python之爬虫一
python爬虫学习
1爬虫室什么
网络爬虫(Web Spider)又称“网络蜘蛛”或“网络机器人”,它是一种按照一定规则从 Internet 中获取网页内容的程序。广为人知的“搜索引擎”就是最常见的爬虫程序,比如当我们使用百度引擎搜索关键字时,“百度蜘蛛”就会根据您输入的关键字去互联网资源中抓取相应的页面。
Python 爬虫指的是用 Python 语言来编写爬虫程序。除了 Python 外,其他语言也可以编写,比如 Java、PHP 等,不过相比较而言,Python 更为简单和实用。一方面, Python 提供了许多可以应用于爬虫的库和模块;另一方面, Python 语法简单、易读,更适合于初学者学习,因此 Python 爬虫几乎成了网络爬虫的代名词。网络爬虫主要用途是采集数据,它是数据分析不可或缺的工具之一。许多公司专门设立了 Python 爬虫工程师岗位,该岗位的职责就是为公司的业务拓展提供数据支持。除此之外,网络爬虫也给我们的生活带来便利,比如抢购火车票、飞机票等。
教程特点
本套教程专门为 Python 爬虫的初学者打造,是一套非常不错的入门教程,同时它也适用于数据分析师进阶学习。如您对 Python 爬虫充满兴趣,那么本套教程将非常适合您。
本套教程从最简单的网页分析讲起,并对 Python 网络爬虫常用的请求模块、解析模块做了重点讲解。不仅如此,教程中还介绍了与 Python 爬虫有关的 Selenium 框架和 Scrapy 框架。为了让初学者“学到做到”,我们采用了“知识点讲解+爬虫实例分析”相结合的写作方式,降低初学者的学习门槛。通过学习本套教程,您将全面掌握 Python 爬虫的相关知识。
2审查网页元素
对于一个优秀的爬虫工程师而言,要善于发现网页元素的规律,并且能从中提炼出有效的信息。因此,在动手编写爬虫程序前,必须要对网页元素进行审查。本节将讲解如何使用“浏览器”审查网页元素。
浏览器都自带检查元素的功能,不同的浏览器对该功能的叫法不同, 谷歌(Chrome)浏览器称为“检查”,而 Firefox 则称“查看元素”,尽管如此,但它们的功却是相同的,本教程推荐使用谷歌浏览器。
检查百度首页
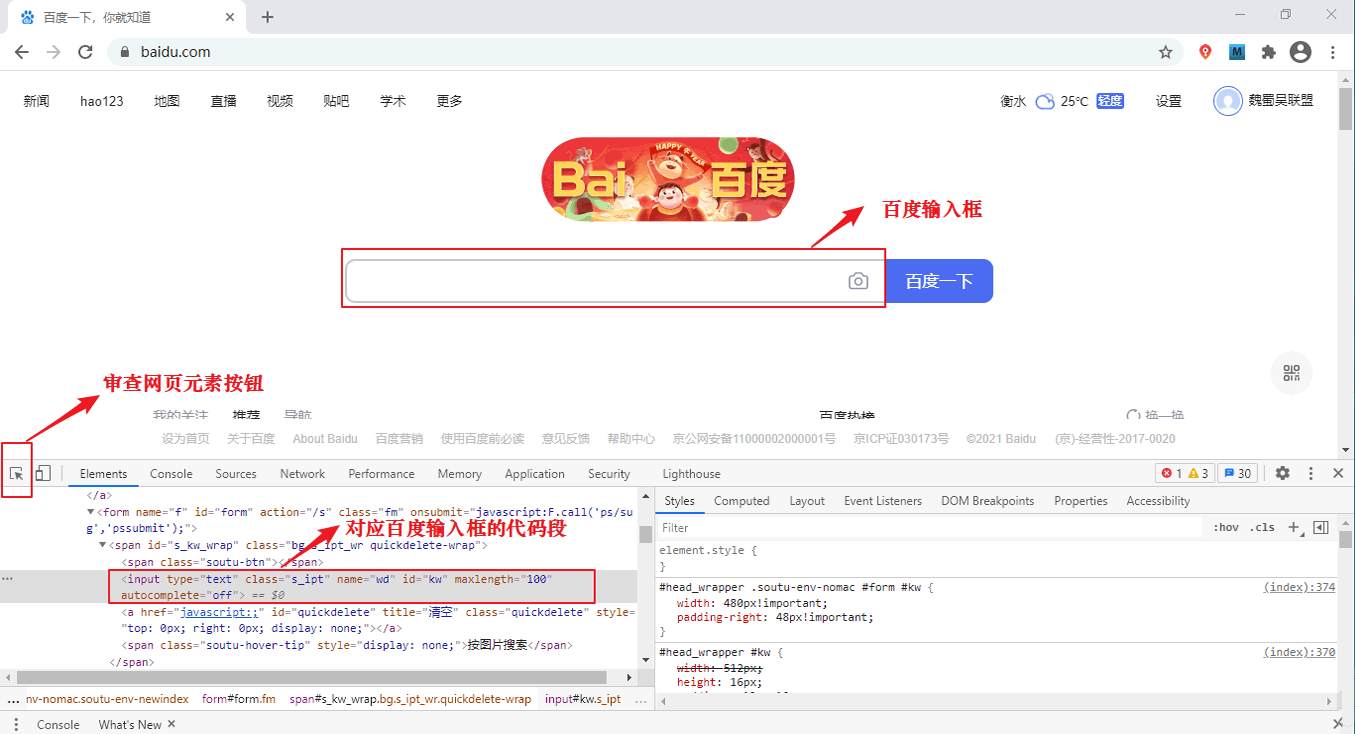
下面以检查百度首页为例:首先使用 Chrome 浏览器打开百度,然后在百度首页的空白处点击鼠标右键(或者按快捷键:F12),在出现的会话框中点击“检查”,并进行如图所示操作:
图1:检查百度首页元素(点击看高清图)
{kind=link}
点击审查元素按钮,然后将鼠标移动至您想检查的位置,比如百度的输入框,然后单击,此时就会将该位置的代码段显示出来(如图 1 所示)。最后在该代码段处点击右键,在出现的会话框中选择 Copy 选项卡,并在二级会话框内选择“Copy element”,如下所示:
图2:Copy代码段
百度输入框的代码如下所示:
- <input type="text" class="s_ipt" name="wd" id="kw" maxlength="100" autocomplete="off">
依照上述方法,您可以检查页面内的所有元素。
编辑网页代码
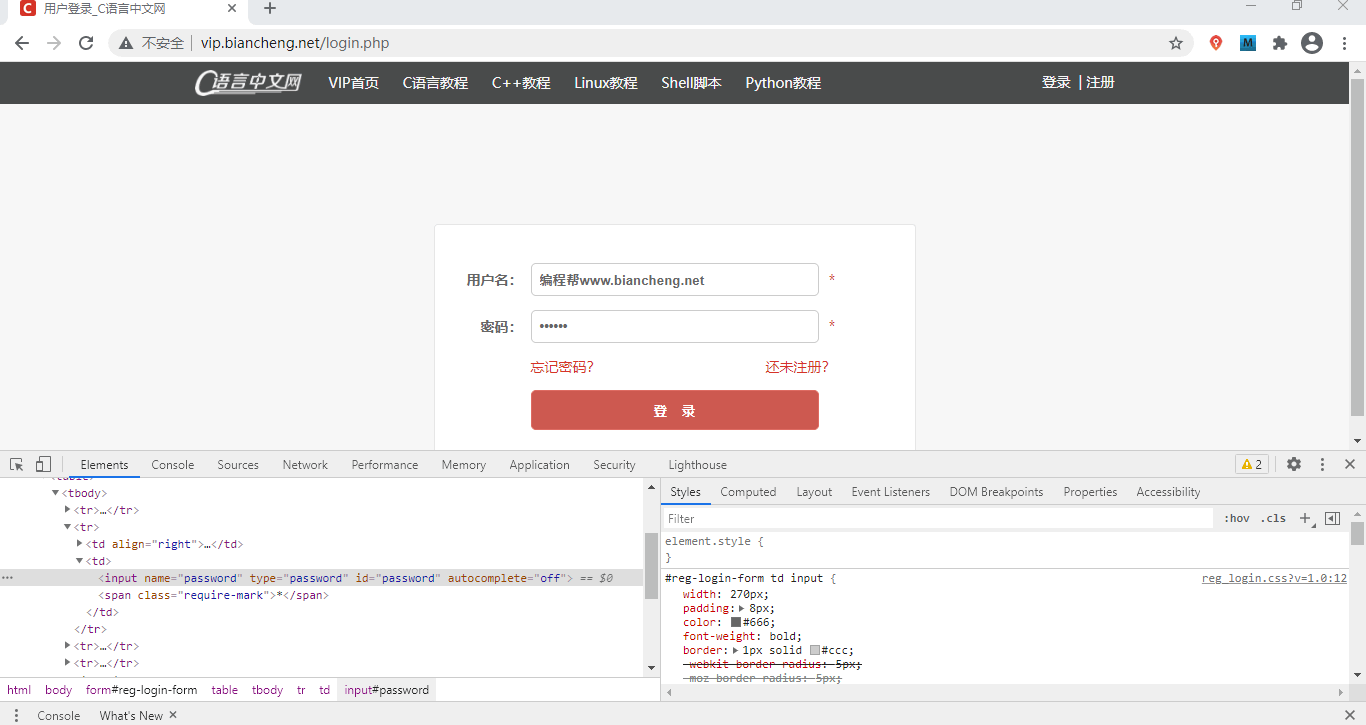
通过检查元素也可以更改网页代码,下面通过C语言中文网登录界面进行简单演示:
图2:检查网页元素(点击看高清图)
{kind=link}
检查密码框的 HTML 代码,代码如下所示:
- <input name="password" type="password" id="password" autocomplete="off">
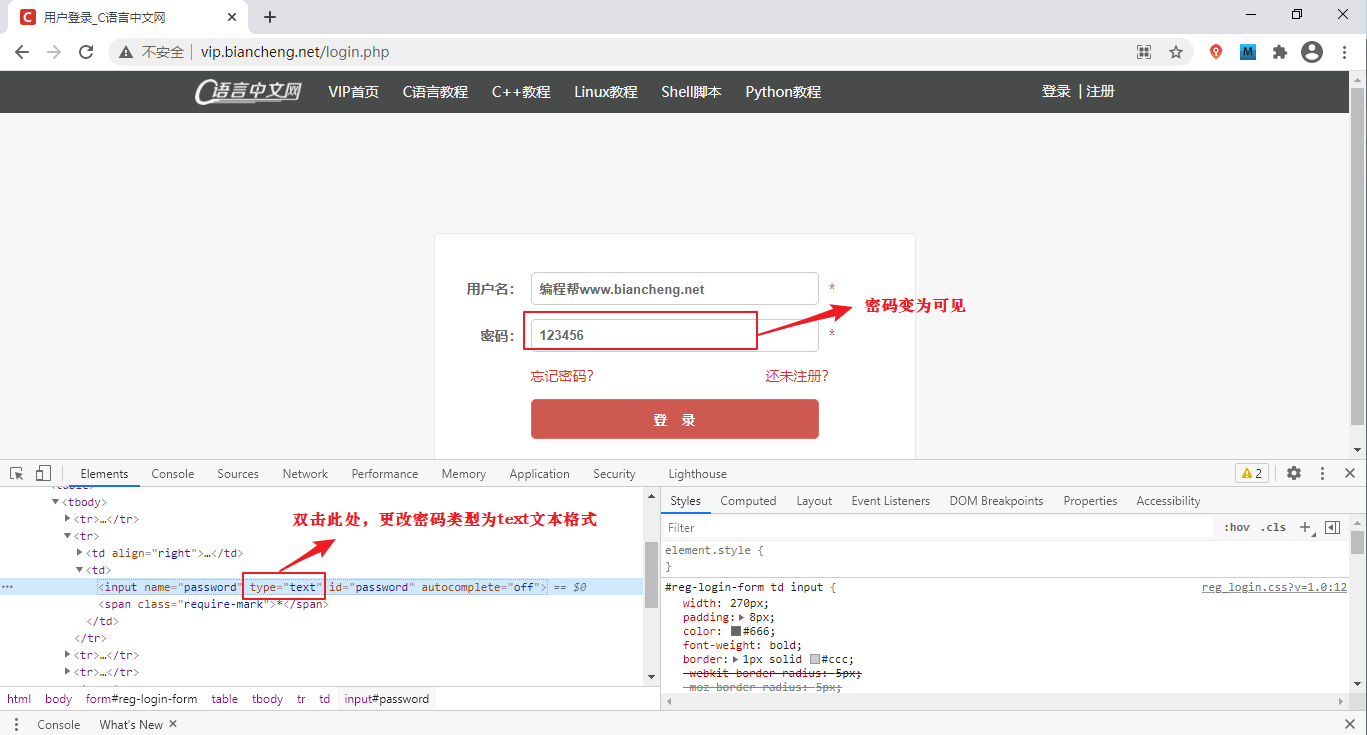
只要在显示出的代码段上稍微做一下更改,密码就会变为可见状态。如下图所示:
图3:检查网页元素(点击看高清图)
{kind=link}
双击 type="password" 将输入框类型更改为 text,此类操作适用于所有网站的登录界面。但是需要注意,您做的更改仅限本次有效,当关闭网页后,会自动恢复为原来的状态。
检查网页结构
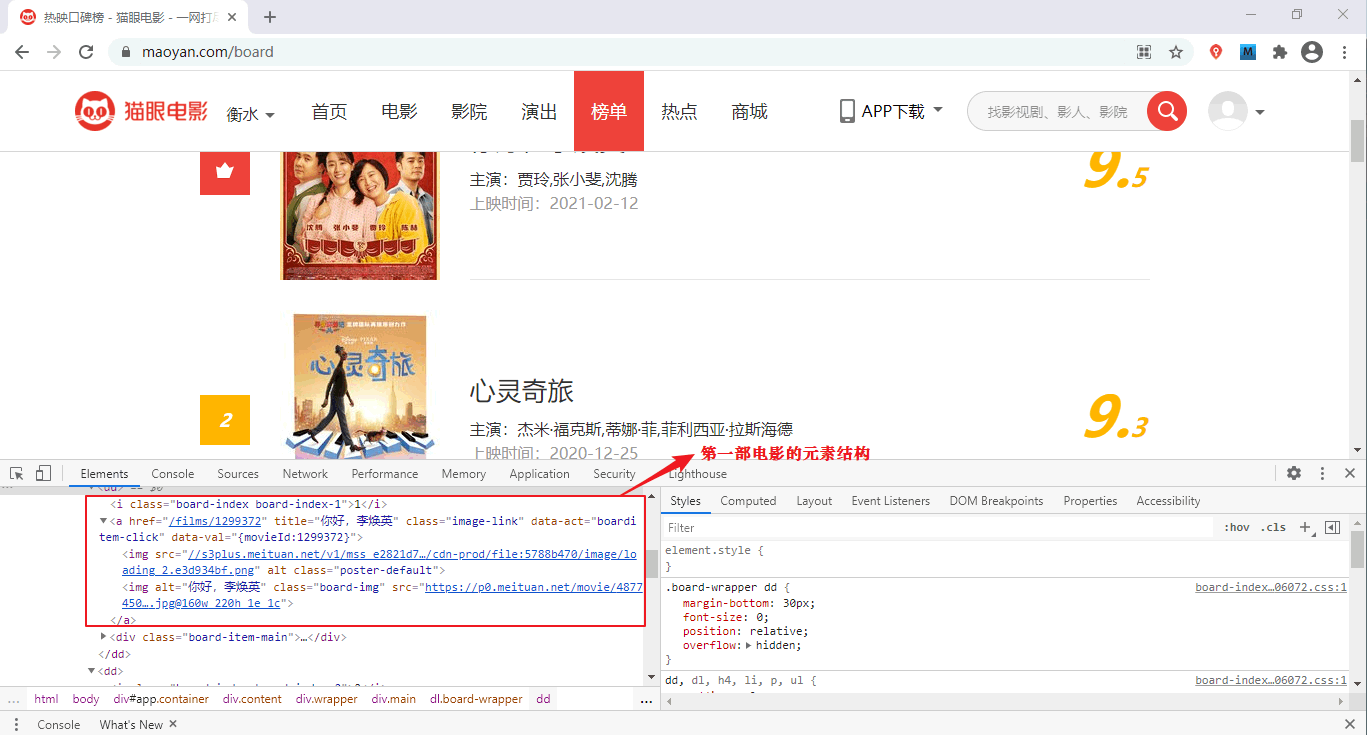
对于爬虫而言,检查网页结构是最为关键的一步,需要对网页进行分析,并找出信息元素的相似性。下面以猫眼电影网为例,检查每部影片的 HTML 元素结构。如下所示:
图4:检查网页结构(点击看高清图)
{kind=link}
第一部影片的代码段如下所示:
- <div class="board-item-main">
