RabbitMQ和Kafka的高可用集群原理
前言
小伙伴们,通过前边文章的阅读,相信大家已经对RocketMQ的基本原理有了一个比较深入的了解,那么大家对当前比较常用的RabbitMQ和Kafka是不是也有兴趣了解一些呢,了解的多一些也不是坏事,面试或者跟人聊技术的时候也会让你更有话语权嘛。
那王子今天就跟大家聊一聊RabbitMQ和Kafka在处理高可用集群时的原理,看看它们与RocketMQ有什么不同。小伙伴们可以重新温习一下常见的消息中间件有哪些?你们是怎么进行技术选型的?这篇文章,了解一下他们之间的区别。
RabbitMQ的高可用
之前我们的文章讲过,RabbitMQ是ActiveMQ的一个很好的替代产品,它是基于主从实现的高可用集群,但它是非分布式的。
RabbitMQ一共有三种模式:单机模式、普通集群模式、镜像集群模式。
单机模式没什么可说的,自己开发练手玩玩就行,我们主要说一下两种集群模式的区别。
普通集群模式
普通集群模式,其实就是将RabbitMQ 部署到多台机器上,每个机器启动一个,它们之间进行消息通信。你创建的 queue,只会放在一个 RabbitMQ 的实例上,其他的实例会同步 queue 的元数据(元数据里包含有 queue 的一些配置信息,通过元数据,可以找到 queue 所在的位置)。你消费的时候,实际上如果连接到了另外一个实例,那么那个实例会通过元数据定位到 queue 所在的位置,然后访问queue所在的实例,拉取数据过来发送给消费者。
整体过程见下图:
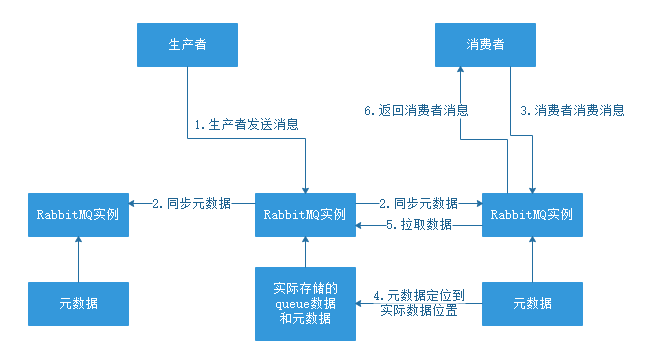
这种方式很麻烦,只是一个普通的集群,而且数据并没有副本,只存储在了一台机器上,只要真实存储数据的机器宕机,系统直接崩溃,因为没有数据可以获取了。
所以可以得出一个结论,这种模式的集群根本不能实现高可用,只能通过负载均衡提高一些MQ的吞吐量,生成环境下是不会使用的。
镜像集群模式
那么真正用于生产环境,实现高可用的方式是什么呢?没错就是接下来要说的镜像集群模式。
它和普通集群模式最大的区别在于,queue数据和原数据不再是单独存储在一台机器上,而是同时存储在多台机器上。也就是说每个RabbitMQ实例都有一份镜像数据(副本数据)。每次写入消息的时候都会自动把数据同步到多台实例上去,这样一旦其中一台机器发生故障,其他机器还有一份副本数据可以继续提供服务,也就实现了高可用。
整个过程看下图:
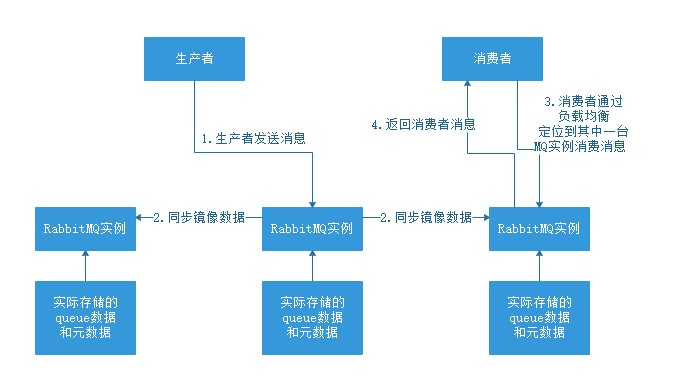
那么如何开启镜像集群模式呢?
RabbitMQ是有强大的管理控制台的,通过管控台可以很容易的配置,具体操作自行百度吧,我们本篇的目的是弄懂原理。
对于一般小型公司,小型项目来讲,这套架构已经可以支持了,但是对于海量大数据的要求,如果每台机器都要有一份镜像副本,而且互相之间还要不停的同步数据,它是很难支持的,因为它不是分布式的。所以我们还是使用RocketMQ吧。
Kafka的高可用
再来聊聊Kafka的高可用,再聊高可用之前,我们先要简单了解下它的基本架构。
它是由多个Broker组成的,每个Broker都是一个节点,小伙伴们是不是想到了RocketMQ的Broker呢。当我们创建Topic的时候,这个Topic是会划分成多个partition的,每个partition又可以存在不同的Broker上,这里的每个partition都会放一部分数据,可以把它理解成一个分片。
由此可见,Kafka是一个天然的分布式消息队列,它的Topic是分成多个partition分布到多个Broker上存储的。
既然讲到这里,可能有很多小伙伴会好奇RocketMQ的Topic是怎么存储的呢?难道RocketMQ的Topic就不会分片了吗?
