一篇文章让你明白CPU缓存一致性协议MESI

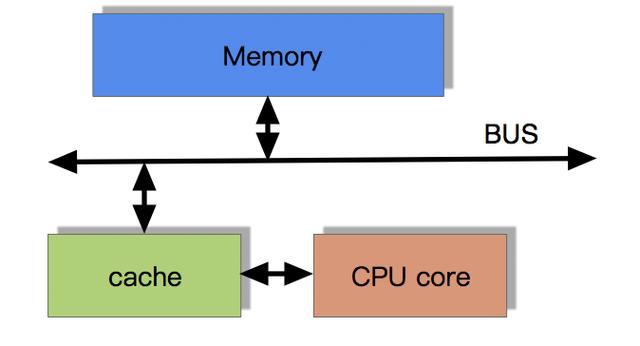
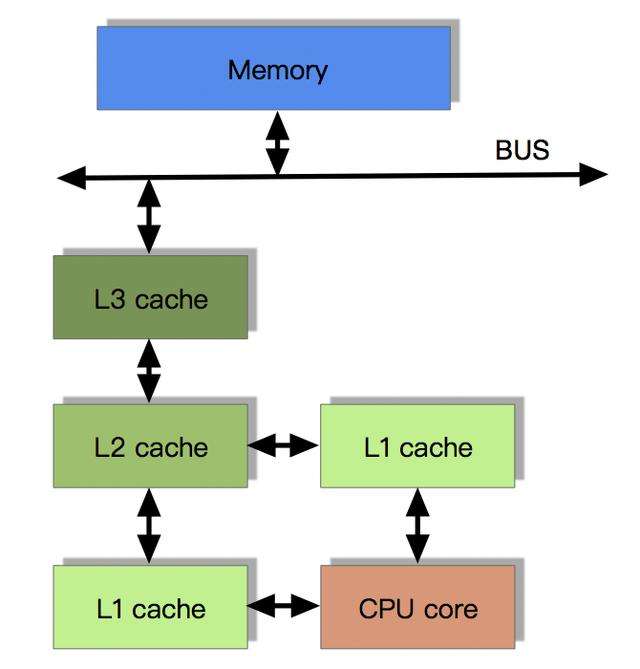
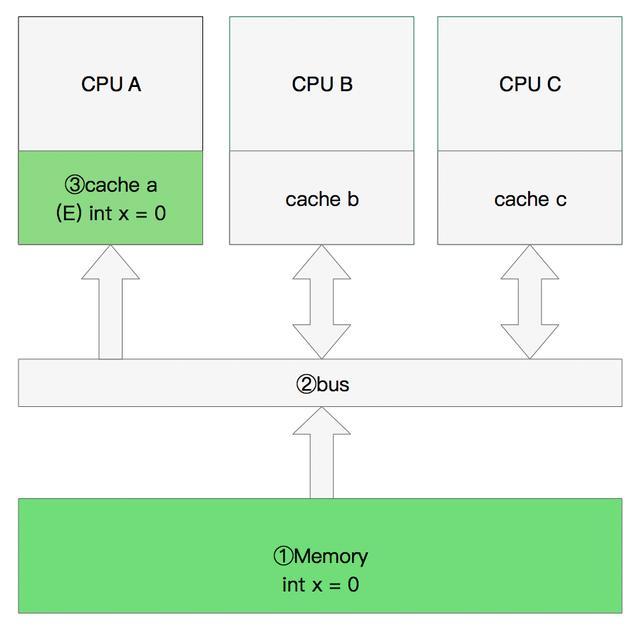
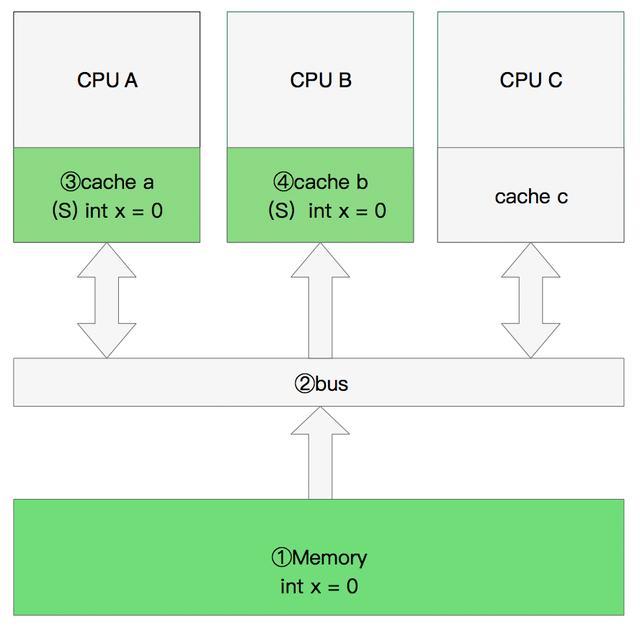
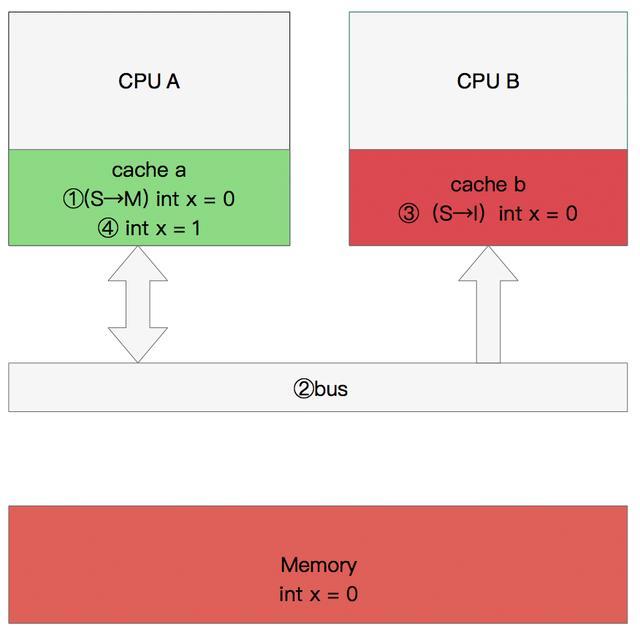
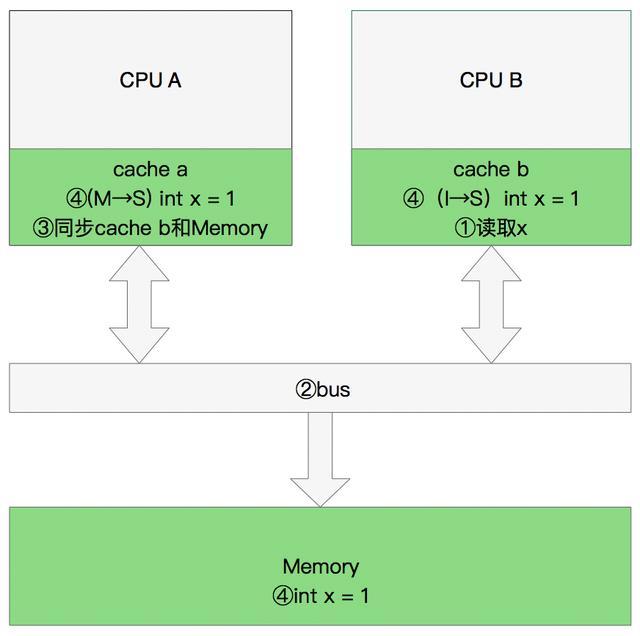