- <div class="board-item-content">
- <div class="movie-item-info">
- <p class="name"><a href="/films/1299372" title="你好,李焕英" data-act="boarditem-click" data-val="{movieId:1299372}">你好,李焕英</a></p>
- <p class="star">
- 主演:贾玲,张小斐,沈腾
- </p>
- <p class="releasetime">上映时间:2021-02-12</p> </div>
- <div class="movie-item-number score-num">
- <p class="score"><i class="integer">9.</i><i class="fraction">5</i></p>
- </div>
- </div>
- </div>
接下来检查第二部影片的代码,如下所示:
- <div class="board-item-main">
- <div class="board-item-content">
- <div class="movie-item-info">
- <p class="name"><a href="/films/553231" title="心灵奇旅" data-act="boarditem-click" data-val="{movieId:553231}">心灵奇旅</a></p>
- <p class="star">
- 主演:杰米·福克斯,蒂娜·菲,菲利西亚·拉斯海德
- </p>
- <p class="releasetime">上映时间:2020-12-25</p> </div>
- <div class="movie-item-number score-num">
- <p class="score"><i class="integer">9.</i><i class="fraction">3</i></p>
- </div>
- </div>
- </div>
经过对比发现,除了每部影片的信息不同之外,它们的 HTML 结构是相同的,比如每部影片都使用<dd></dd>标签包裹起来。这里我们只检查了两部影片,在实际编写时,你可以多检查几部,从而确定它们的 HTML 结构是相同的。
提示:通过检查网页结构,然后发现规律,这是编写爬虫程序最为重要的一步。
3知识准备
1) Python语言
Python 爬虫作为 Python 编程的进阶知识,要求学习者具备较好的 Python 编程基础。对于没有基础的小伙伴而言,建议阅读《Python基础教程》,这套教程通俗易懂,非常适合初学者学习,并且教程作者亲自答疑解惑,帮您实现 Python 快速入门。
同时,了解 Python 语言的多进程与多线程(参考《Python并发编程》),并熟悉正则表达式语法,也有助于您编写爬虫程序。
注意:关于正则表达式,Python 提供了专门的 re 模块,详细可参考《Python re模块》。
2) Web前端
了解 Web 前端的基本知识,比如 HTML、CSS、JavaScript,这能够帮助你分析网页结构,提炼出有效信息。推荐阅读《HTML入门教程》、《CSS教程》、《JS入门教程》。
3) HTTP协议
掌握 OSI 七层网络模型,了解 TCP/IP 协议、HTTP 协议,这些知识将帮助您了解网络请求(GET 请求、POST 请求)和网络传输的基本原理。同时,也有助您了解爬虫程序的编写逻辑,这里推荐阅读《TCP/IP协议入门教程》。
图1:OSI 网络七层模型
4第一个程序
获取网页html信息
1) 获取响应对象
向百度(http://www.baidu.com/)发起请求,获取百度首页的 HTML 信息,代码如下:
- #导包,发起请求使用urllib库的request请求模块
- import urllib.request
- # urlopen()向URL发请求,返回响应对象,注意url必须完整
- response=urllib.request.urlopen('http://www.baidu.com/')
- print(response)
上述代码会返回百度首页的响应对象, 其中 urlopen() 表示打开一个网页地址。注意:请求的 url 必须带有 http 或者 https 传输协议。
输出结果,如下所示:
<http.client.HTTPResponse object at 0x032F0F90>
