java中常见的六种线程池详解

- 之前我们介绍了线程池的四种拒绝策略,了解了线程池参数的含义,那么今天我们来聊聊
Java中常见的几种线程池,以及在jdk7加入的ForkJoin新型线程池 - 首先我们列出
Java中的六种线程池如下
| 线程池名称 | 描述 |
|---|---|
| FixedThreadPool | 核心线程数与最大线程数相同 |
| SingleThreadExecutor | 一个线程的线程池 |
| CachedThreadPool | 核心线程为0,最大线程数为Integer. MAX_VALUE |
| ScheduledThreadPool | 指定核心线程数的定时线程池 |
| SingleThreadScheduledExecutor | 单例的定时线程池 |
| ForkJoinPool | JDK 7 新加入的一种线程池 |
- 在了解集中线程池时我们先来熟悉一下主要几个类的关系,
ThreadPoolExecutor的类图,以及Executors的主要方法:
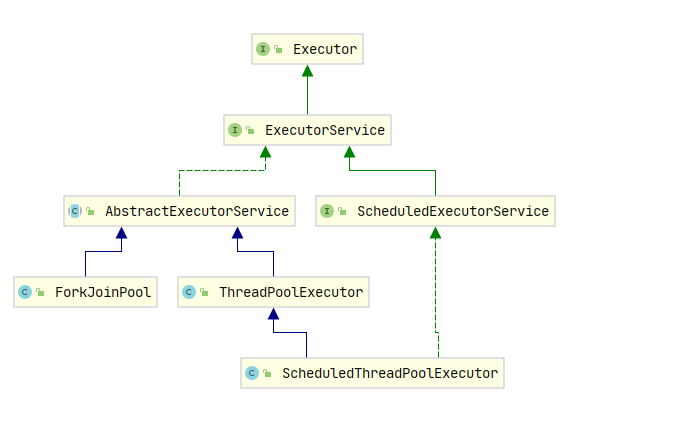
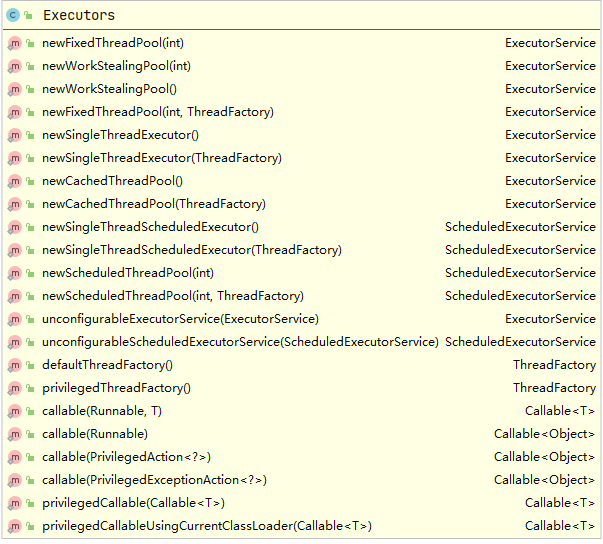
- 上面看到的类图,方便帮助下面的理解和查看,我们可以看到一个核心类
ExecutorService, 这是我们线程池都实现的基类,我们接下来说的都是它的实现类。
FixedThreadPool
FixedThreadPool线程池的特点是它的核心线程数和最大线程数一样,我们可以看它的实现代码在Executors#newFixedThreadPool(int)中,如下:
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
我们可以看到方法内创建线程调用的实际是
ThreadPoolExecutor类,这是线程池的核心执行器,传入的nThread参数作为核心线程数和最大线程数传入,队列采用了一个链表结构的有界队列。
- 这种线程池我们可以看作是固定线程数的线程池,它只有在开始初始化的时候线程数会从0开始创建,但是创建好后就不再销毁,而是全部作为常驻线程池,这里如果对线程池参数不理解的可以看之前文章 《解释线程池各个参数的含义》。
- 对于这种线程池他的第三个和第四个参数是没意义,它们是空闲线程存活时间,这里都是常驻不存在销毁,当线程处理不了时会加入到阻塞队列,这是一个链表结构的有界阻塞队列,最大长度是Integer. MAX_VALUE
SingleThreadExecutor
SingleThreadExecutor线程的特点是它的核心线程数和最大线程数均为1,我们也可以将其任务是一个单例线程池,它的实现代码是Executors#newSingleThreadExcutor(), 如下:
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory) {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory));
