Boltzmann Machine 玻尔兹曼机入门
Generative Models
生成模型帮助我们生成新的item,而不只是存储和提取之前的item。Boltzmann Machine就是Generative Models的一种。
Boltzmann Machine
Boltzmann Machine和Hopfield Network对比
- Energy Function是相同的
- 神经元\(x_i\)的取值在0和1之间,而不是Hopfield Network中的-1和1。
- 使用Boltzmann Machine来产生新的状态,而不是提取存储的状态。
- 更新不是确定性的,而是随机性的,使用Sigmoid函数。
Boltzmann Distribution
Boltzmann Distribution是一种在状态空间上的概率分布,公式如下:
\]
- \(E(x)\):energy function
- T:是温度
- Z:partition function,用来保证\(\sum_x p(x)=1\)
通常情况下,直接计算partition function很复杂。但是我们可以利用相邻状态的相对概率通过迭代过程从分布中采样。
Gibbs Sampling
参考博客:https://www.cnblogs.com/aoru45/p/12092453.html
假设我们有一个图像x,对于所有的元素\(x_i=1\)。每一次操作,我们只将一个\(x_i\)变为0,其他的不变,从而得到一个新的图像。
我们用如下的公式来表示两个图像之间的energy function的差:
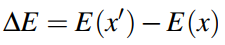
我们可以得到新图像的Boltzmann Distribution,如下:
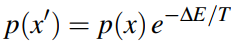
因此,对于所有固定的元素,\(x_i\)取得1或者0的概率如下所示:
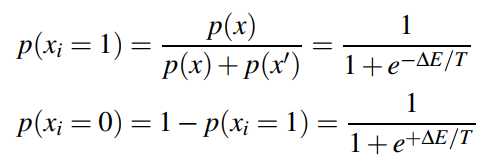
Boltzmann Machine
Boltzmann Machine的操作和Hopfield Network很像,只是再更新神经元的步骤上又差别!Boltzmann Machine在神经元更新的时候有随机性。
在Hopfield Network中, \(x_i\)的变化使得energy function永远不会增大。但是在Boltzmann Machine中,我们用一个概率来令\(x_i=1\):
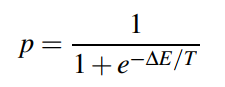
换句话说,这个概率有可能让energy function的值变大。所以:
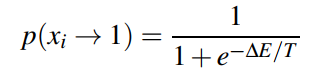
如果这个过程重复迭代很多次,我们最终将会获得一个Boltzmann Distribution中的样本
当\(T\rightarrow \infty\),\(\space p(x_i\rightarrow1)=1/2\)并且\(\space p(x_i\rightarrow0)=1/2\)
当\(T\rightarrow 0\),这个行为将会变得很像Hopfield Network,永远不会让Energy Function增大。\(\space p(x_i\rightarrow1)=0\)
温度T可能是一个固定值,或者它一开始很大,然后逐渐的减小(模拟退火,Simulated Annealing)
Limitations
Boltzmann Machine的局限性在于,每个单元的概率必须是周围单元的线性可分函数。所以,我们可以考虑到的解决办法就是增加隐藏层,将可见的单元和隐藏的单元分开。类似于前馈神经网络中的输入层和隐藏层。目的就是让隐藏单元学习一些隐藏的特征或者潜在的变量,从而帮助系统去对输入进行建模。结构如下图所示:
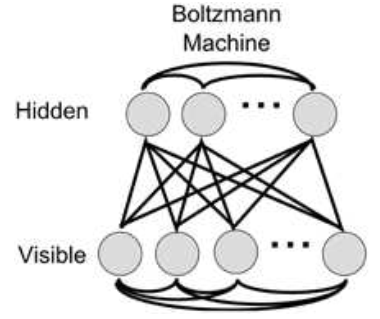
Restricted Boltzmann Machine
如果我们让所有的可见单元之间和隐藏单元之间互相存在连接,训练网络要花非常长的时间。所以,我们通常限制Boltzmannn Machine只在可见单元和隐藏单元之间存在连接,如下图所示:

这样的网络就被称作Restricted Boltzmann Machine,受限玻尔兹曼机。主要特征是:
输入是二元向量
是两层的双向神经网络
- 可见层,v,visible layer
- 隐藏层,h,hidden layer
没有vis-to-vis或者hidden-to-hidden连接
所有可见单元连接到所有隐藏单元,公式如下:\(E(v, h) = -(\sum_i b_i v_i + \sum_j c_j h_j + \sum_{ij} v_i w_{ij}h_j)\)
- \(\sum_i b_i v_i\):可见层偏差
- \(\sum_j c_j h_j\):隐藏层偏差
- \(\sum_{ij} v_i w_{ij}h_j\):可见单元和隐藏单元之间的连接
训练使数据的期望对数概率最大化
因为输入单位和隐藏单位是解耦的,我们可以计算h在v下的条件分布,反之亦然。
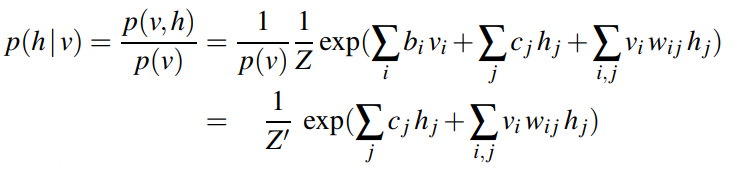
于是,
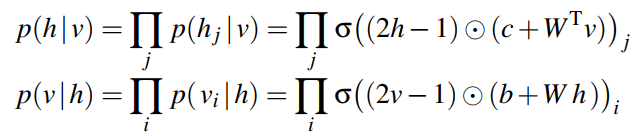
 :component-wise multiplication
:component-wise multiplication- σ(s) = 1/(1 + exp(-s)) ,是Sigmoid函数
Alternating Gibbs Sampling

在Boltzmann Machine中我们可以从Boltzmann Distribution中进行如下抽样:
- 随机选择\(v_0\)
- 从\(p(h|v_0)\)中抽样\(h_0\)
- 从\(p(v|h_0)\)中抽样\(v_1\)
- 从\(p(h|v_1)\)中抽样\(h_1\)
- ...