上述代码也有另外一种导包方式,也就是使用 from,代码如下所示:
- #发起请求使用urllib库的request请求模块
- from urllib import request
- response=request.urlopen('http://www.baidu.com/')
- print(response)
2) 输出HTML信息
在上述代码的基础上继续编写如下代码:
- #提取响应内容
- html = response.read().decode('utf-8')
- #打印响应内容
- print(html)
输出结果如下,由于篇幅过长,此处只做了简单显示:
- <!DOCTYPE html><!--STATUS OK--> <html><head><meta http-equiv="Content-Type" content="text/html;charset=utf-8"><meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1"><meta content="always" name="referrer"><meta name="theme-color" content="#2932e1"><meta name="description" content="全球最大的中文搜索引擎、致力于让网民更便捷地获取信息,找到...">...</html>
通过调用 response 响应对象的 read() 方法提取 HTML 信息,该方法返回的结果是字节串类型(bytes),因此需要使用 decode() 转换为字符串。程序完整的代码程序如下:
- import urllib.request
- # urlopen()向URL发请求,返回响应对象
- response=urllib.request.urlopen('http://www.baidu.com/')
- # 提取响应内容
- html = response.read().decode('utf-8')
- # 打印响应内容
- print(html)
通过上述代码获取了百度首页的 html 信息,这是最简单、最初级的爬虫程序。后续我们还学习如何分析网页结构、解析网页数据,以及存储数据等。
常用方法
在本节您认识了第一个爬虫库 urllib,下面关于 urllib 做简单总结。
1) urlopen()
表示向网站发起请求并获取响应对象,如下所示:
urllib.request.urlopen(url,timeout)
urlopen() 有两个参数,说明如下:
- url:表示要爬取数据的 url 地址。
- timeout:设置等待超时时间,指定时间内未得到响应则抛出超时异常。
2) Request()
该方法用于创建请求对象、包装请求头,比如重构 User-Agent(即用户代理,指用户使用的浏览器)使程序更像人类的请求,而非机器。重构 User-Agent 是爬虫和反爬虫斗争的第一步。在下一节会做详细介绍。
urllib.request.Request(url,headers)
参数说明如下:
- url:请求的URL地址。
- headers:重构请求头。
3) html响应对象方法
- bytes = response.read() # read()返回结果为 bytes 数据类型
- string = response.read().decode() # decode()将字节串转换为 string 类型
- url = response.geturl() # 返回响应对象的URL地址
- code = response.getcode() # 返回请求时的HTTP响应码
4) 编码解码操作
#字符串转换为字节码
string.encode("utf-8")
#字节码转换为字符串
bytes.decode("utf-8")
5user-agent代理
Ua检测网站https://useragent.buyaocha.com/
User-Agent 即用户代理,简称“UA”,它是一个特殊字符串头。网站服务器通过识别 “UA”来确定用户所使用的操作系统版本、CPU 类型、浏览器版本等信息。而网站服务器则通过判断 UA 来给客户端发送不同的页面。
我们知道,网络爬虫使用程序代码来访问网站,而非人类亲自点击访问,因此爬虫程序也被称为“网络机器人”。绝大多数网站都具备一定的反爬能力,禁止网爬虫大量地访问网站,以免给网站服务器带来压力。本节即将要讲解的 User-Agent 就是反爬策略的第一步。