答案是否定的,RocketMQ也是借鉴了Kafka分片存储的机制,引入了一个新的概念ConsumeQueue用来代替partition,原先kafka,里面partition存储的是整个消息,但是现在ConsumeQueue里面是存储消息的存储地址,但是不存储消息了。现在每个ConsumeQueue存储的是每个消息在commitlog这个文件的地址,但是消息存在于commitlog中。
也就是所有的消息体都写在了一个文件里面,每个ConsumeQueue只是存储这个消息在commitlog中地址。
好了,有关RocketMQ的原理我们之后再单独讲解,现在我们继续看Kafka的高可用实现。
Kafka 0.8 以后,才正式开始支持高可用的,它提供了 HA 机制,就是 replica(复制品) 副本机制。每个 partition 的数据都会同步到其它机器上,形成自己的多个 replica 副本。所有 replica 会选举一个 leader 出来,那么生产和消费都跟这个 leader 打交道,然后其他 replica 就是 follower。写的时候,leader 会负责把数据同步到所有 follower 上去,读的时候就直接读 leader 上的数据即可。只能读写 leader?很简单,要是你可以随意读写每个 follower,那么就要 考虑数据一致性的问题,系统复杂度太高,很容易出问题。Kafka 会均匀地将一个 partition 的所有 replica 分布在不同的机器上,这样才可以提高容错性。
我们看一下下图,就是Kafka的高可用原理:
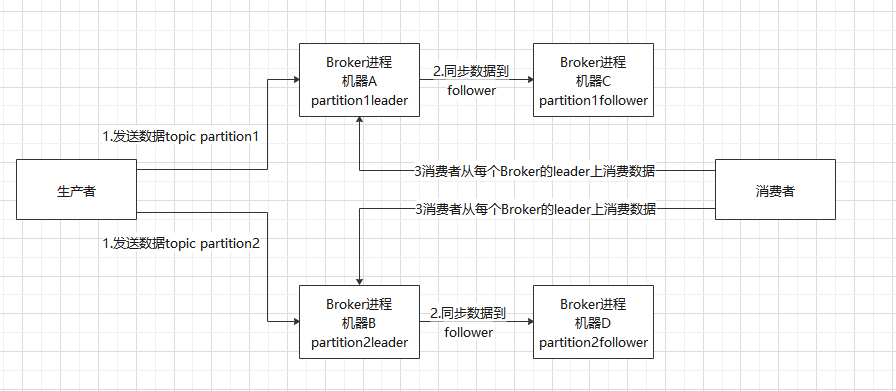
这样的一套架构下,Kafka就实现高可用了。因为如果某个Broker挂掉了,他的partition在其他Broker中都有副本。如果挂掉的Broker上有某个 partition 的 leader,那么此时会从 follower 中重新选举一个新的 leader 出来,大家继续读写那个新的 leader 即可。这就有所谓的高可用性了。
写数据的时候,生产者就向 leader写数据,然后 leader 将数据落地写本地磁盘,接着其他 follower 自己主动从 leader 来 pull 数据。一旦所有 follower 同步好数据了,就会发送 ack 给 leader,leader 收到所有 follower 的 ack 之后,就会返回写成功的消息给生产者。(当然,这只是其中一种模式,还可以适当调整这个行为)
消费的时候,只会从 leader 去读,但是只有当一个消息已经被所有 follower 都同步成功返回 ack 的时候,这个消息才会被消费者读到。
总结
好了,说了这么多,我相信小伙伴们对于RabbitMQ和Kafka的高可用集群原理一定会有个很深的认识了吧。那王子给大家留下一个思考题,现在你能自己说出RabbitMQ、Kafka、RocketMQ的高可用集群有什么不同了吗?
今天的分享就到这里,欢迎大家持续阅读王子的消息中间件专辑,一起闲谈消息中间件的里里外外吧。
往期文章推荐:
中间件专辑:
算法专辑:

RabbitMQ和Kafka的高可用集群原理的更多相关文章
- rabbitmq+haproxy+keepalived实现高可用集群搭建
项目需要搭建rabbitmq的高可用集群,最近在学习搭建过程,在这里记录下可以跟大家一起互相交流(这里只是记录了学习之后自己的搭建过程,许多原理的东西没有细说). 搭建环境 CentOS7 64位 R ...