}
- 上述代码中我们发现它有一个重载函数,传入了一个
ThreadFactory的参数,一般在我们开发中会传入我们自定义的线程创建工厂,如果不传入则会调用默认的线程工厂 - 我们可以看到它与
FixedThreadPool线程池的区别仅仅是核心线程数和最大线程数改为了1,也就是说不管任务多少,它只会有唯一的一个线程去执行 - 如果在执行过程中发生异常等导致线程销毁,线程池也会重新创建一个线程来执行后续的任务
- 这种线程池非常适合所有任务都需要按被提交的顺序来执行的场景,是个单线程的串行。
CachedThreadPool
cachedThreadPool线程池的特点是它的常驻核心线程数为0,正如其名字一样,它所有的县城都是临时的创建,关于它的实现在Executors#newCachedThreadPool()中,代码如下:
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory) {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>(),
threadFactory);
}
- 从上述代码中我们可以看到
CachedThreadPool线程池中,最大线程数为Integer.MAX_VALUE, 意味着他的线程数几乎可以无限增加。 - 因为创建的线程都是临时线程,所以他们都会被销毁,这里空闲 线程销毁时间是60秒,也就是说当线程在60秒内没有任务执行则销毁
- 这里我们需要注意点,它使用了
SynchronousQueue的一个阻塞队列来存储任务,这个队列是无法存储的,因为他的容量为0,它只负责对任务的传递和中转,效率会更高,因为核心线程都为0,这个队列如果存储任务不存在意义。
ScheduledThreadPool
ScheduledThreadPool线程池是支持定时或者周期性执行任务,他的创建代码Executors.newSchedsuledThreadPool(int)中,如下所示:
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
public static ScheduledExecutorService newScheduledThreadPool(
int corePoolSize, ThreadFactory threadFactory) {
return new ScheduledThreadPoolExecutor(corePoolSize, threadFactory);
}
- 我们发现这里调用了
ScheduledThreadPoolExecutor这个类的构造函数,进一步查看发现ScheduledThreadPoolExecutor类是一个继承了ThreadPoolExecutor的,同时实现了ScheduledExecutorService接口,我们看到它的几个构造函数都是调用父类ThreadPoolExecutor的构造函数