- 程序以及数据被加载到主内存
- 指令和数据被加载到CPU的高速缓存
- CPU执行指令,把结果写到高速缓存
- 高速缓存中的数据写回主内存
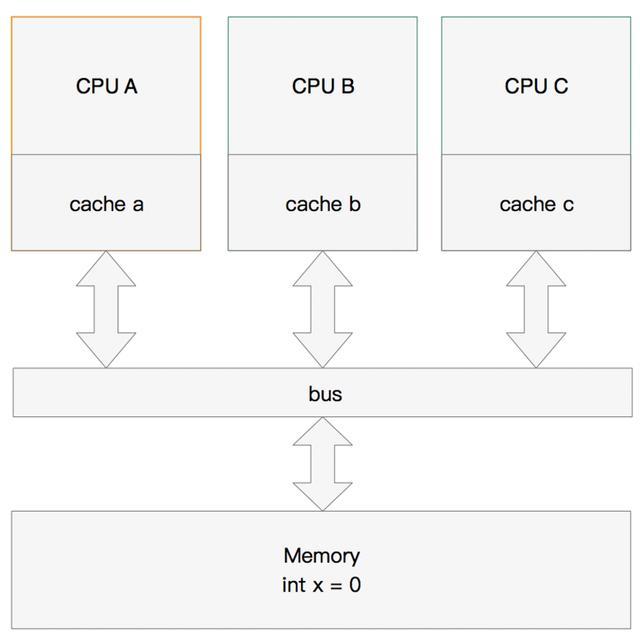
void exeToCPUA(){
value = 10;
isFinsh = true;
}
void exeToCPUB(){
if(isFinsh){
/
F{0XCAB)LKNIT0K@G.gif) alue一定等于10?!
