python批量爬取猫咪图片
不多说直接上代码
首先需要安装需要的库,安装命令如下
pip install BeautifulSoup
pip install requests
pip install urllib
pip install lxmlfrom bs4 import BeautifulSoup # 贵族名宠网页爬虫
import requests
import urllib.request
# 网址
url = 'http://www.hengdadog.com/sale-1.html'
def allpage(): # 获得所有网页
all_url = []
for i in range(1, 8): #循环翻页次数
each_url = url.replace(url[-6], str(i)) # 替换
all_url.append(each_url)
return (all_url) # 返回地址列表 if __name__ == '__main__':
img_url = allpage() # 调用函数
for url in img_url:
# 获得网页源代码
print(url)
requ = requests.get(url)
req = requ.text.encode(requ.encoding).decode()
html = BeautifulSoup(req, 'lxml')
t = 0
# 选择目标url
img_urls = html.find_all('img')
for k in img_urls:
img = k.get('src') # 图片
print(img)
name = str(k.get('alt')) # 名字,这里的强制类型转换很重要
type(name)
# 先本地新建一下文件夹,保存图片并且命名
path = 'F:\\CAT\\' # 路径
file_name = path + name + '.jpg'
imgs = requests.get(img) # 存储入文件
try:
urllib.request.urlretrieve(img, file_name) # 打开图片地址,下载图片保存在本
except:
print("error")
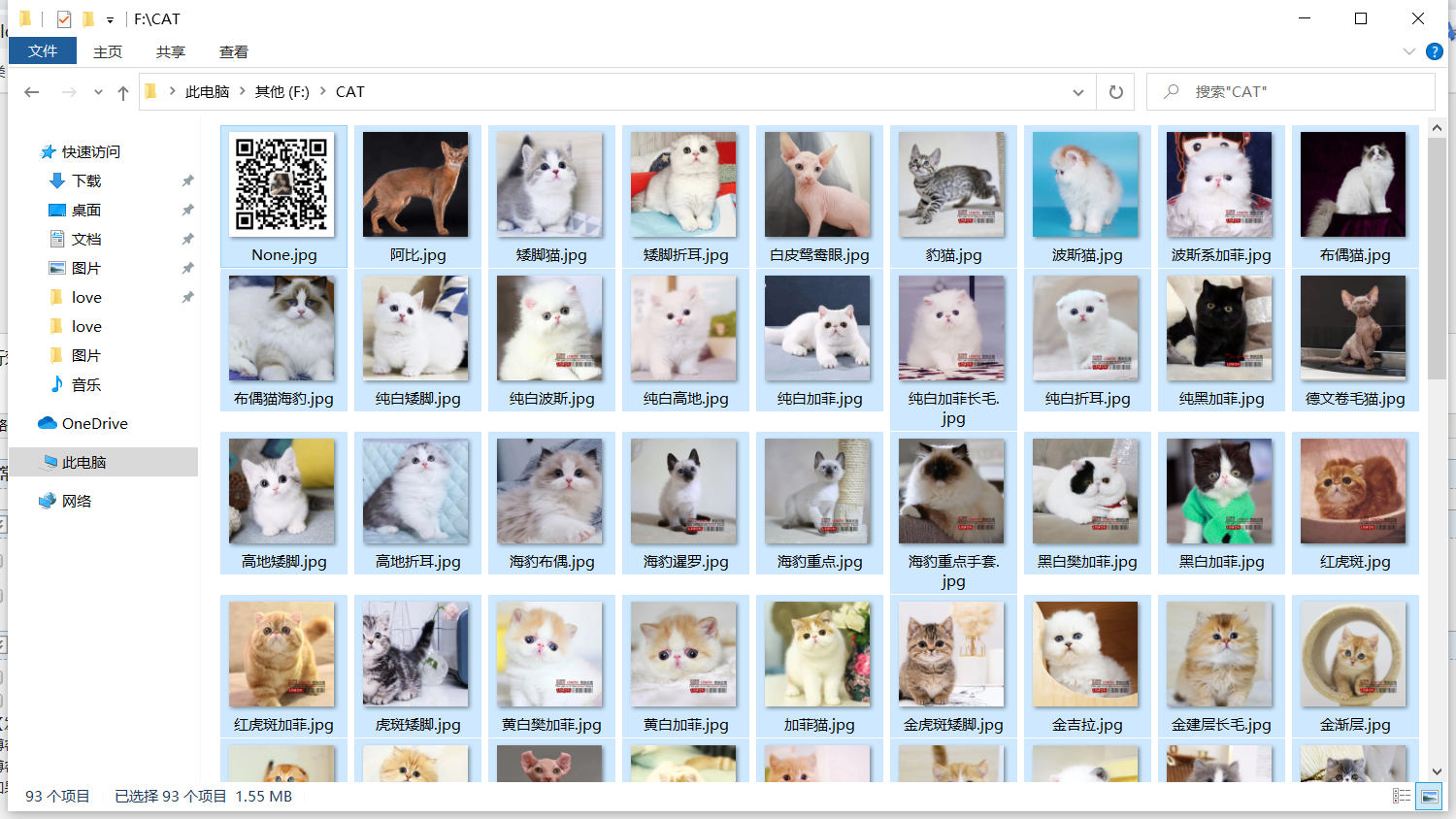
运行效果:
上面代码有不少缺陷,比如需要手动创建目录以及判断目录是否存在,下载没有提示,于是做了些优化:
from bs4 import BeautifulSoup # 贵族名宠网页爬虫
import requests
import urllib.request
import os
# 网址
url = 'http://www.hengdadog.com/sale-1.html'
if os.path.exists('F:\\CAT'):#判断目录是否存在,存在则跳过,不存在则创建
pass
else:
os.mkdir('F:\\CAT')
def allpage(): # 获得所有网页