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}
public ScheduledThreadPoolExecutor(int corePoolSize,
ThreadFactory threadFactory) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue(), threadFactory);
}
public ScheduledThreadPoolExecutor(int corePoolSize,
RejectedExecutionHandler handler) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue(), handler);
}
public ScheduledThreadPoolExecutor(int corePoolSize,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue(), threadFactory, handler);
}
- 从上面代码我们可以看到和其他线程池创建并没有差异,只是这里的任务队列是
DelayedWorkQueue关于阻塞丢列我们下篇文章专门说,这里我们先创建一个周期性的线程池来看一下
public static void main(String[] args) {
ScheduledExecutorService service = Executors.newScheduledThreadPool(5);
// 1. 延迟一定时间执行一次
service.schedule(() ->{
System.out.println("schedule ==> 云栖简码-i-code.online");
},2, TimeUnit.SECONDS);
// 2. 按照固定频率周期执行
service.scheduleAtFixedRate(() ->{
System.out.println("scheduleAtFixedRate ==> 云栖简码-i-code.online");
},2,3,TimeUnit.SECONDS);
//3. 按照固定频率周期执行
service.scheduleWithFixedDelay(() -> {
System.out.println("scheduleWithFixedDelay ==> 云栖简码-i-code.online");
},2,5,TimeUnit.SECONDS);
}
- 上面代码是我们简单创建了
newScheduledThreadPool,同时演示了里面的三个核心方法,首先看执行的结果:

- 首先我们看第一个方法
schedule, 它有三个参数,第一个参数是线程任务,第二个delay表示任务执行延迟时长,第三个unit表示延迟时间的单位,如上面代码所示就是延迟两秒后执行任务
public ScheduledFuture<?> schedule(Runnable command,