网站通过识别请求头中 User-Agent 信息来判断是否是爬虫访问网站。如果是,网站首先对该 IP 进行预警,对其进行重点监控,当发现该 IP 超过规定时间内的访问次数, 将在一段时间内禁止其再次访问网站。
常见的 User-Agent 请求头,如下所示:
|
常见的 User-Agent 汇总表 |
||
|
系统 |
浏览器 |
User-Agent字符串 |
|
Mac |
Chrome |
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36 |
|
Mac |
Firefox |
Mozilla/5.0 (Macintosh; Intel Mac OS X 10.12; rv:65.0) Gecko/20100101 Firefox/65.0 |
|
Mac |
Safari |
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/12.0.3 Safari/605.1.15 |
|
Windows |
Edge |
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36 Edge/18.17763 |
|
Windows |
IE |
Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko |
|
Windows |
Chrome |
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36 |
|
iOS |
Chrome |
Mozilla/5.0 (iPhone; CPU iPhone OS 7_0_4 like Mac OS X) AppleWebKit/537.51.1 (KHTML, like Gecko) CriOS/31.0.1650.18 Mobile/11B554a Safari/8536.25 |
|
iOS |
Safari |
Mozilla/5.0 (iPhone; CPU iPhone OS 8_3 like Mac OS X) AppleWebKit/600.1.4 (KHTML, like Gecko) Version/8.0 Mobile/12F70 Safari/600.1.4 |
|
Android |
Chrome |
Mozilla/5.0 (Linux; Android 4.2.1; M040 Build/JOP40D) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.59 Mobile Safari/537.36 |
|
Android |
Webkit |
Mozilla/5.0 (Linux; U; Android 4.4.4; zh-cn; M351 Build/KTU84P) AppleWebKit/534.30 (KHTML, like Gecko) Version/4.0 Mobile Safari/534.30 |
使用上表中的浏览器 UA,我们可以很方便的构建出 User-Agent。通过在线识别工具,可以查看本机的浏览器版本以及 UA 信息,如下所示:
|
当前浏览器UA信息 |
|
|
浏览器名称 |
Chrome |
|
浏览器版本 |
88.0.4324.182 |
|
系统平台 |
Windows |
|
UA信息 |
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36 |
若想更多地了解浏览器 UA 信息(包含移动端、PC端)可参考《常用浏览器User-Agent》。
爬虫程序UA信息
下面,通过向 HTTP 测试网站(http://httpbin.org/)发送 GET 请求来查看请求头信息,从而获取爬虫程序的 UA。代码如下所示:
- #导入模块
- import urllib.request
- #向网站发送get请求
- response=urllib.request.urlopen('http://httpbin.org/get')
- html = response.read().decode()
- print(html)
程序运行后,输出的请求头信息如下所示:
{
"args": {},
#请求头信息
"headers": {
"Accept-Encoding": "identity",
"Host": "httpbin.org",
"User-Agent": "Python-urllib/3.7", #UserAgent信息包含在请求头中!