all_url = []
for i in range(1, 10): #循环翻页次数
each_url = url.replace(url[-6], str(i)) # 替换
all_url.append(each_url)
return (all_url) # 返回地址列表 if __name__ == '__main__':
img_url = allpage() # 调用函数
for url in img_url:
# 获得网页源代码
print(url)
requ = requests.get(url)
req = requ.text.encode(requ.encoding).decode()
html = BeautifulSoup(req, 'lxml')
t = 0
# 选择目标url
img_urls = html.find_all('img')
for k in img_urls:
img = k.get('src') # 图片
print(img)
name = str(k.get('alt')) # 名字,这里的强制类型转换很重要
type(name)
# 保存图片并且命名
path = 'F:\\CAT\\' # 路径
file_name = path + name + '.jpg'
imgs = requests.get(img) # 存储入文件
try:
urllib.request.urlretrieve(img, file_name) # 打开图片地址,下载图片保存在本地,
print('正在下载图片到F:\CAT目录······')
except:
print("error")
打包成EXE文件:
进入文件目录输入如下命令
pyinstaller -F get_cat.py
python批量爬取猫咪图片的更多相关文章
- 使用Python爬虫爬取网络美女图片
代码地址如下:http://www.demodashi.com/demo/13500.html 准备工作 安装python3.6 略 安装requests库(用于请求静态页面) pip install ...
- 从0实现python批量爬取p站插画
一.本文编写缘由 很久没有写过爬虫,已经忘得差不多了.以爬取p站图片为着手点,进行爬虫复习与实践. 欢迎学习Python的小伙伴可以加我扣群86七06七945,大家一起学习讨论 二.获取网页源码 爬取 ...
- python爬虫——爬取NUS-WIDE数据库图片
实验室需要NUS-WIDE数据库中的原图,数据集的地址为http://lms.comp.nus.edu.sg/research/NUS-WIDE.htm 由于这个数据只给了每个图片的URL,所以需 ...
- python 批量爬取四级成绩单
使用本文爬取成绩大致有几个步骤:1.提取表格(或其他格式文件——含有姓名,身份证等信息)中的数据,为进行准考证爬取做准备.2.下载准考证文件并提取出准考证和姓名信息.3.根据得到信息进行数据分析和存储 ...