long delay, TimeUnit unit);
- 第二个方法是
scheduleAtFixedRate如下, 它有四个参数,command参数表示执行的线程任务 ,initialDelay参数表示第一次执行的延迟时间,period参数表示第一次执行之后按照多久一次的频率来执行,最后一个参数是时间单位。如上面案例代码所示,表示两秒后执行第一次,之后按每隔三秒执行一次
public ScheduledFuture<?> scheduleAtFixedRate(Runnable command,
long initialDelay,
long period,
TimeUnit unit);
- 第三个方法是
scheduleWithFixedDelay如下,它与上面方法是非常类似的,也是周期性定时执行, 参数含义和上面方法一致。这个方法和scheduleAtFixedRate的区别主要在于时间的起点计时不同
public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command,
long initialDelay,
long delay,
TimeUnit unit);
scheduleAtFixedRate是以任务开始的时间为时间起点来计时,时间到就执行第二次任务,与任务执行所花费的时间无关;而scheduleWithFixedDelay是以任务执行结束的时间点作为计时的开始。如下所示
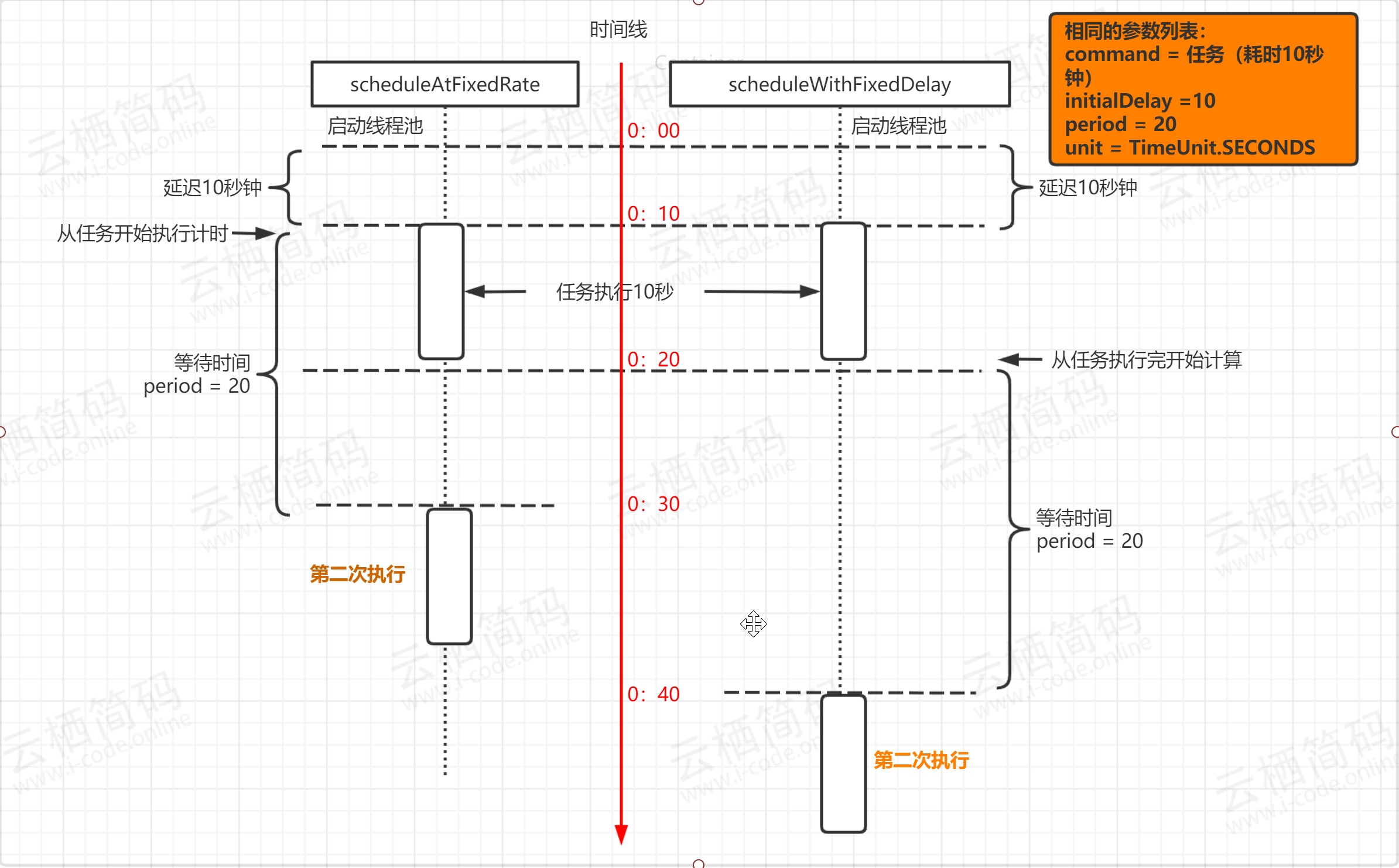
SingleThreadScheduledExecutor
- 它实际和
ScheduledThreadPool线程池非常相似,它只是ScheduledThreadPool的一个特例,内部只有一个线程,它只是将ScheduledThreadPool的核心线程数设置为了 1。如源码所示:
public static ScheduledExecutorService newSingleThreadScheduledExecutor() {
return new DelegatedScheduledExecutorService
(new ScheduledThreadPoolExecutor(1));
}
- 上面我们介绍了五种常见的线程池,对于这些线程池我们可以从核心线程数、最大线程数、存活时间三个维度进行一个简单的对比,有利于我们加深对这几种线程池的记忆。
| FixedThreadPool | SingleThreadExecutor | CachedThreadPool | ScheduledThreadPool | SingleThreadScheduledExecutor | |
|---|---|---|---|---|---|
| corePoolSize | 构造函数传入 | 1 | 0 | 构造函数传入 | 1 |
| maxPoolSize | 同corePoolSize | 1 | Integer. MAX_VALUE | Integer. MAX_VALUE | Integer. MAX_VALUE |