alue一定等于10?!assert value == 10;
}
}
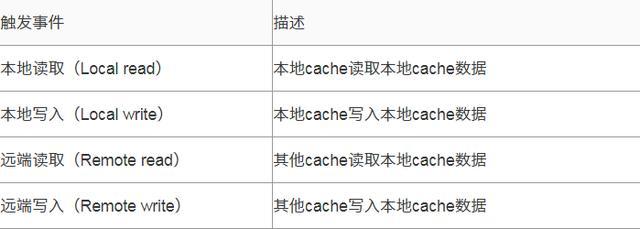
- 对于所有的收到的Invalidate请求,Invalidate Acknowlege消息必须立刻发送
- Invalidate并不真正执行,而是被放在一个特殊的队列中,在方便的时候才会去执行。
- 处理器不会发送任何消息给所处理的缓存条目,直到它处理Invalidate。

void executedOnCpu0() {
value = 10;
//在更新数据之前必须将所有存储缓存(store buffer)中的指令执行完毕。
storeMemoryBarrier();
finished = true;
}
void executedOnCpu1() {
while(!finished);
//在读取之前将所有失效队列中关于该数据的指令执行完毕。
loadMemoryBarrier();
assert value == 10;
}
一篇文章让你明白CPU缓存一致性协议MESI的更多相关文章
- 并发研究之CPU缓存一致性协议(MESI)
CPU缓存一致性协议MESI CPU高速缓存(Cache Memory) CPU为何要有高速缓存 CPU在摩尔定律的指导下以每18个月翻一番的速度在发展,然而内存和硬盘的发展速度远远不及CPU.这就造 ...
- C和C++中的volatile、内存屏障和CPU缓存一致性协议MESI
目录 1. 前言2 2. 结论2 3. volatile应用场景3 4. 内存屏障(Memory Barrier)4 5. setjmp和longjmp4 1) 结果1(非优化编译:g++ -g -o ...
- CPU缓存一致性协议—MESI详解
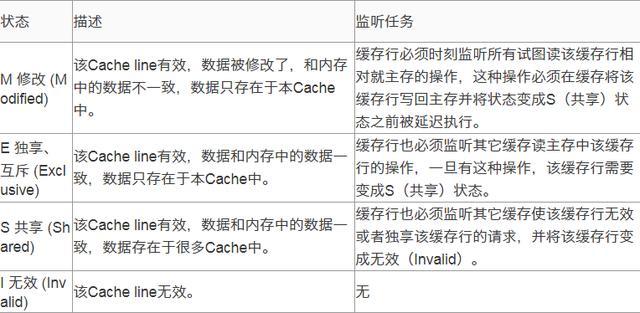
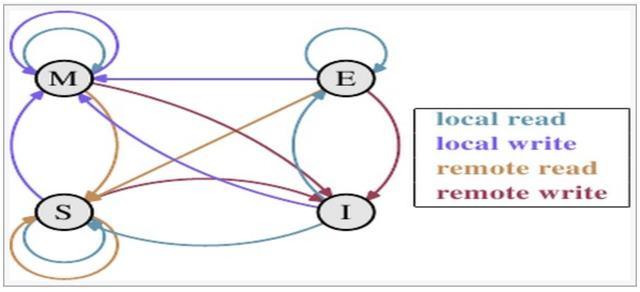
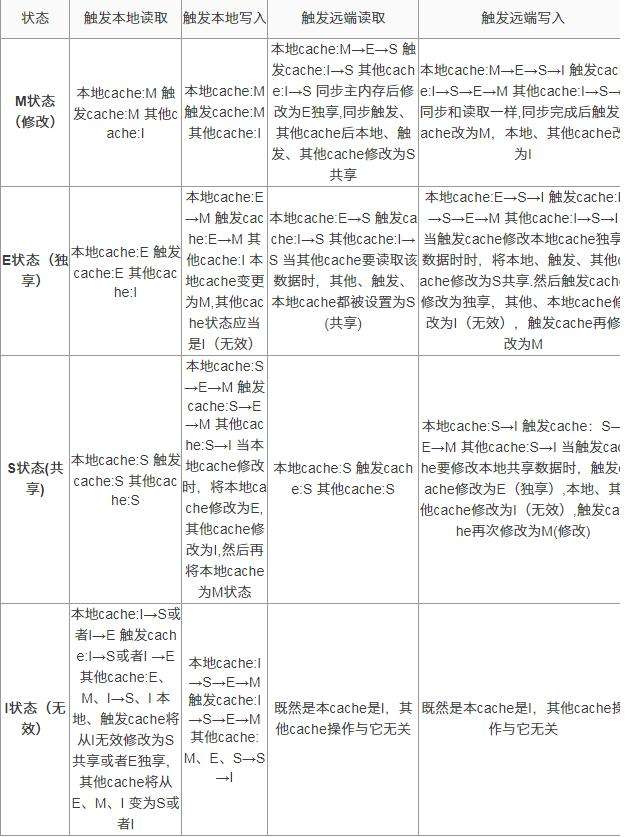
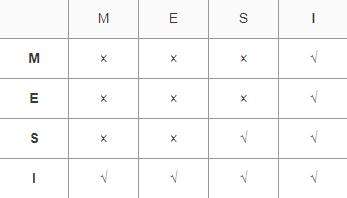
MESI(也称伊利诺斯协议)是一种广泛使用的支持写回策略的缓存一致性协议,该协议被应用在Intel奔腾系列的CPU中. MESI协议中的状态 CPU中每个缓存行使用的4种状态进行标记(使用额外的两位b ...
