Hadoop学习之常用输入输出格式总结
目的
总结一下常用的输入输出格式。
输入格式
Hadoop可以处理很多不同种类的输入格式,从一般的文本文件到数据库。
开局一张UML类图,涵盖常用InputFormat类的继承关系与各自的重要方法(已省略部分重载)。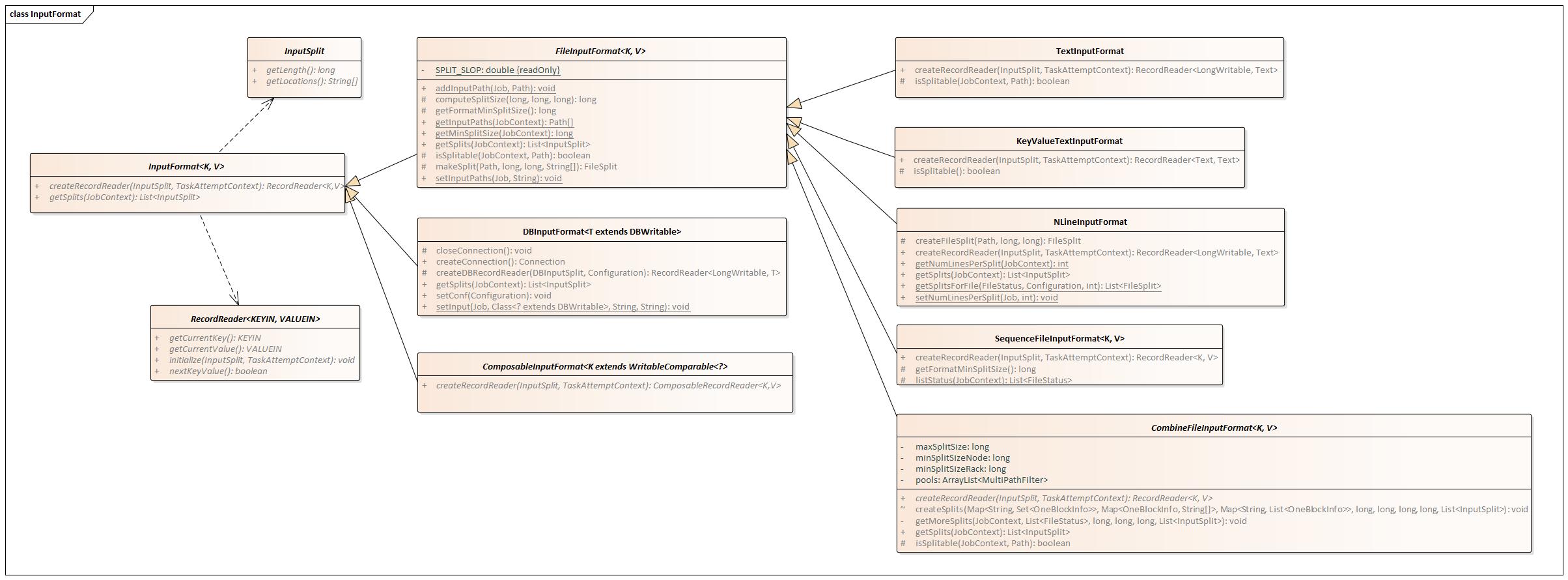
DBInputFormat
- DBInputFormat,用来处理数据库输入的一种输入格式。KEY为LongWritable格式,表示包含的记录数;VALUE为DBWritable格式,需要根据自己的表结构继承、实现DBWritable。
- 使用需通过其setInput方法指定输入类、表名、字段集合、查询条件集合和排序条件,或者使用setInput的另一个重载方法直接指定输入类、SQL查询语句、统计数据条数的SQL查询语句。
- 其createDBRecordReader方法会根据Configuration中的数据库类型,返回对应的RecordReader,如OracleDBRecordReader、MySQLDBRecordReader。
- 其分片逻辑为,若已指定mapper数量,则按指定的mapper数等分查询出的数据量(最后一片统收余出的部分),若未指定mapper数,则默认一个分片。
- 由其派生出的DataDrivenDBInputFormat,顾名思义是一种数据驱动的数据库输入格式,与DBInputFormat的区别在于,DataDrivenDBInputFormat能从数据的角度去做分片控制,指定某一列作为边界参考(setBoundingQuery),按mapper数划分分片。
FileInputFormat
- FileInputFormat,所有文件类输入格式的父类。实现了较为通用的方法,如getSplits、isSplitable、listStatus。
- 默认文件可切分
- 默认忽略输入目录中的隐藏文件(文件名以'_'或‘.’开头的文件)
- 默认分片方式为按块分片,并算上1.1的分片溢出值。
TextInputFormat
- TextInputFormat,FileInputFormat的<LongWritable, Text>子类,以当前行偏移字节数为key,当前行内容为value。
- 重载了isSplitable方法,判断方法为通过输入文件后缀判断当前文件所使用的压缩方式是否支持切分。
- 实现了自己的createRecordReader方法,具体逻辑在LineRecordReader。
KeyValueTextInputFormat