| keepAliveTime | 0 | 0 | 60 | 0 | 0 |
ForkJoinPool
ForkJoinPool这是一个在JDK7引入的新新线程池,它的主要特点是可以充分利用多核CPU, 可以把一个任务拆分为多个子任务,这些子任务放在不同的处理器上并行执行,当这些子任务执行结束后再把这些结果合并起来,这是一种分治思想。ForkJoinPool也正如它的名字一样,第一步进行Fork拆分,第二步进行Join合并,我们先来看一下它的类图结构
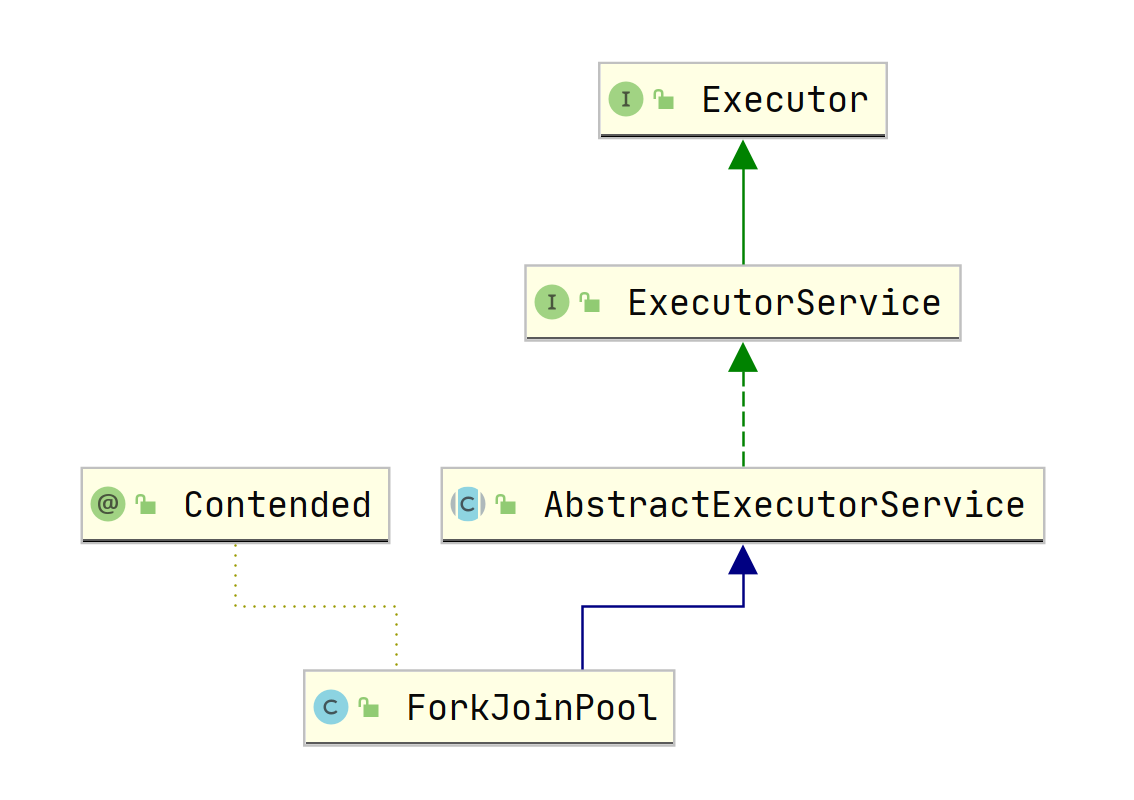
ForkJoinPool的使用也是通过调用submit(ForkJoinTask<T> task)或invoke(ForkJoinTask<T> task)方法来执行指定任务了。其中任务的类型是ForkJoinTask类,它代表的是一个可以合并的子任务,他本身是一个抽象类,同时还有两个常用的抽象子类RecursiveAction和RecursiveTask,其中RecursiveTask表示的是有返回值类型的任务,而RecursiveAction则表示无返回值的任务。下面是它们的类图:

- 下面我们通过一个简单的代码先来看一下如何使用
ForkJoinPool线程池
/**
* @url: i-code.online
* @author: AnonyStar
* @time: 2020/11/2 10:01
*/
public class ForkJoinApp1 {
/**
目标: 打印0-200以内的数字,进行分段每个间隔为10以上,测试forkjoin
*/
public static void main(String[] args) {
// 创建线程池,
ForkJoinPool joinPool = new ForkJoinPool();
// 创建根任务
SubTask subTask = new SubTask(0,200);
// 提交任务
joinPool.submit(subTask);
//让线程阻塞等待所有任务完成 在进行关闭
try {
joinPool.awaitTermination(2, TimeUnit.SECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
}
joinPool.shutdown();
}
}
class SubTask extends RecursiveAction {
int startNum;
int endNum;
public SubTask(int startNum,int endNum){
super();
this.startNum = startNum;
this.endNum = endNum;
}
@Override
protected void compute() {
if (endNum - startNum < 10){
// 如果分裂的两者差值小于10 则不再继续,直接打印