- 用Python批量爬取优质ip代理
前言 有时候爬的次数太多时ip容易被禁,所以需要ip代理的帮助.今天爬的思路是:到云代理获取大量ip代理,逐个检测,将超时不可用的代理排除,留下优质的ip代理. 一.爬虫分析 首先看看今天要爬取的网址 ...
- python批量爬取动漫免费看!!
实现效果 运行环境 IDE VS2019 Python3.7 Chrome.ChromeDriver Chrome和ChromeDriver的版本需要相互对应 先上代码,代码非常简短,包含空行也才50 ...
- Python批量爬取谷歌原图,2021年最新可用版
文章目录 前言 一.环境配置 1.安装selenium 2.使用正确的谷歌浏览器驱动 二.使用步骤 1.加载chromedriver.exe 2.设置是否开启可视化界面 3.输入关键词.下载图片数.图 ...
- python 批量爬取代理ip
import urllib.request import re import time import random def getResponse(url): req = urllib.request ...
- java爬取猫咪上的图片
首先是对知识点归纳 1.用到获取网页源代码,分析图片地址,发现图片的地址都是按编号排列的,所以想到用循环获取 2.保存图片要用到流操作和文件操作,对两部分知识进行了复习巩固 3.保存后的图片有一部分是 ...
随机推荐
- ViewModel和LiveData问题思考与解答
嗨,大家好,面试真题系列又来了,今天我们说说MVVM架构里的两大组件:ViewModel和LiveData. 还是老样子,提出问题,做出解答. ViewModel 是什么? ViewModel 为什么 ...
- mysql报错10061和10038
用navicat连接报错10038,用sqlyog报错10061,又去查看服务,发现服务丢失 经过一系列的查阅资料,用下面的方式解决了问题 1.用管理员的方式打开命令行窗口 2.进入mysql的bin ...
- 机器学习之K均值算法(K-means)聚类
K均值算法(K-means)聚类 [关键词]K个种子,均值 一.K-means算法原理 聚类的概念:一种无监督的学习,事先不知道类别,自动将相似的对象归到同一个簇中. K-Means算法是一种聚类分析 ...
- pip install kaggle 出现 【网络不可达】?
解决办法: pip install kaggle -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
- 2018-12-7 CSAPP及C++
今天虽然起床迟,但从结果上来看,学习效率还算不赖.从这几天的状况来看,为记录晚上上床后的学习内容,决定把在床上的学习内容算在后一天的学习中.那么从现在开始就可以协商英语的半个小时100个单词了. 英语 ...
- Java_面向对象三大特征
面向对象特征 面向对象三大特征: 继承, 封装, 多态 继承 继承: 子类可以从父类继承属性和方法 对外公开某些属性和方法 要点(eclipse中Ctrl+T查看继承结构) 1.父类也称超类, 基类, ...
- 直播软件开发如何使用FFMPEG推流并保存在本地
最近开发了基于C#的直播软件开发推流器一直不大理想,终于在不懈努力之后研究了一点成果,这边做个笔记:本文着重在于讲解下如何使用ffmpeg进行简单的推流,看似简单几行代码没有官方的文档很吃力.并获取流 ...
- 创建ABP Angular客户端(二)使用模板创建Angular前端
现在我们使用ABP CLI创建Angular客户端. 首先,进入控制台,创建一个空目录,进入这个目录,执行: abp new ZL.Test -u angular 这里我们使用与上一个系列相同的项目名 ...
- JS仿贪吃蛇:一串跟着鼠标的Div
贪吃蛇是一款80后.90后比较熟悉的经典游戏,下面通过简单的JS代码来实现低仿版贪吃蛇效果:随着鼠标的移动,在页面中呈现所有Div块跟随鼠标依次移动,效果如下图所示. <!DOCTYPE htm ...
- [MIT6.006] 22. Daynamic Programming IV: Guitar Fingering, Tetris, Super Mario Bro. 动态规划IV:吉他指弹,俄罗斯方块,超级玛丽奥
之前我们讲到动态规划五步中有个Guessing猜,一般情况下猜有两种情况: 在猜和递归上:猜的是用于解决更大问题的子问题: 在子问题定义上:如果要猜更多,就要增加更多子问题. 下面我们来看如果像背包问 ...