- KeyValueTextInputFormat,FileInputFormat的<Text, Text>子类,以当前行内容的分隔符左侧内容为key,当前行内容的分隔符右侧内容为value。
- 可通过属性mapreduce.input.keyvaluelinerecordreader.key.value.separator自定义分隔符,默认分隔符为制表符(\t)。
- 如果该行不存在定义的制表符,则Key为整行内容,Value为空。
- 重载了isSplitable方法,判断方法为通过输入文件后缀判断当前文件所使用的压缩方式是否支持切分。
- 实现了自己的createRecordReader方法,具体逻辑在SplittableCompressionCodec。
NLineInputFormat
- NLineInputFormat, FileInputFormat的<LongWritable, Text>子类,以当前行偏移字节数为key,当前行内容为value。
- 分片方式为,逐文件逐行读取N行作为一个输入分片(有大输入量的情况下,这一步岂不是效率极低?!)
- 行数N由属性mapreduce.input.lineinputformat.linespermap配置或调用其setNumLinesPerSplit方法设置。
- 实现了自己的createRecordReader方法,具体逻辑在LineRecordReader。
SequenceFileInputFormat
- SequenceFileInputFormat,FileInputFormat的针对SequenceFile的子类。
- 重载了getFormatMinSplitSize方法,返回100k。
- 重载了listStatus方法,实现查找SequenceFile中的目录(MapFile)。
- 有两个典型的子类:SequenceFileAsTextInputFormat和SequenceFileAsBinaryInputFormat。前者类似与本类,是其父类的<Text, Text>形式;后者是其父类的<BytesWritable,BytesWritable>形式。
CombineFileInputFormat
- CombineFileInputFormat,FileInputFormat的虚子类,能将多个文件合并到一个输入分片,常用来处理输入为大量小文件的情况。已有的实现子类有CombineTextInputFormat和CombineSequenceFileInputFormat,分别用来处理普通文本文件和SequenceFile的输入。
- 分片有关的三个变量maxSplitSize, minSplitSizeNode, minSplitSizeRack, 须满足关系maxSplitSize >= minSplitSizeRack >= minSplitSizeNode。