System.out.println(Thread.currentThread().getName()+": [startNum:"+startNum+",endNum:"+endNum+"]");
}else {
// 取中间值
int middle = (startNum + endNum) / 2;
//创建两个子任务,以递归思想,
SubTask subTask = new SubTask(startNum,middle);
SubTask subTask1 = new SubTask(middle,endNum);
//执行任务, fork() 表示异步的开始执行
subTask.fork();
subTask1.fork();
}
}
}
结果:

- 从上面的案例我们可以看到我们,创建了很多个线程执行,因为我测试的电脑是12线程的,所以这里实际是创建了12个线程,也侧面说明了充分调用了每个处理的线程处理能力
- 上面案例其实我们发现很熟悉的味道,那就是以前接触过的递归思想,将上面的案例图像化如下,更直观的看到,
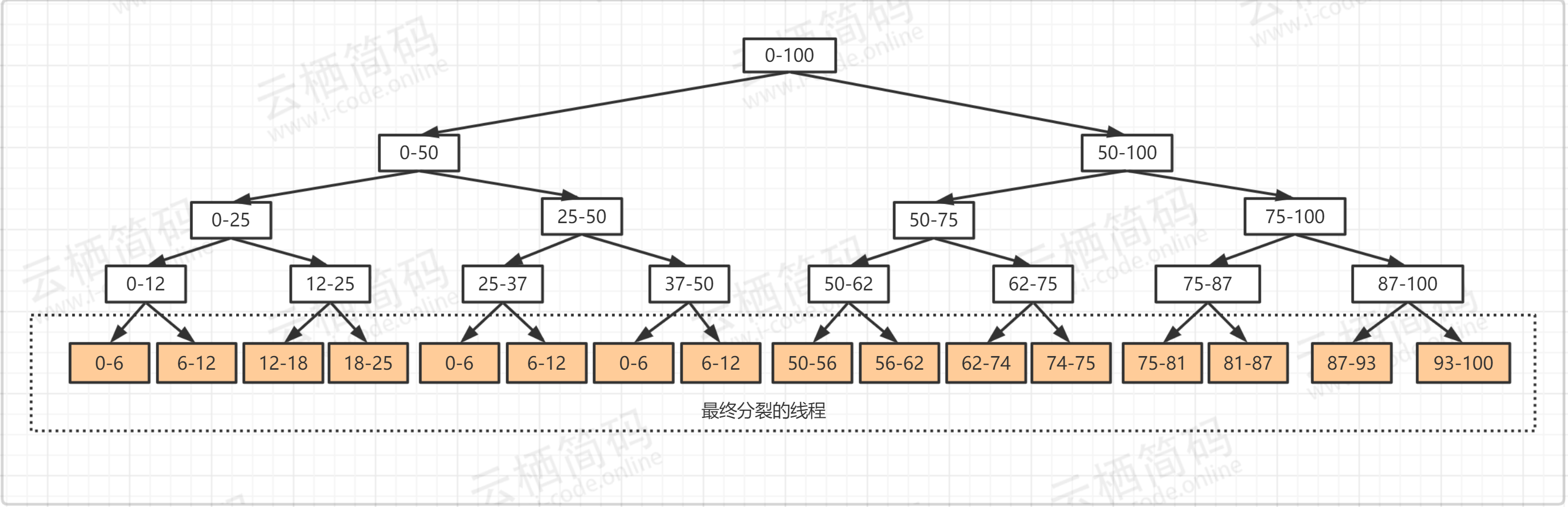
- 上面的例子是无返回值的案例,下面我们来看一个典型的有返回值的案例,相信大家都听过及很熟悉斐波那契数列,这个数列有个特点就是最后一项的结果等于前两项的和,如:
0,1,1,2,3,5...f(n-2)+f(n-1), 即第0项为0 ,第一项为1,则第二项为0+1=1,以此类推。我们最初的解决方法就是使用递归来解决,如下计算第n项的数值:
private int num(int num){
if (num <= 1){
return num;
}
num = num(num-1) + num(num -2);
return num;
}
- 从上面简单代码中可以看到,当
n<=1时返回n, 如果n>1则计算前一项的值f1,在计算前两项的值f2, 再将两者相加得到结果,这就是典型的递归问题,也是对应我们的ForkJoin的工作模式,如下所示,根节点产生子任务,子任务再次衍生出子子任务,到最后在进行整合汇聚,得到结果。
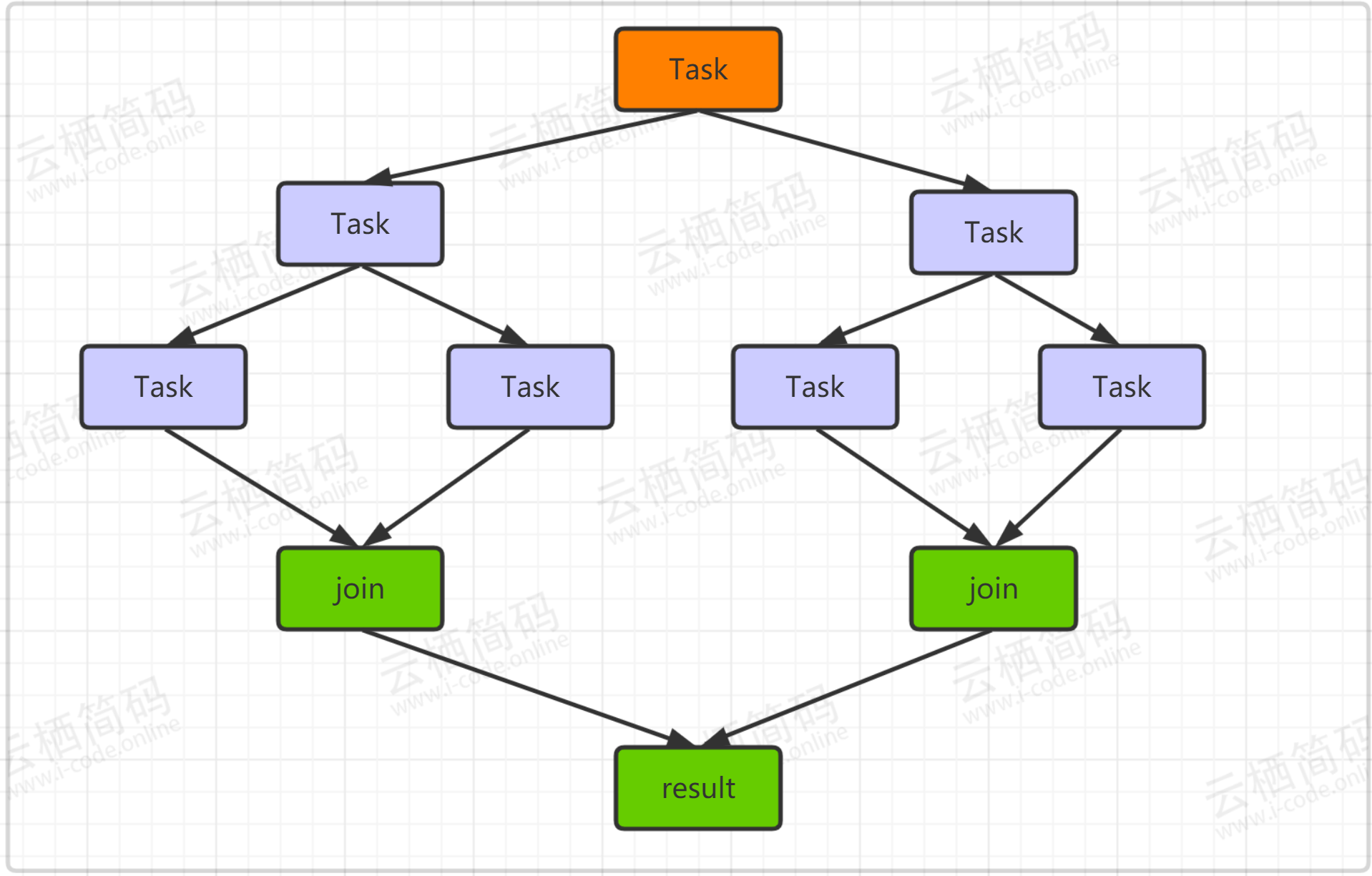
- 我们通过
ForkJoinPool来实现斐波那契数列的计算,如下展示:
/**
* @url: i-code.online
* @author: AnonyStar
* @time: 2020/11/2 10:01
*/
public class ForkJoinApp3 {
public static void main(String[] args) throws ExecutionException, InterruptedException {
ForkJoinPool pool = new ForkJoinPool();
//计算第二是项的数值
final ForkJoinTask<Integer> submit = pool.submit(new Fibonacci(20));
