大数据学习笔记——Spark完全分布式完整部署教程
Spark完全分布式完整部署教程
继Mapreduce之后,作为新一代并且是主流的计算引擎,学好Spark是非常重要的,这一篇博客会专门介绍如何部署一个分布式的Spark计算框架,在之后的博客中,更会讲到Spark的基本模块的介绍以及底层原理,好了,废话不多说,直接开始吧!
1. 安装准备
部署Spark时,我们使用的版本如下所示:

2. 正式安装
1. 将spark-2.4.3-bin-hadoop2.7.tgz文件使用远程传输软件发送至/home/centos/downloads目录下
2. 将spark-2.4.3-bin-hadoop2.7.tgz解压缩至/soft目录下
tar -xzvf spark-2.4.3-bin-hadoop2.7.tgz -C /soft
3. 进入到/soft目录下,配置spark的符号链接
cd /soft
ln -s spark-2.4.3-bin-hadoop2.7 spark
4. 修改并生效环境变量
nano /etc/profile
在文件末尾添加以下代码:
#spark环境变量
export SPARK_HOME=/soft/spark
export PATH=$PATH:$SPARK_HOME/bin
生效环境变量后保存退出
source /etc/profile
5. 规划集群部署方案
根据现有的虚拟机配置,集群部署方案为:s101节点作为master节点,s102 - s104作为worker节点
6. 使用脚本分发spark软件包以及/etc/profile文件到所有节点
cd /soft
xsync.sh spark-2.4.3-bin-hadoop2.7
xsync.sh /etc/profile
7. 使用ssh连接到除s101外的其他所有节点创建符号链接
ssh s102
cd /soft
ln -s spark-2.4.3-bin-hadoop2.7 spark
exit
其他节点同理
8. 配置spark的配置文件并分发到所有节点
cd /soft/spark/conf
cp spark-env.sh.template spark-env.sh
nano spark-env.sh
在文件末尾处添加后保存退出:
export JAVA_HOME=/soft/jdk
export HADOOP_CONF_DIR=/soft/hadoop/etc/hadoop
准备好如下文件,避免每次提交spark job上传spark类库:
先用WinScp将spark的类库放到/home/centos目录下
将spark的类库上传到HDFS文件系统上去:hdfs dfs -put /home/centos/spark_lib.zip /
修改spark-defaults配置文件:
cp spark-defaults.conf.template spark-defaults.conf
nano spark-defaults.conf
在文件末尾处添加后保存退出:
spark.yarn.archive hdfs://mycluster/spark_lib.zip
cp slaves.template slaves
nano slaves
在文件中末尾处删除localhost并添加以下命令后后保存退出:
s102
s103
s104
分发上述三个个配置文件
xsync.sh spark-env.sh
xsync.sh spark-defaults.conf
xsync.sh slaves
9. 启动spark集群
/soft/spark/sbin/start-all.sh
10. 查看进程
xcall.sh jps
出现以下画面:

11. 查看WebUI
http://s101:8080
配置大功告成!!!

