【BOOK】解析库—XPath
XPath—XML Path Language
1、安装 lxml库
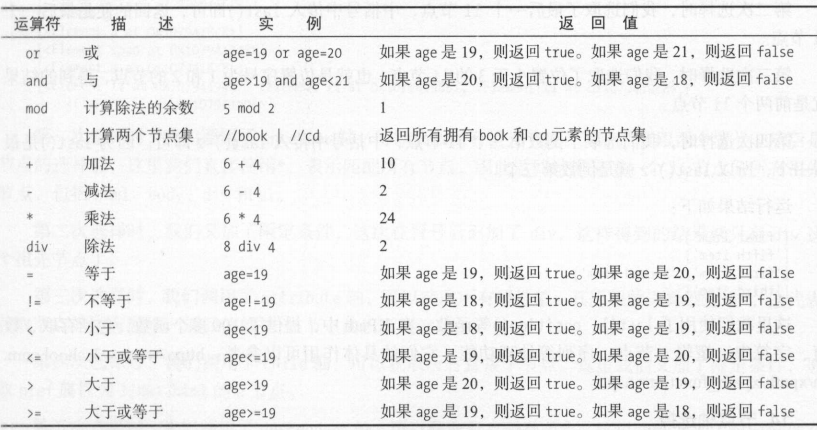
2、XPath常用规则

3、XPath解析页面
from lxml import etree text = '''
<div>
<ul>
<li calss='item-1'><a href='link1.html'> first item </a></li>
<li calss='item-2'><a href='link2.html'> second item
</ul>
</div>
'''
## 调用HTML类进行初始化,构造一个XPath对象
## etree可以自动修正html文本
html = etree.HTML(text)
## tostring()输出修正后的HTML代码,结果是bytes类型
result = etree.tostring(html)
print(result.decode('utf-8')) ## 读取文本文件进行解析
html = etree.parse('./test.html', etree.HTMLParser())
## *匹配所有节点 , 列表形式, 所有节点都是Element对象
result = html.xpath('//*')
print(result)
4、//* 获取所有节点
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
## *匹配所有节点 , 列表形式, 所有节点都是Element对象
result = html.xpath('//*')
print(result)
## 获取所有li节点
result1 = html.xpath('//li')
print(result1) # [<Element li at 0x34eca08>, <Element li at 0x34ec530>]
print(result1[0]) # 获取第一个li节点
5、/ 子节点
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
## 获取 li节点的所有a子节点
result2 = html.xpath('//li/a')
print(result2)
6、.. 父节点
@ 属性
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
## 获取父节点 ..
## 获取属性 href 为"link2.html"的a节点的父亲节点的class属性值
result3 = html.xpath('//a[@href="link2.html"]/../@class')
print(result3) ## ['item-2']
7、text() 文本获取
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
## text() 获取节点中的文本
result4 = html.xpath('//li[@class="item-1"]//text()')
print(result4) result5 = html.xpath('//li[@class="item-1"]/a/text()')
print(result5)
8、contains() 属性多指匹配
from lxml import etree
## li节点class属性有多个值
text = '''
<li class="li li-first"><a href="link-html">first item</a></li>
'''
html = etree.HTML(text)
## 属性多值匹配 contains(@class, "li")
result = html.xpath('//li[contains(@class, "li")]/a/text()')
print(result)
9、多属性匹配
from lxml import etree
## li节点有多个属性
text = '''
<li class="li li-first" name="item"><a href="link-html">first item</a></li>
'''
html = etree.HTML(text)
## 多属性匹配 and
result = html.xpath('//li[contains(@class, "li") and @name="item"]/a/text()')
print(result)
10、按序选择
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
## 按序选择
## 序号以1开头 选取第一个li节点
result1 = html.xpath('//li[1]/a/text()')
print(result1) # [' first item ']
## 选取最后一个li节点
result2 = html.xpath('//li[last()]/a/text()')
print(result2) # [' sixth item']
## 选取位置小于3的li节点
result3 = html.xpath('//li[position()<3]/a/text()')
print(result3) # [' first item ', ' second item']
## 选取倒数第三个li节点
result4 = html.xpath('//li[last()-2]/a/text()')
print(result4) # [' forth item']
11、节点轴选择
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
## 节点轴选择
## ancestor::* 获取所有的祖先节点
result1 = html.xpath('//li[1]/ancestor::*')
print(result1)
## ancestor::div 获取祖先节点 div
result2 = html.xpath('//li[1]/ancestor::div')
print(result2)
## attribute::* 获取第一个li节点所有的属性值
result3 = html.xpath('//li[1]/attribute::*')
print(result3)
## child::* 获取第一个li节点所有的孩子节点
result4 = html.xpath('//li[1]/child::*')
print(result4)
## descendant::* 获取第一个li节点所有的子孙节点
result5 = html.xpath('//li[1]/descendant::*')
print(result5)
## following::* 获取第一个li节点之后的所有节点
result6 = html.xpath('//li[1]/following::*')
print(result6)
## following-sibling::* 获取第一个li节点之后的所有同级节点
result6 = html.xpath('//li[1]/following-sibling::*')
print(result6)
【BOOK】解析库—XPath的更多相关文章
- 网页解析库-Xpath语法
网页解析库 简介 除了正则表达式外,还有其他方便快捷的页面解析工具 如:lxml (xpath语法) bs4 pyquery等 Xpath 全称XML Path Language, 即XML路径语言, ...