// 获取结果,这里获取的就是异步任务的最终结果
System.out.println(submit.get());
}
}
class Fibonacci extends RecursiveTask<Integer>{
int num;
public Fibonacci(int num){
this.num = num;
}
@Override
protected Integer compute() {
if (num <= 1) return num;
//创建子任务
Fibonacci subTask1 = new Fibonacci(num - 1);
Fibonacci subTask2 = new Fibonacci(num - 2);
// 执行子任务
subTask1.fork();
subTask2.fork();
//获取前两项的结果来计算和
return subTask1.join()+subTask2.join();
}
}
- 通过
ForkJoinPool可以极大的发挥多核处理器的优势,尤其非常适合用于递归的场景,例如树的遍历、最优路径搜索等场景。 - 上面说的是
ForkJoinPool的使用上的,下面我们来说一下其内部的构造,对于我们前面说的几种线程池来说,它们都是里面只有一个队列,所有的线程共享一个。但是在ForkJoinPool中,其内部有一个共享的任务队列,除此之外每个线程都有一个对应的双端队列Deque, 当一个线程中任务被Fork分裂了,那么分裂出来的子任务就会放入到对应的线程自己的Deque中,而不是放入公共队列。这样对于每个线程来说成本会降低很多,可以直接从自己线程的队列中获取任务而不需要去公共队列中争夺,有效的减少了线程间的资源竞争和切换。

- 有一种情况,当线程有多个如
t1,t2,t3...,在某一段时间线程t1的任务特别繁重,分裂了数十个子任务,但是线程t0此时却无事可做,它自己的deque队列为空,这时为了提高效率,t0就会想办法帮助t1执行任务,这就是“work-stealing”的含义。 - 双端队列
deque中,线程t1获取任务的逻辑是后进先出,也就是LIFO(Last In Frist Out),而线程t0在“steal”偷线程t1的deque中的任务的逻辑是先进先出,也就是FIFO(Fast In Frist Out),如图所示,图中很好的描述了两个线程使用双端队列分别获取任务的情景。你可以看到,使用 “work-stealing” 算法和双端队列很好地平衡了各线程的负载。

本文由AnonyStar 发布,可转载但需声明原文出处。
欢迎关注微信公账号 :云栖简码 获取更多优质文章
更多文章关注笔者博客 :云栖简码 i-code.online
java中常见的六种线程池详解的更多相关文章
- java中的String类常量池详解
test1: package StringTest; public class test1 { /** * @param args */ public static void main(String[ ...