- CPU缓存一致性协议与java中的volatile关键字
有关缓存一致性协议MESI自行百度. 提出问题:volatile在缓存一致性协议上又做了哪些事情?为啥它不保证原子性? 在缓存一致性协议下,CPU为了执行效率使用了写(存储)缓存和失效队列从而导致对用 ...
- Java内存模型(二)volatile底层实现(CPU的缓存一致性协议MESI)
CPU的缓存一致性协议MESI 在多核CPU中,内存中的数据会在多个核心中存在数据副本,某一个核心发生修改操作,就产生了数据不一致的问题,而一致性协议正是用于保证多个CPU cache之间缓存共享数据 ...
- 多线程之:MESI-CPU缓存一致性协议
MESI(Modified Exclusive Shared Or Invalid)(也称为伊利诺斯协议,是因为该协议由伊利诺斯州立大学提出)是一种广泛使用的支持写回策略的缓存一致性协议,该协议被应用 ...
- MESI-CPU缓存一致性协议
转http://blog.csdn.net/realxie/article/details/7317630 http://en.wikipedia.org/wiki/MESI_protocol MES ...
- 缓存一致性协议 mesi
m : modified e : exlusive s : shared i : invalid 四种状态的转换略过,现在讨论为什么有了这个协议,i++在多线程上还不是安全的. 两个cpu A B同时 ...
- 10 张图打开 CPU 缓存一致性的大门
前言 直接上,不多 BB 了. 正文 CPU Cache 的数据写入 随着时间的推移,CPU 和内存的访问性能相差越来越大,于是就在 CPU 内部嵌入了 CPU Cache(高速缓存),CPU Cac ...
随机推荐
- kafka-manager新手安装入门指南
Kafka-manager安装教程 使用环境 ubuntu18.04 Java 8 一.下载kafka 官网下载地址如下 https://www.apache.org/dyn/closer.cgi?p ...
- C#取视频某一帧图片
首先下载 ffmpeg http://ffmpeg.org/ 注意一定要从官网下载,其他地方可以会有问题 解压后在 bin 目录下找到 ffmpeg.exe 用到的使命是 -i 视频地址 -ss 第几 ...
- 《软件安装》centos 安装 mysql
上期问题回顾 全球 IPv4 地址正式耗尽,IPv4地址大约42.9亿,按照理论来说,每一个联网的设备都需要IP地址,而现在全球联网设备远远不止42.9亿,那么,这么多设备是怎么处理联网的问题呢? 先 ...
- MySQL统计各个表中的记录数
通过下面的SQL语句可以统计出数据库的各个表中的记录数: select table_schema, table_name,table_rows from information_schema.tabl ...
- HttpClient POST/SET方法
前言: 网络API接口:https://api.apiopen.top/searchMusic 此API接口返回类型为JSON格式类型 GET:从指定资源请求数据 POST:向指定资源提交要被处理的数 ...
- 【Android - 控件】之V - Toolbar的使用
Toolbar是Android V7包中的一个控件,用来代替Action Bar作为界面的头部标题栏布局.Toolbar相对于Action Bar的特点是更加灵活,可以显示在任何位置. 首先先来看To ...
- rsync工具、rsync常用选项、以及rsync通过ssh同步 使用介绍
第8周5月14日任务 课程内容: 10.28 rsync工具介绍10.29/10.30 rsync常用选项10.31 rsync通过ssh同步 10.28 rsync工具介绍 rsync是一个同步的工 ...
- c语言l博客作业02
问题 答案 这个作业属于哪个课程 C语言程序设计l 这个作业要求在哪里 https://edu.cnblogs.com/campus/zswxy/SE2019-2/homework/8687 我在这个 ...
- python_编程面试题
使用递归方法对一个数组求最大值和最小值 """ 用递归算法求解一个数组的最大值和最小值 思路: 1.首先假设这个列表只有1个元素或两个元素 2.再考虑超过两个元素的情况, ...
- io流函数略解(java)[一]
背景 最近在做安卓的过程中,因为im app经常涉及到读取与写入的io问题,所以总结一下.下文使用的是java语言. 实践 材料: java eclipse 1.File 在操作系统中我们一般能看到的 ...