- 分片逻辑为:先按已设置的路径过滤器,分别过滤出各自对应的输入文件池,再对各自的输入文件池做分片。
- 分片原则为优先node-local>rack-local>internet,即同一分片内所有的块,优先是位于同一数据节点、其次位于同一机架、再次位于多个机架。
- 针对某一文件池分片具体做法为:1)将同一节点上的所有块汇总后,按maxSplitSize做切分,直至完美切分没有剩余,或最后剩余小于minSplitSizeNode的“节点尾巴”;2)按1)中的做法处理同一机架下所有节点后,汇总所有“节点尾巴”,继续按maxSplitSize切分,直至完美切分或剩余小于minSplitSizeRack的“机架尾巴”;3)按1)和2)中的做法处理完所有机架后,汇总所有“机架尾巴”,继续按maxSplitSize切分直至结束,不留尾巴。
输出格式
与输入格式类似,Hadoop中有分别与之对应的输出格式。常用输出格式类图如下所示: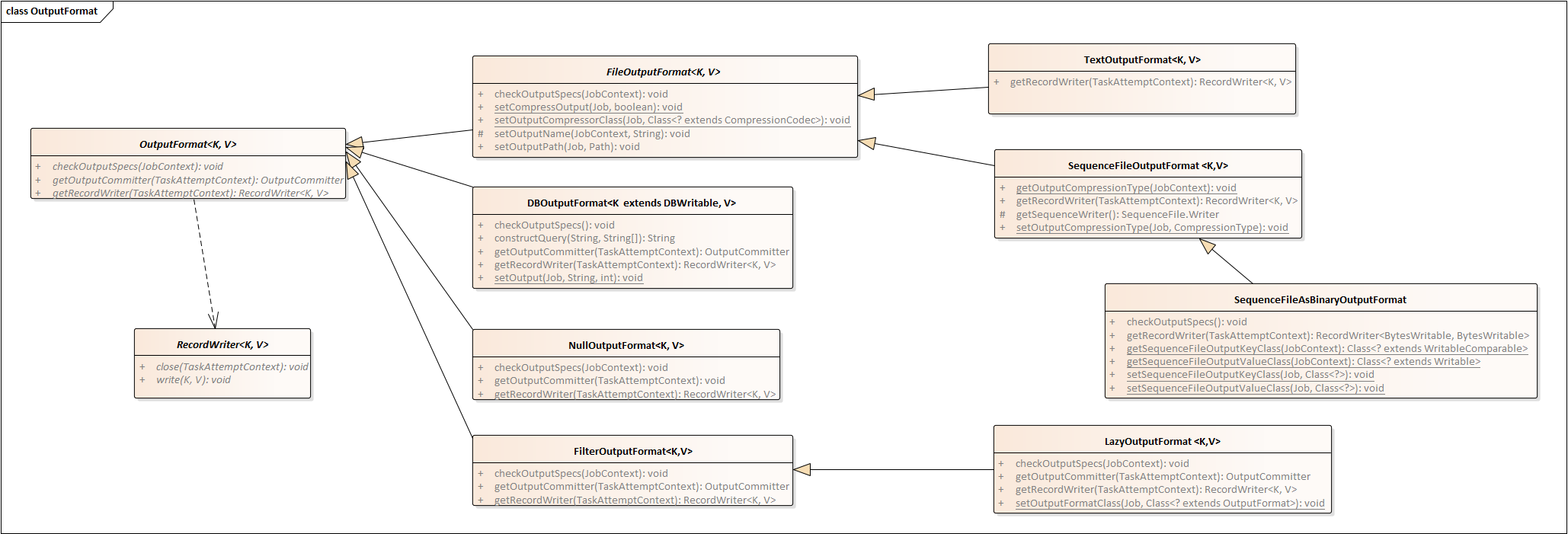
DBOutputFormat
用于将结果输出到数据库表中。可通过其静态方法setOutput设置输出的表名等信息。
NullOutputFormat
OutputFormat的空实现,即实现无任何输出。
LazyOutputFormat
懒惰输出格式,即只有真正产生输出的时候,才创建输出文件。
FileOutputFormat
文件型输出的虚父类,实现了设置/获取压缩格式、检查输出目录、设置/获取输出路径的方法。
TextOutputFormat
将输出写到普通文本文件的输出格式,它把每条记录写成(键\t值)组成的文本行。
SequenceFileOutputFormat
将输出写入顺序文件SequenceFile,其子类SequenceFileAsBinaryOutputFormat则专用于把键/值对作为二进制格式写入到SequenceFile容器中。
Hadoop学习之常用输入输出格式总结的更多相关文章
- Hadoop MapReduce常用输入输出格式
这里介绍MapReduce常用的几种输入输出格式. 三种常用的输入格式:TextInputFormat , SequenceFileInputFormat , KeyValueInputFormat ...
- 我的c++学习(4) C++输入输出格式的控制
默认进制:默认状态下,数据按十进制输入输出.如果要求按八进制或十六进制输入输出,在cin或cout中必须指明相应的数据形式,oct为八进制,hex为十六进制,dec为十进制. #include &qu ...