- Python3编写网络爬虫05-基本解析库XPath的使用
一.XPath 全称 XML Path Language 是一门在XML文档中 查找信息的语言 最初是用来搜寻XML文档的 但是它同样适用于HTML文档的搜索 XPath 的选择功能十分强大,它提供了 ...
- python爬虫基础04-网页解析库xpath
更简单高效的HTML数据提取-Xpath 本文地址:https://www.jianshu.com/p/90e4b83575e2 XPath 是一门在 XML 文档中查找信息的语言.XPath 用于在 ...
- 爬虫之解析库Xpath
简介 XPath即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言. XPath基于XML的树状结构,提供在数据结构树中找寻节点的能力.起初XPat ...
- 爬虫解析库xpath
# xpath简介 XPath即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言.用于在 XML 文档中通过元素和属性进行导航. XPath基于XM ...
- 解析库--XPath
from lxml import etree 2 text = ''' 3 <div> 4 <ul> 5 <li class = "item-0"&g ...
- BeautifulSoup与Xpath解析库总结
一.BeautifulSoup解析库 1.快速开始 html_doc = """ <html><head><title>The Dor ...
- (最全)Xpath、Beautiful Soup、Pyquery三种解析库解析html 功能概括
一.Xpath 解析 xpath:是一种在XMl.html文档中查找信息的语言,利用了lxml库对HTML解析获取数据. Xpath常用规则: nodename :选取此节点的所有子节点 // : ...
- 网络爬虫之Selenium模块和Xpath表达式+Lxml解析库的使用
实际生产环境下,我们一般使用lxml的xpath来解析出我们想要的数据,本篇博客将重点整理Selenium和Xpath表达式,关于CSS选择器,将另外再整理一篇! 一.介绍: selenium最初是一 ...
- xpath beautiful pyquery三种解析库
这两天看了一下python常用的三种解析库,写篇随笔,整理一下思路.太菜了,若有错误的地方,欢迎大家随时指正.......(conme on.......) 爬取网页数据一般会经过 获取信息-> ...
随机推荐
- 【DM论文阅读杂记】复杂社区网络
Paper Title Community Structure in Time-Dependent, Multiscale, and Multiplex Networks Basic algorith ...
- C# RSA加密解密 签名实现
class RSACryptoItem { public RSACryptoServiceProvider Provider; public List<byte> PubKeyBytes; ...
- CSP202104-4校门外的树
`#include include include include include include include include include include include include us ...
- .NET Core基础:白话管道中间件
在Asp.Net Core中,管道往往伴随着请求一起出现.客户端发起Http请求,服务端去响应这个请求,之间的过程都在管道内进行. 举一个生活中比较常见的例子:旅游景区. 我们都知道,有些景区大门离景 ...
- Object.create() 方浅析
Object.create()方法创建一个新对象,使用现有的对象来提供新创建的对象的__proto__. Object.create(proto[, propertiesObject]) 参数 pro ...
- 一加5T刷入魔趣
0.准备工作 1.安装adb工具 2.下载twrp 3.5t系统包. 1.解锁bootloader 先进入原版系统,打开开发者选项,允许USB调试,勾选允许OEM解锁,高级重启选项 打开命令行输入: ...
- comment out one line in the file with sed
sed -i "/test2/s/^/#/" test.log https://jaminzhang.github.io/linux/sed-command-usage-summa ...
- 滚动 Scroller OverScroller
原文:https://www.baidu.com/link?url=26iKhqGV7w87fqTiCTCwQc3VPcCbedUpAlddWm3uHsEXAGaeH47xY8QCZNGcORGBAU ...
- 使用Kali破解无线密码
1.查看网卡信息,是否有wlanX网卡ifconfig 2.启动网卡监听模式 airmon-ng start wlan0 检查下是否处于监听模型:ifconfig查看一下,如果网卡名加上了mon后则成 ...
- linux 查询目录文件大小