. 外键:是另一表的唯一性 ...
- mysql 约束和外键约束实例
1.约束保证数据的完整性和一致性. 2.约束分为表级约束和列级约束.(根据约束所针对的字段的数目的多少来决定) 列级约束:对一个数据列建立的约束 表级约束:对多个数据列建立的约束 列级约束即可以在列定 ...
随机推荐
- Elasticsearch:跨集群搜索 Cross-cluster search (CCS)
转载自:https://blog.csdn.net/UbuntuTouch/article/details/104588232 跨集群搜索(cross-cluster search)使您可以针对一个或 ...
- win10系统恢复默认的照片查看器
新建一个TXT文本文档,把以下代码复制粘贴到其中: 注:你可以根据需要按同样的格式增减或修改其中的图片格式代码 Windows Registry Editor Version 5.00 ; Chang ...
- python中类与对象的命名空间(静态属性的陷阱)、__dict__ 和 dir() 在继承中使用说明
1. 面向对象的概念 1)类是一类抽象的事物,对象是一个具体的事物:用类创建对象的过程,称为实例化. 2)类就是一个模子,只知道在这个模子里有什么属性.什么方法,但是不知道这些属性.方法具体是什么: ...
- Codeforces Round #710 (Div. 3)
emmm,就ac了3题 A题转换推下公式. tB题模拟,在第一个与最后一个变x后,直接i下标+k,判断当前下标前一个befor与最后一个last距离是否>k,是的话在当前下标往前找*字符然后改为 ...
- DDD-领域驱动(二)-贫血模型与充血模型
贫血模型 一般来说 贫血模型:**一个类中只有属性或者成员变量,没有方法 **!例如 DbFirst 从数据库同步实体过来, -- 对于一个系统刚开始的时候会觉得这时候是最舒服的,但是如果后期系统需要 ...
- 2022牛客OI赛前集训营-提高组(第一场) 奇怪的函数 根号很好用
奇怪的函数 考虑暴力,每次查询\(O(n)\)扫所有操作,修改\(O(1)\) 这启发我们平衡复杂度,考虑分块. 观察题目性质,可以发现,经过若干次操作后得到的结果一定是一个关于\(x\)的分段函数, ...
- 一天十道Java面试题----第五天(spring的事务传播机制------>mybatis的优缺点)
这里是参考B站上的大佬做的面试题笔记.大家也可以去看视频讲解!!! 文章目录 41.spring的事务传播机制 42 .spring事务什么时候会失效 43 .什么的是bean的自动装配.有哪些方式? ...
- golang中的选项模式
索引 https://waterflow.link/articles/1663835071801 当我在使用go-zero时,我看到了好多像下面这样的代码: ... type ( // RunOpti ...
- 知识图谱顶会论文(SIGIR-2022) MorsE:归纳知识图嵌入的元知识迁移
MorsE:归纳知识图嵌入的元知识迁移 论文题目: Meta-Knowledge Transfer for Inductive Knowledge Graph Embedding 论文地址: http ...
- 故事 --- Linux和UNIX之间的那些爱恨与情仇
Linux和UNIX具体有哪些关系及区别? UNIX 与 Linux 之间的关系是一个很有意思的话题.在目前主流的服务器端操作系统中,UNIX 诞生于 20 世纪 60 年代末,Windows 诞生于 ...