"X-Amzn-Trace-Id": "Root=1-6034954b-1cb061183308ae920668ec4c"
},
"origin": "121.17.25.194",
"url": "http://httpbin.org/get"
}
从输出结果可以看出,User-Agent 竟然是 Python-urllib/3.7,这显然是爬虫程序访问网站。因此就需要重构 User-Agent,将其伪装成“浏览器”访问网站。
注意:httpbin.org 这个网站能测试 HTTP 请求和响应的各种信息,比如 cookie、IP、headers 和登录验证等,且支持 GET、POST 等多种方法,对 Web 开发和测试很有帮助。
重构爬虫UA信息
下面使用urllib.request.Request()方法重构 User-Agent 信息,代码如下所示:
- from urllib import request
- # 定义变量:URL 与 headers
- url = 'http://httpbin.org/get' #向测试网站发送请求
- #重构请求头,伪装成 Mac火狐浏览器访问,可以使用上表中任意浏览器的UA信息
- headers = {
- 'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.12; rv:65.0) Gecko/20100101 Firefox/65.0'}
- # 1、创建请求对象,包装ua信息
- req = request.Request(url=url,headers=headers)
- # 2、发送请求,获取响应对象
- res = request.urlopen(req)
- # 3、提取响应内容
- html = res.read().decode('utf-8')
- print(html)
程序的运行结果,如下所示:
{
"args": {},
"headers": {
"Accept-Encoding": "identity",
"Host": "httpbin.org",
#伪装成了Mac火狐浏览器
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.12; rv:65.0) Gecko/20100101 Firefox/65.0",
"X-Amzn-Trace-Id": "Root=1-6034a52f-372ca79027da685c3712e5f6"
},
"origin": "121.17.25.194",
"url": "http://httpbin.org/get"
}
6user=agent代理
在编写爬虫程序时,一般都会构建一个 User-Agent (用户代理)池,就是把多个浏览器的 UA 信息放进列表中,然后再从中随机选择。构建用户代理池,能够避免总是使用一个 UA 来访问网站,因为短时间内总使用一个 UA 高频率访问的网站,可能会引起网站的警觉,从而封杀掉 IP。
自定义UA代理池
构建代理池的方法也非常简单,在您的 Pycharm 工作目录中定义一个 ua_info.py 文件,并将以下 UA 信息以列表的形式粘贴到该文件中,如下所示:
ua_list = [
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11',
'User-Agent:Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11',
'Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0',
' Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1',
' Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
]
经过上述操作,用户代理池就构建成功。
模块随机获取UA
您也可以使用专门第三方的模块来随机获取浏览器 UA 信息,不过该模块需要单独安装,安装方式如下:
pip install fake-useragent
下载安装成功后,演示如下代码:
- from fake_useragent import UserAgent
- #实例化一个对象
- ua=UserAgent()
- #随机获取一个ie浏览器ua
- print(ua.ie)
- print(ua.ie)
- #随机获取一个火狐浏览器ua
- print(ua.firefox)
- print(ua.firefox)
输出结果:
#随机获取ie的ua信息
Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.0; Trident/4.0; GTB7.4; InfoPath.3; SV1; .NET CLR 3.1.76908; WOW64; en-US)
Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0
#随机获取火狐的ua信息
Mozilla/5.0 (Macintosh; Intel Mac OS X 10.8; rv:21.0) Gecko/20100101 Firefox/21.0
Mozilla/5.0 (Windows NT 5.0; rv:21.0) Gecko/20100101 Firefox/21.0
7rul编码和解码
当 URL 路径或者查询参数中,带有中文或者特殊字符的时候,就需要对 URL 进行编码(采用十六进制编码格式)。URL 编码的原则是使用安全字符去表示那些不安全的字符。
安全字符,指的是没有特殊用途或者特殊意义的字符。
URL基本组成
URL 是由一些简单的组件构成,比如协议、域名、端口号、路径和查询字符串等,示例如下:
http://www.biancheng.net/index?param=10
路径和查询字符串之间使用问号?隔开。上述示例的域名为 www.biancheng.net,路径为 index,查询字符串为 param=1。
URL 中规定了一些具有特殊意义的字符,常被用来分隔两个不同的 URL 组件,这些字符被称为保留字符。例如:
- 冒号:用于分隔协议和主机组件,斜杠用于分隔主机和路径
- ?:用于分隔路径和查询参数等。
- =用于表示查询参数中的键值对。
- &符号用于分隔查询多个键值对。
其余常用的保留字符有:/ . ... # @ $ + ; %
哪些字符需要编码
URL 之所以需要编码,是因为 URL 中的某些字符会引起歧义,比如 URL 查询参数中包含了”&”或者”%”就会造成服务器解析错误;再比如,URL 的编码格式采用的是 ASCII 码而非 Unicode 格式,这表明 URL 中不允许包含任何非 ASCII 字符(比如中文),否则就会造成 URL 解析错误。
URL 编码协议规定(RFC3986 协议):URL 中只允许使用 ASCII 字符集可以显示的字符,比如英文字母、数字、和- _ . ~ ! *这 6 个特殊字符。当在 URL 中使用不属于 ASCII 字符集的字符时,就要使用特殊的符号对该字符进行编码,比如空格需要用%20来表示。
除了无法显示的字符需要编码外,还需要对 URL 中的部分保留字符和不安全字符进行编码。下面列举了部分不安全字符:
[ ] < > " " { } | \ ^ * · ‘ ’ 等
下面示例,查询字符串中包含一些特殊字符,这些特殊字符不需要编码:
http://www.biancheng.net/index?param=10!*¶m1=20!-~_
下表对 URL 中部分保留字符和不安全字符进行了说明:
|
URL特殊字符编码 |
||
|
字符 |
含义 |
十六进制值编码 |
|
+ |
URL 中 + 号表示空格 |
%2B |
|
空格 |
URL中的空格可以编码为 + 号或者 %20 |
%20 |
|
/ |
分隔目录和子目录 |
%2F |
|
? |
分隔实际的 URL 和参数 |
%3F |
|
% |
指定特殊字符 |
%25 |
|
# |
表示书签 |
%23 |
|
& |
URL 中指定的参数间的分隔符 |
%26 |
|
= |
URL 中指定参数的值 |
%3D |
下面简单总结一下,哪些字符需要编码,分为以下三种情况:
- ASCII 表中没有对应的可显示字符,例如,汉字。
- 不安全字符,包括:# ”% <> [] {} | \ ^ ` 。
- 部分保留字符,即 & / : ; = ? @ 。
Python实现编码与解码
Python 的标准库urllib.parse模块中提供了用来编码和解码的方法,分别是 urlencode() 与 unquote() 方法。
|
方法 |
说明 |
|
urlencode() |
该方法实现了对 url 地址的编码操作 |
|
unquote() |
该方法将编码后的 url 地址进行还原,被称为解码 |