- Java线程池详解(二)
一.前言 在总结了线程池的一些原理及实现细节之后,产出了一篇文章:Java线程池详解(一),后面的(一)是在本文出现之后加上的,而本文就成了(二).因为在写完第一篇关于java线程池的文章之后,越发觉 ...
- 三、VIP课程:并发编程专题->01-并发编程之Executor线程池详解
01-并发编程之Executor线程池详解 线程:什么是线程&多线程 线程:线程是进程的一个实体,是 CPU 调度和分派的基本单位,它是比进程更小的能独立运行的基本单位.线程自己基本上不拥有系 ...
- Java中堆内存和栈内存详解2
Java中堆内存和栈内存详解 Java把内存分成两种,一种叫做栈内存,一种叫做堆内存 在函数中定义的一些基本类型的变量和对象的引用变量都是在函数的栈内存中分配.当在一段代码块中定义一个变量时,ja ...
- nginx源码分析线程池详解
nginx源码分析线程池详解 一.前言 nginx是采用多进程模型,master和worker之间主要通过pipe管道的方式进行通信,多进程的优势就在于各个进程互不影响.但是经常会有人问道,n ...
- Java中的equals和hashCode方法详解
Java中的equals和hashCode方法详解 转自 https://www.cnblogs.com/crazylqy/category/655181.html 参考:http://blog.c ...
- java中List的用法和实例详解
java中List的用法和实例详解 List的用法List包括List接口以及List接口的所有实现类.因为List接口实现了Collection接口,所以List接口拥有Collection接口提供 ...
- 转:Java中的equals和hashCode方法详解
转自:Java中的equals和hashCode方法详解 Java中的equals方法和hashCode方法是Object中的,所以每个对象都是有这两个方法的,有时候我们需要实现特定需求,可能要重写这 ...
- Java线程池详解及实例
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明.本文链接:https://blog.csdn.net/aa1215018028/article/ ...
随机推荐
- 1、了解JVM
1.JVM.JRE.JDK JVM:是可以将要运行的程序编译成机器语言并去执行的一个平台,具有跨语言.跨平台的特性,运行时需要依赖JRE中的类库 JRE:包含了JVM以及代码运行时的类库,时Java程 ...
- 关于 K210 MaixPy 的 I2C 读取设备,搜索不到设备,通信失败的一些原因以及解决方案。
近来对 amigo 开发期间的遇到 I2C 问题做一下总结. 我们发现有一些 I2C 设备搜索不到,主要原因是 DATA 的信号衰减,也可能是 I2C 的总线被拉住了. 软件层面的问题 例如在实现 A ...
- 053 01 Android 零基础入门 01 Java基础语法 05 Java流程控制之循环结构 15 流程控制知识总结
053 01 Android 零基础入门 01 Java基础语法 05 Java流程控制之循环结构 15 流程控制知识总结 本文知识点: 流程控制知识总结 流程控制知识总结 选择结构语句 循环结构语句 ...
- Tensorflow学习笔记No.3
使用tf.data加载数据 tf.data是tensorflow2.0中加入的数据加载模块,是一个非常便捷的处理数据的模块. 这里简单介绍一些tf.data的使用方法. 1.加载tensorflow中 ...
- NOIP提高组2016 D1T2 【天天爱跑步】
码了一个下午加一个晚上吧...... 题目描述: 小c同学认为跑步非常有趣,于是决定制作一款叫做<天天爱跑步>的游戏.<天天爱跑步>是一个养成类游戏,需要玩家每天按时上线,完成 ...
- .Net Core 读取,导入 excel数据 officeopenxml
/// <summary> /// 导出Excel /// </summary> /// <param name="path">路径</p ...
- layui+tp5表单提交回调
layui 前段页面form表单提交数据如果监听表单提交 ,tp5后台操作完成后使用 $this->success('success'); 后前端的页面不会出现layui的layer弹窗提示su ...
- 用网桥和veth实现容器的桥接模式
原理图如下 具体命令先不写了,有时间再写,主要还是用的上一篇说的知识.
- python程序整理(2)
# 写一个函数完成三次登陆功能: # 用户的用户名密码从一个文件register中取出. # register文件包含多个用户名,密码,用户名密码通过|隔开,每个人的用户名密码占用文件中一行. # 完 ...
- selenium元素定位学习笔记
一,定位原则 稳定 简单灵活 唯一 WebDriver提供了两种方式来定位页面元素,分别是find_element_by_XXX和find_elements_by_XXX.第一种方式的结果是在正常情况 ...