Training RBM
Contrastive Divergence
通过对比真实和虚假的图片进行训练,优先选择真实的图片
- 从训练数据中选择一个或者多个positive samples { \(v^{(k)}\) }
- 对于每一个\(v^{(k)}\),从\(p(h|v(k))\)中抽样一个隐藏向量\(h^{(k)}\)
- 通过alternating Gibbs sampling 生成一个fake样本{\(v'^{(k)}\)}
- 对于每一个\(v'^{(k)}\),从\(p(h|v'^{(k)})\)中抽样一个隐藏向量\(h'^{(k)}\)
- 更新\({b_i}\),\(c_j\),\(w_{ij}\)去增大\(log\ p(v^{(k)}, h^{(k)}) - log\ p(v'^{(k)}, h'^{(k)})\)
- \(b_i \leftarrow b_i + \eta(v_i - v'_i)\)
- \(c_j \leftarrow c_j + \eta(h_j - h'_j)\)
- \(w_{ij} \leftarrow w_{ij} + \eta(v_i h_j - v'_i h'_j)\)
Quick Contrastive Divergence
在2000‘s的时候,研究人员注意到,这个过程可以通过只取一个额外的样本来加速,而不是运行多次迭代。
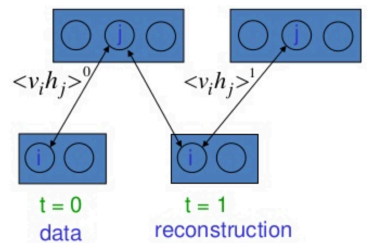
从实数开始,生成隐藏单元,生成假(重构)数字,并分别作为正样本和负样本进行训练
- \(v_0, h_0\): positive sample
- \(v_1, h_1\):negative sample
Deep Boltzmann Machine
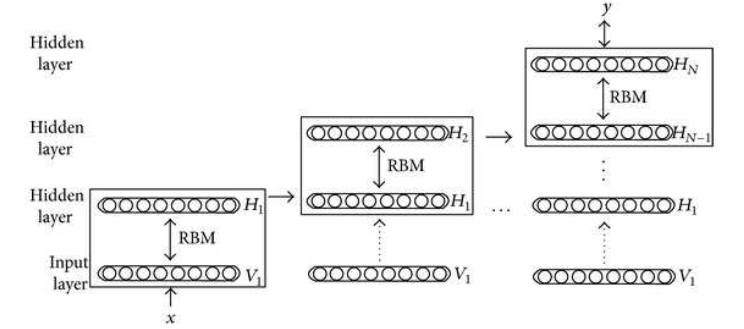
和Boltzmann Machine是相同的方法,但是可以迭代的应用于多层网络。
首先训练输入到第一层的权重。然后保持这些权重不变,继续训练第一层到第二层之间的权重,以此类推。
Greedy Layerwise Pretraining
Deep Boltzmann Machine的一个主要应用是Greedy unsupervised layerwise pretraining(贪婪无监督逐层与训练)。
连续的对每一对layers进行训练,训练成RBM。
当模型训练完成之后,权重和偏差会被储存下来,在下一次进行类似的任务时会被当做前馈神经网络的初始权重和偏差,然后再根据当前任务数据进行反向传播训练。
对于Sigmoid或者tanh激活函数,这一类的预训练能够比直接进行随机初始化权重然后训练取得更好的结果。
Boltzmann Machine 玻尔兹曼机入门的更多相关文章
- 受限玻尔兹曼机(Restricted Boltzmann Machine, RBM) 简介
受限玻尔兹曼机(Restricted Boltzmann Machine,简称RBM)是由Hinton和Sejnowski于1986年提出的一种生成式随机神经网络(generative stochas ...