1) 编码urlencode()
下面以百度搜索为例进行讲解。首先打开百度首页,在搜索框中输入“爬虫”,然后点击“百度一下”。当搜索结果显示后,此时地址栏的 URL 信息,如下所示:
https://www.baidu.com/s?wd=爬虫&rsv_spt=1&rsv_iqid=0xa3ca348c0001a2ab&issp=1&f=8&rsv_bp=1&rsv_idx=2&ie=utf-8&tn=baiduhome_pg&rsv_enter=1&rsv_dl=ib&rsv_sug3=8&rsv_sug1=7&rsv_sug7=101
可以看出 URL 中有很多的查询字符串,而第一个查询字符串就是“wd=爬虫”,其中 wd 表示查询字符串的键,而“爬虫”则代表您输入的值。
在网页地址栏中删除多余的查询字符串,最后显示的 URL 如下所示:
https://www.baidu.com/s?wd=爬虫
使用搜索修改后的 URL 进行搜索,依然会得到相同页面。因此可知“wd”参数是百度搜索的关键查询参数。下面编写爬虫程序对 “wd=爬虫”进行编码,如下所示:
- #导入parse模块
- from urllib import parse
- #构建查询字符串字典
- query_string = {
- 'wd' : '爬虫'
- }
- #调用parse模块的urlencode()进行编码
- result = parse.urlencode(query_string)
- #使用format函数格式化字符串,拼接url地址
- url = 'http://www.baidu.com/s?{}'.format(result)
- print(url)
输出结果,如下所示:
wd=%E7%88%AC%E8%99%AB
http://www.baidu.com/s?wd=%E7%88%AC%E8%99%AB
编码后的 URL 地址依然可以通过地网页址栏实现搜索功能。
除了使用 urlencode() 方法之外,也可以使用 quote(string) 方法实现编码,代码如下:
- from urllib import parse
- #注意url的书写格式,和 urlencode存在不同
- url = 'http://www.baidu.com/s?wd={}'
- word = input('请输入要搜索的内容:')
- #quote()只能对字符串进行编码
- query_string = parse.quote(word)
- print(url.format(query_string))
输出结果如下:
输入:请输入要搜索的内容:编程帮www.biancheng.net
输出:http://www.baidu.com/s?wd=%E7%BC%96%E7%A8%8B%E5%B8%AEwww.biancheng.net
注意:quote() 只能对字符串编码,而 urlencode() 可以直接对查询字符串字典进行编码。因此在定义 URL 时,需要注意两者之间的差异。方法如下:
- # urllib.parse
- urllib.parse.urlencode({'key':'value'}) #字典
- urllib.parse.quote(string) #字符串
2) 解码unquote(string)
解码是对编码后的 URL 进行还原的一种操作,示例代码如下:
- from urllib import parse
- string = '%E7%88%AC%E8%99%AB'
- result = parse.unquote(string)
- print(result)
输出结果:
爬虫
3) URL地址拼接方式
最后,给大家介绍三种拼接 URL 地址的方法。除了使用 format() 函数外,还可以使用字符串相加,以及字符串占位符,总结如下:
- # 1、字符串相加
- baseurl = 'http://www.baidu.com/s?'
- params='wd=%E7%88%AC%E8%99%AB'
- url = baseurl + params
- # 2、字符串格式化(占位符)
- params='wd=%E7%88%AC%E8%99%AB'
- url = 'http://www.baidu.com/s?%s'% params
- # 3、format()方法
- url = 'http://www.baidu.com/s?{}'
- params='wd=%E7%88%AC%E8%99%AB'
- url = url.format(params)
8爬取网页
本节讲解第一个 Python 爬虫实战案例:抓取您想要的网页,并将其保存至本地计算机。
首先我们对要编写的爬虫程序进行简单地分析,该程序可分为以下三个部分:
- 拼接 url 地址
- 发送请求
- 将照片保存至本地
明确逻辑后,我们就可以正式编写爬虫程序了。
导入所需模块
本节内容使用 urllib 库来编写爬虫,下面导入程序所用模块:
from urllib import request
from urllib import parse
拼接URL地址
定义 URL 变量,拼接 url 地址。代码如下所示:
- url = 'http://www.baidu.com/s?wd={}'
- #想要搜索的内容
- word = input('请输入搜索内容:')
- params = parse.quote(word)
- full_url = url.format(params)
向URL发送请求
发送请求主要分为以下几个步骤:
- 创建请求对象-Request
- 获取响应对象-urlopen
- 获取响应内容-read
代码如下所示:
- #重构请求头
- headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'}
- #创建请求对应
- req = request.Request(url=full_url,headers=headers)
- #获取响应对象
- res = request.urlopen(req)
- #获取响应内容
- html = res.read().decode("utf-8")
保存为本地文件
把爬取的照片保存至本地,此处需要使用 Python 编程的文件 IO 操作,代码如下:
- filename = word + '.html'
- with open(filename,'w', encoding='utf-8') as f:
- f.write(html)
完整程序如下所示:
- from urllib import request,parse
- # 1.拼url地址
- url = 'http://www.baidu.com/s?wd={}'
- word = input('请输入搜索内容:')
- params = parse.quote(word)
- full_url = url.format(params)
- # 2.发请求保存到本地
- headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'}
- req = request.Request(url=full_url,headers=headers)
- res = request.urlopen(req)
- html = res.read().decode('utf-8')
- # 3.保存文件至当前目录
- filename = word + '.html'
- with open(filename,'w',encoding='utf-8') as f:
- f.write(html)
尝试运行程序,并输入编程帮,确认搜索,然后您会在 Pycharm 当前的工作目录中找到“编程帮.html”文件。
函数式编程修改程序
Python 函数式编程可以让程序的思路更加清晰、易懂。接下来,使用函数编程的思想更改上面代码。
定义相应的函数,通过调用函数来执行爬虫程序。修改后的代码如下所示:
- from urllib import request
- from urllib import parse
- # 拼接URL地址
- def get_url(word):
- url = 'http://www.baidu.com/s?{}'
- #此处使用urlencode()进行编码
- params = parse.urlencode({'wd':word})
- url = url.format(params)
- return url
- # 发请求,保存本地文件
- def request_url(url,filename):
- headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'}
- # 请求对象 + 响应对象 + 提取内容
- req = request.Request(url=url,headers=headers)