- Hadoop学习之常用命令
HADOOP基本操作命令 在这篇文章中,我们默认认为Hadoop环境已经由运维人员配置好直接可以使用. 假设Hadoop的安装目录HADOOP_HOME为/home/admin/hadoop. 启动与 ...
- SAS学习笔记3 输入输出格式(format、informat函数)
format函数:定义输出格式 informat函数:定义输入格式 proc format:定义输出格式 从外部读取文件 proc format过程步
- hdu 6297(常用的输出格式总结)
题目链接:https://cn.vjudge.net/problem/HDU-6297 题目介绍:一道关于输出格式规范问题 wrong answer代码: #include<iostream&g ...
- Hadoop(七):自定义输入输出格式
MR输入格式概述 数据输入格式 InputFormat. 用于描述MR作业的数据输入规范. 输入格式在MR框架中的作用: 文件进行分块(split),1个块就是1个Mapper任务. 从输入分块中将数 ...
- Hadoop学习笔记(7) ——高级编程
Hadoop学习笔记(7) ——高级编程 从前面的学习中,我们了解到了MapReduce整个过程需要经过以下几个步骤: 1.输入(input):将输入数据分成一个个split,并将split进一步拆成 ...
- [Hadoop] Hadoop学习历程 [持续更新中…]
1. Hadoop FS Shell Hadoop之所以可以实现分布式计算,主要的原因之一是因为其背后的分布式文件系统(HDFS).所以,对于Hadoop的文件操作需要有一套全新的shell指令来完成 ...
- Hadoop学习笔记(6) ——重新认识Hadoop
Hadoop学习笔记(6) ——重新认识Hadoop 之前,我们把hadoop从下载包部署到编写了helloworld,看到了结果.现是得开始稍微更深入地了解hadoop了. Hadoop包含了两大功 ...
随机推荐
- P4408 逃学的小孩 题解
题目描述 Chris家的电话铃响起了,里面传出了Chris的老师焦急的声音:"喂,是Chris的家长吗?你们的孩子又没来上课,不想参加考试了吗?"一听说要考试,Chris的父母就心 ...
- Flask——实现上传功能
1.实例 #!-*-coding=utf-8-*- # from flask import Flask # # app = Flask(__name__) # # # @app.route('/') ...
- vs dll lib 使用记录
今天把学习opengl的项目从一个电脑copy到另一个电脑时候,发生了glu.dll找不到,导致项目起不来的问题.后来网上查找发现, 虽然我使用了静态连接 mt/mtd 编译, 但是有可能lib中并没 ...
- 07 . Jenkins忘记root密码
重置Jenkins用户名密码 忘记用户名密码(如图)不管是忘记用户名密码还是误删jenkins目录下的users文件都可以使用下面的方式找回密码,我的版本是Jenkins 2.134 配置config ...
- 仅需5步,轻松升级K3s集群!
Rancher 2.4是Rancher目前最新的版本,在这一版本中你可以通过Rancher UI对K3s集群进行升级管理. K3s是一个轻量级Kubernetes发行版,借助它你可以几分钟之内设置你的 ...
- [Mybatis]Mybatis常用操作
Mybatis是目前国内比较流行的ORM框架,特点是可以写灵活的SQL语句,非常适合中小企业的面向数据库开发. 本文总结自己开发过程中常用的Mybatis操作. 一.插入操作 主键自增插入单条 < ...
- python 魔法方法总结
目录 一.__str__ 二.__repr__ 三.__format__ 四.__del__ 五.__dict__和__slots__ 六.__item__.__attr__系列 七.__init__ ...
- 消息队列-一篇读懂rabbitmq(生命周期,confirm模式,延迟队列,集群)
什么是消息队列? 就是生产者生产一条消息,发送到这个rabbitmq,消费者连接rabbitmq并且进行消费,生产者和消费者并需要知道对方是如何工作的,从而实现程序之间的解耦,异步和削峰,这也就是消息 ...
- GPO - General GPO Settings(1)
Prohibit access to Control Panel and PC settings Disable GPO for Administrators and /or User Groups ...
- Ethical Hacking - Overview
Hacking is gaining unauthorized access to anything. Preparation Setting up a lab and installing need ...