- RabbitMQ可靠性投递及高可用集群
可靠性投递: 首先需要明确,效率与可靠性是无法兼得的,如果要保证每一个环节都成功,势必会对消息的收发效率造成影响.如果是一些业务实时一致性要求不是特别高的场合,可以牺牲一些可靠性来换取效率. 要保证消 ...
- RabbitMQ学习系列(六): RabbitMQ 高可用集群
前面讲过一些RabbitMQ的安装和用法,也说了说RabbitMQ在一般的业务场景下如何使用.不知道的可以看我前面的博客,http://www.cnblogs.com/zhangweizhong/ca ...
- rabbitmq+ keepalived+haproxy高可用集群详细命令
公司要用rabbitmq研究了两周,特把 rabbitmq 高可用的研究成果备下 后续会更新封装的类库 安装erlang wget http://www.gelou.me/yum/erlang-18. ...
- 搭建 RabbitMQ Server 高可用集群
阅读目录: 准备工作 搭建 RabbitMQ Server 单机版 RabbitMQ Server 高可用集群相关概念 搭建 RabbitMQ Server 高可用集群 搭建 HAProxy 负载均衡 ...
- 搭建 RabbitMQ Server 高可用集群【转】
阅读目录: 准备工作 搭建 RabbitMQ Server 单机版 RabbitMQ Server 高可用集群相关概念 搭建 RabbitMQ Server 高可用集群 搭建 HAProxy 负载均衡 ...
- RabbitMQ高级指南:从配置、使用到高可用集群搭建
本文大纲: 1. RabbitMQ简介 2. RabbitMQ安装与配置 3. C# 如何使用RabbitMQ 4. 几种Exchange模式 5. RPC 远程过程调用 6. RabbitMQ高可用 ...
- RabbitMQ系列之高可用集群
为了实现高可用,我采用LVS+双节点RabbitMq , 架构图如下: 在RabbitMQ之前放了LVS, LVS 采用 rr 轮询算法 , 目的是将请求平均分配到两个真实节点,并配置5672端口监控 ...
- hadoop+yarn+hbase+storm+kafka+spark+zookeeper)高可用集群详细配置
配置 hadoop+yarn+hbase+storm+kafka+spark+zookeeper 高可用集群,同时安装相关组建:JDK,MySQL,Hive,Flume 文章目录 环境介绍 节点介绍 ...
随机推荐
- C#LeetCode刷题之#622-设计循环队列(Design Circular Queue)
问题 该文章的最新版本已迁移至个人博客[比特飞],单击链接 https://www.byteflying.com/archives/4126 访问. 设计你的循环队列实现. 循环队列是一种线性数据结构 ...
- nodejs版本DESede/CBC/PKCS5Padding算法封装(3des)
最近对接了一个第三方支付项目,用的加密算法是根本没听过的:DESede/CBC/PKCS5Padding 这个算法真的是坑爹了,网上搜索了一堆只有java版本是正常的,nodejs版本的各种问题,我了 ...
- java如何简单的将一个三位正整数分解成三个数
public class Leet { public static void main(String[] args) { Scanner scanner = new Scanner(System.in ...
- java中Math的常用方法整理
public class Demo{ public static void main(String args[]){ /** *Math.sqrt()//计算平方根 *Math.cbrt()//计算立 ...
- openvswitch ovs-appctl 使用
参考链接:https://www.cnblogs.com/zqyanywn/p/10501590.html 1. fdb/show bridge 列出指定桥上每个MAC直至与VLAN的对应信息,并且包 ...
- 企业级Registry仓库Harbor的部署与简介
Harbor 是Vmware公司开源的企业级Docker Registry管理项目,开源项目地址:https://github.com/vmware/harbor Harbor的所有组件都在Docke ...
- Linux磁盘分区、挂载、查看文件大小
快速查看系统文件大小命令 du -ah --max-depth=1 后面可以添加文件目录 ,如果不添加默认当前目录. 下面进入正题~~ 磁盘分区.挂载 引言: ①.分区的方式 a)mbr分区: 最多支 ...
- CentOS7(Linux)源码安装Redis
介绍 项目中经常需要用到Redis做缓存数据库,可是还有小伙伴不会在Linux上安装Redis,毕竟我们开发的项目都是要在服务器上运行的,今天就来讲讲如何在CentOS7环境使用源码进行安装Redis ...
- IDEA创建MAVEN项目并使用tomcat启动
一.开发环境准备 1.JDK1.8,已经配置好环境变量 2.IDEA2019.2,目前稳定版里面个人认为还不错的 3.tomcat服务器,笔者使用的是apache-tomcat-8.5.57 4.使用 ...
- 总结删除文件或文件夹的7种方法-JAVA IO基础总结第4篇
本文是Java IO总结系列篇的第4篇,前篇的访问地址如下: 总结java中创建并写文件的5种方式-JAVA IO基础总结第一篇 总结java从文件中读取数据的6种方法-JAVA IO基础总结第二篇 ...