- res = request.urlopen(req)
- html = res.read().decode('utf-8')
- # 保存文件至本地
- with open(filename,'w',encoding='utf-8') as f:
- f.write(html)
- # 主程序入口
- if __name__ == '__main__':
- word = input('请输入搜索内容:')
- url = get_url(word)
- filename = word + '.html'
- request_url(url,filename)
除了使用函数式编程外,您也可以使用面向对象的编程方法(本教程主要以该方法),在后续内容中会做相应介绍。
9实战
本节继续讲解 Python 爬虫实战案例:抓取百度贴吧(https://tieba.baidu.com/)页面,比如 Python爬虫吧、编程吧,只抓取贴吧的前 5 个页面即可。本节我们将使用面向对象的编程方法来编写程序。
判断页面类型
通过简单的分析可以得知,待抓取的百度贴吧页面属于静态网页,分析方法非常简单:打开百度贴吧,搜索“Python爬虫”,在出现的页面中复制任意一段信息,比如“爬虫需要 http 代理的原因”,然后点击右键选择查看源码,并使用 Ctrl+F 快捷键在源码页面搜索刚刚复制的数据,如下所示:
图1:静态网页分析判断(点击看高清图)
{kind=link}
由上图可知,页面内的所有信息都包含在源码页中,数据并不需要从数据库另行加载,因此该页面属于静态页面。
寻找URL变化规律
接下来寻找要爬取页面的 URL 规律,搜索“Python爬虫”后,此时贴吧第一页的的 url 如下所示:
https://tieba.baidu.com/f?ie=utf-8&kw=python爬虫&fr=search
点击第二页,其 url 信息如下:
https://tieba.baidu.com/f?kw=python爬虫&ie=utf-8&pn=50
点击第三页,url 信息如下:
https://tieba.baidu.com/f?kw=python爬虫&ie=utf-8&pn=100
重新点击第一页,url 信息如下:
https://tieba.baidu.com/f?kw=python爬虫&ie=utf-8&pn=0
如果还不确定,您可以继续多浏览几页。最后您发现 url 具有两个查询参数,分别是 kw 和 pn,并且 pn 参数具有规律性,如下所示:
第n页:pn=(n-1)*50
#参数params
pn=(page-1)*50
params={
'kw':name,
'pn':str(pn)
}
url 地址可以简写为:
https://tieba.baidu.com/f?kw=python爬虫&pn=450
编写爬虫程序
下面以类的形式编写爬虫程序,并在类下编写不同的功能函数,代码如下所示:
- from urllib import request,parse
- import time
- import random
- from ua_info import ua_list #使用自定义的ua池
- #定义一个爬虫类
- class TiebaSpider(object):
- #初始化url属性
- def __init__(self):
- self.url='http://tieba.baidu.com/f?{}'
- # 1.请求函数,得到页面,传统三步
- def get_html(self,url):
- req=request.Request(url=url,headers={'User-Agent':random.choice(ua_list)})
- res=request.urlopen(req)
- #windows会存在乱码问题,需要使用 gbk解码,并使用ignore忽略不能处理的字节
- #linux不会存在上述问题,可以直接使用decode('utf-8')解码
- html=res.read().decode("gbk","ignore")
- return html
- # 2.解析函数,此处代码暂时省略,还没介绍解析模块
- def parse_html(self):
- pass
- # 3.保存文件函数
- def save_html(self,filename,html):
- with open(filename,'w') as f:
- f.write(html)
- # 4.入口函数
- def run(self):
- name=input('输入贴吧名:')
- begin=int(input('输入起始页:'))
- stop=int(input('输入终止页:'))
- # +1 操作保证能够取到整数
- for page in range(begin,stop+1):
- pn=(page-1)*50
- params={
- 'kw':name,
- 'pn':str(pn)
- }
- #拼接URL地址
- params=parse.urlencode(params)
- url=self.url.format(params)
- #发请求
- html=self.get_html(url)
- #定义路径
- filename='{}-{}页.html'.format(name,page)
- self.save_html(filename,html)
- #提示
- print('第%d页抓取成功'%page)
- #每爬取一个页面随机休眠1-2秒钟的时间
- time.sleep(random.randint(1,2))
- #以脚本的形式启动爬虫
- if __name__=='__main__':
- start=time.time()
- spider=TiebaSpider() #实例化一个对象spider
- spider.run() #调用入口函数
- end=time.time()
- #查看程序执行时间
- print('执行时间:%.2f'%(end-start)) #爬虫执行时间
程序执行后,爬取的文件将会保存至 Pycharm 当前工作目录,输出结果:
输入贴吧名:python爬虫
输入起始页:1
输入终止页:2
第1页抓取成功
第2页抓取成功
执行时间:12.25
以面向对象方法编写爬虫程序时,思路简单、逻辑清楚,非常容易理解,上述代码主要包含了四个功能函数,它们分别负责了不同的功能,总结如下:
1) 请求函数
请求函数最终的结果是返回一个 HTML 对象,以方便后续的函数调用它。
2) 解析函数
解析函数用来解析 HTML 页面,常用的解析模块有正则解析模块、bs4 解析模块。通过分析页面,提取出所需的数据,在后续内容会做详细介绍。
3) 保存数据函数
该函数负责将抓取下来的数据保至数据库中,比如 MySQL、MongoDB 等,或者将其保存为文件格式,比如 csv、txt、excel 等。
4) 入口函数
入口函数充当整个爬虫程序的桥梁,通过调用不同的功能函数,实现数据的最终抓取。入口函数的主要任务是组织数据,比如要搜索的贴吧名、编码 url 参数、拼接 url 地址、定义文件保存路径。
爬虫程序结构
用面向对象的方法编写爬虫程序时,逻辑结构较为固定,总结如下:
- # 程序结构
- class xxxSpider(object):
- def __init__(self):
- # 定义常用变量,比如url或计数变量等
- def get_html(self):
- # 获取响应内容函数,使用随机User-Agent
- def parse_html(self):
- # 使用正则表达式来解析页面,提取数据
- def write_html(self):
- # 将提取的数据按要求保存,csv、MySQL数据库等
- def run(self):
- # 主函数,用来控制整体逻辑
- if __name__ == '__main__':
- # 程序开始运行时间
- spider = xxxSpider()
- spider.run()
注意:掌握以上编程逻辑有助于您后续的学习。
爬虫程序随机休眠
在入口函数代码中,包含了以下代码:
- #每爬取一个页面随机休眠1-2秒钟的时间
- time.sleep(random.randint(1,2))
爬虫程序访问网站会非常快,这与正常人类的点击行为非常不符。因此,通过随机休眠可以使爬虫程序模仿成人类的样子点击网站,从而让网站不易察觉是爬虫访问网站,但这样做的代价就是影响程序的执行效率。
聚焦爬虫是一种执行效率较低的程序,提升其性能,是业界一直关注的问题,由此也诞生了效率较高的 Python 爬虫框架 Scrapy。
python之爬虫一的更多相关文章
- Python简单爬虫入门三
我们继续研究BeautifulSoup分类打印输出 Python简单爬虫入门一 Python简单爬虫入门二 前两部主要讲述我们如何用BeautifulSoup怎去抓取网页信息以及获取相应的图片标题等信 ...