- 受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)
这篇写的主要是翻译网上一篇关于受限玻尔兹曼机的tutorial,看了那篇博文之后感觉算法方面讲的很清楚,自己收获很大,这里写下来作为学习之用. 原文网址为:http://imonad.com/rbm/ ...
- 限制玻尔兹曼机(Restricted Boltzmann Machine)RBM
假设有一个二部图,每一层的节点之间没有连接,一层是可视层,即输入数据是(v),一层是隐藏层(h),如果假设所有的节点都是随机二值变量节点(只能取0或者1值)同时假设全概率分布满足Boltzmann 分 ...
- 受限玻尔兹曼机(Restricted Boltzmann Machine)
受限玻尔兹曼机(Restricted Boltzmann Machine) 作者:凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/ 1. 生成模型 2. 参数学 ...
- [Hinton] Neural Networks for Machine Learning - Hopfield Nets and Boltzmann Machine
Lecture 11 — Hopfield Nets Lecture 12 — Boltzmann machine learning Ref: 能量模型(EBM).限制波尔兹曼机(RBM) 高大上的模 ...
- 六.随机神经网络Boltzmann(玻尔兹曼机)
Hopfield网络具有最优计算功能,然而网络只能严格按照能量函数递减方式演化,很难避免伪状态的出现,且权值容易陷入局部极小值,无法收敛于全局最优解. 如果反馈神经网络的迭代过程不是那么死板,可以在一 ...
- 机器学习理论基础学习19---受限玻尔兹曼机(Restricted Boltzmann Machine)
一.背景介绍 玻尔兹曼机 = 马尔科夫随机场 + 隐结点 二.RBM的Representation BM存在问题:inference 精确:untractable: 近似:计算量太大 因此为了使计算简 ...
- [原]Machine Learing 入门 —— 开门第0篇
一.最近懒了 7月没怎么写博客,倒是一直在学Machine Learning的入门知识,在这里给大家推荐一个不错的自学网站:https://www.coursera.org/ ,Andrew Ng是联 ...
- Machine Learing 入门 —— 开门第0篇
一.最近懒了 7月没怎么写博客,倒是一直在学Machine Learning的入门知识,在这里给大家推荐一个不错的自学网站:https://www.coursera.org/ ,Andrew Ng是联 ...
随机推荐
- BUUCTF-[极客大挑战 2019]BabySQL 1 详解
打开靶机 应该是love sql惹的事吧,来了个加强版本的sql注入,不过我们先输入账号密码看有什么反应 整一手万能密码,闭合双引号?username=admin&password=admin ...
- Flink深入浅出: 资源管理(v1.11)
-- 图片来自 <国家地理中文网>-- 往期推荐: Flink深入浅出:部署模式 Flink深入浅出:内存模型 Flink深入浅出:JDBC Source从理论到实战 Flink深入浅出: ...
- rs232转以太网
rs232转以太网 rs232转以太网ZLAN5103可以实现RS232/485/422和TCP/IP之间进行透明数据转发.方便地使得串口设备连接到以太网和Internet,实现串口设备的网络化升级. ...
- Android HandlerThread 详解
概述 HandlerThread 相信大家都比较熟悉了,从名字上看是一个带有 Handler 消息循环机制的一个线程,比一般的线程多了消息循环的机制,可以说是Handler + Thread 的结合, ...
- 基于python实现单链表代码
1 """ 2 linklist.py 3 单链表的构建与功能操作 4 重点代码 5 """ 6 7 class Node: 8 " ...
- <二分查找+双指针+前缀和>解决子数组和排序后的区间和
<二分查找+双指针+前缀和>解决子数组和排序后的区间和 题目重现: 给你一个数组 nums ,它包含 n 个正整数.你需要计算所有非空连续子数组的和,并将它们按升序排序,得到一个新的包含 ...
- kafka+zookeeper快速启动
vim zookeeper.sh #!/bin/bash /usr/local/zookeeper/bin/zkServer.sh restart /usr/local/zookeeper/con ...
- 跟我一起学Redis之看完这篇比常人多会三种类型实战(又搞了几个小时)
前言 对于Redis而言,很多小伙伴只关注其关键的五大基础类型:string.hash.list.set.sorted set(有序集合),其实还有三种特殊类型在很多应用场景也比较适合使用,分别是:b ...
- ubuntu基于VSCode的C++编程语言的构建调试环境搭建指南
ubuntu基于VSCode的C++编程语言的构建调试环境搭建指南 首先安装g++ sudo apt install g++ 检查是否安装成功: 在插件栏安装插件c/c++.code runner: ...
- 彩贝网app破解登入参数(涉及app脱壳,反编译java层,so层动态注册,反编译so层)
一.涉及知识点 app脱壳 java层 so层动态注册 二.抓包信息 POST /user/login.html HTTP/1.1 x-app-session: 1603177116420 x-app ...