- Ubuntu下配置python完成爬虫任务(笔记一)
Ubuntu下配置python完成爬虫任务(笔记一) 目标: 作为一个.NET汪,是时候去学习一下Linux下的操作了.为此选择了python来边学习Linux,边学python,熟能生巧嘛. 前期目 ...
- Python简单爬虫入门二
接着上一次爬虫我们继续研究BeautifulSoup Python简单爬虫入门一 上一次我们爬虫我们已经成功的爬下了网页的源代码,那么这一次我们将继续来写怎么抓去具体想要的元素 首先回顾以下我们Bea ...
- [Python] 网络爬虫和正则表达式学习总结
以前在学校做科研都是直接利用网上共享的一些数据,就像我们经常说的dataset.beachmark等等.但是,对于实际的工业需求来说,爬取网络的数据是必须的并且是首要的.最近在国内一家互联网公司实习, ...
- python简易爬虫来实现自动图片下载
菜鸟新人刚刚入住博客园,先发个之前写的简易爬虫的实现吧,水平有限请轻喷. 估计利用python实现爬虫的程序网上已经有太多了,不过新人用来练手学习python确实是个不错的选择.本人借鉴网上的部分实现 ...
- GJM : Python简单爬虫入门(二) [转载]
感谢您的阅读.喜欢的.有用的就请大哥大嫂们高抬贵手"推荐一下"吧!你的精神支持是博主强大的写作动力以及转载收藏动力.欢迎转载! 版权声明:本文原创发表于 [请点击连接前往] ,未经 ...
- Python分布式爬虫原理
转载 permike 原文 Python分布式爬虫原理 首先,我们先来看看,如果是人正常的行为,是如何获取网页内容的. (1)打开浏览器,输入URL,打开源网页 (2)选取我们想要的内容,包括标题,作 ...
- Python 网页爬虫 & 文本处理 & 科学计算 & 机器学习 & 数据挖掘兵器谱(转)
原文:http://www.52nlp.cn/python-网页爬虫-文本处理-科学计算-机器学习-数据挖掘 曾经因为NLTK的缘故开始学习Python,之后渐渐成为我工作中的第一辅助脚本语言,虽然开 ...
- 关于Python网络爬虫实战笔记③
Python网络爬虫实战笔记③如何下载韩寒博客文章 Python网络爬虫实战笔记③如何下载韩寒博客文章 target:下载全部的文章 1. 博客列表页面规则 也就是, http://blog.sina ...
- 关于Python网络爬虫实战笔记①
python网络爬虫项目实战笔记①如何下载韩寒的博客文章 python网络爬虫项目实战笔记①如何下载韩寒的博客文章 1. 打开韩寒博客列表页面 http://blog.sina.com.cn/s/ar ...
随机推荐
- 监控室NTP/GPS同步时钟解决方案
深圳市立显电子有限公司,专业LED时钟生产厂家!--------[点击进入] 车站.机场.学校等场所监控室布置要求: 1.宜选择建筑物中环境噪声较小的声场所.如车站票务中心后台.机场保安值班室. ...
- MMDetection中模型的Checkpoints下载
mmdetection中的模型checkpoints是需要自己手动下载的,下载步骤如下: 打开mmdetection, 进入configs目录,可以看到这里面有很多以目标检测模型命名的文件夹,选择你想 ...
- Linux(2)
虚拟机关键配置名词解释 远程链接工具 linux准则 远程链接工具快捷键 系统相关命令 文件相关命令 linux目录结构 虚拟机关键配置名词解释 # 虚拟网络编辑器说明 桥接模式 # 可以访问互联网 ...
- OO_Lab2总结博客
OO_Lab2 一.单元内容 本单元内容为规格化设计,即通过参考已经完成的JML描述实现一个社交网络相关功能. 本单元整体来说难度不大,但是却是我最惨的一次作业,所以本博客可能会主要谈一谈测试中的一些 ...
- squad经验总结
啊美丽卡:M1A2 - TANKM2A3 - BLDL/M2A3M1126 - SCKMATV - RWS(电摇),ZCC(手摇)MATV(TOW) - TOW车M989 - 补给卡/运兵卡 俄军 8 ...
- CGAL的demo运行的步骤
首先使用CMake,找到demo的源文件目录,并且指定生成文件目录: 点击configur,done 点击generate,done 找到build目录中的.sln 文件,打开 ALL_BUILD 生 ...
- cmake使用boost静态库,错误提示 Could NOT find Boost (missing: Boost_INCLUDE_DIR) (Required is at least version "1.48")
使用的是Cmake-gui 编译. 问题出在C盘路径下找不到 Boost ,是否需要把boost的路径添加到系统Path 中? 任然不能解决. 更改源码: 找到下面这几行代码(你可以搜索) messa ...
- jmeter学习-性能指标、jmeter初识
一:性能测试的指标 1. 并发/并发数/并发用户数 狭义的并发:同一时间做相同的一件事 广义的并发:同一时间做不同事情,混合场景,对服务器来说的并发 性能测试,先做简单的狭义并发,在做广义并发:先做单 ...
- 微信小程序按下去的样式
微信小程序设置 hover-class,实现点击态效果 目前支持 hover-class 属性的组件有三个:view.button.navigator. 不支持 hover-class 属性的组件,同 ...
- USB 驱动框架分析
这里先说一些概念性的东西,了解一下USB 一.关于usb设备 都见过很多,用过很多了,每当我们插上一个usb设备到pc的时 右下角就会弹出一个提示信息,提示"发现xxx"设备,再接 ...