12. 结合hadoop启动spark的各种模式检测是否都能正常启动
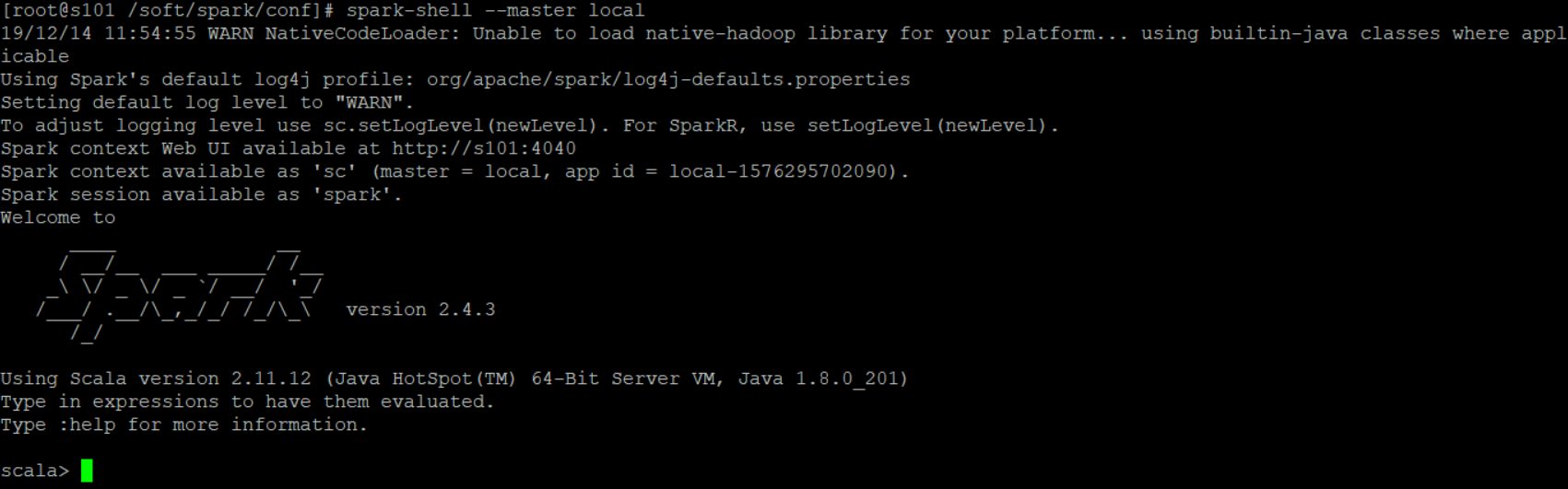
启动local模式:spark-shell --master local
启动hadoop集群:
xzk.sh start
start-all.sh
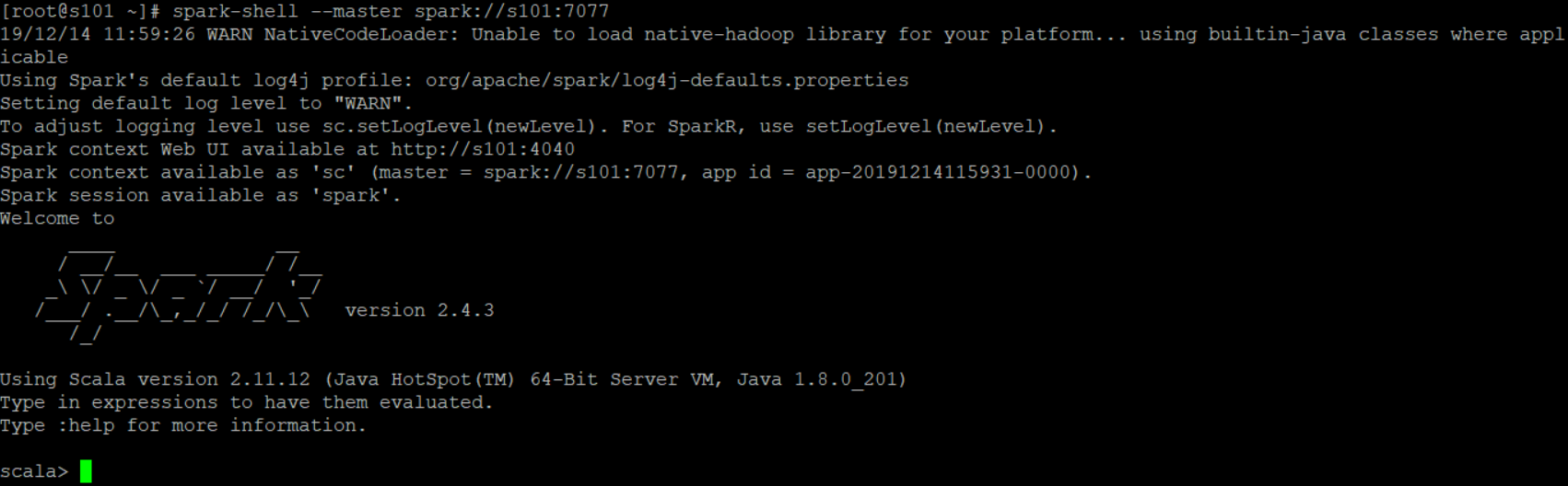
然后启动standalone模式:spark-shell --master spark://s101:7077
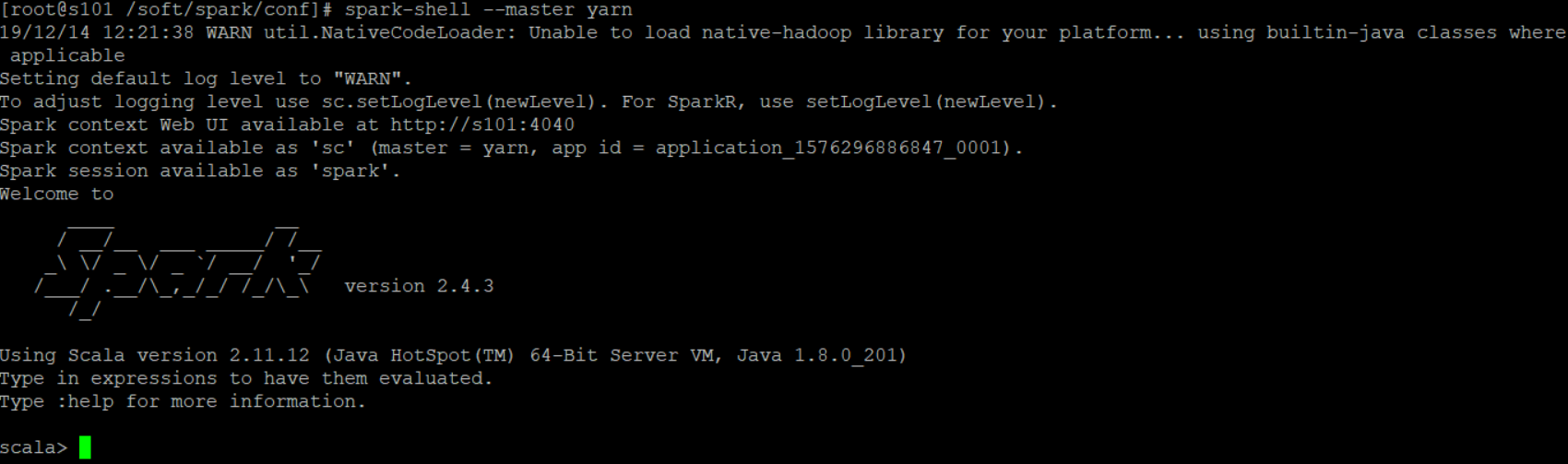
最后测试yarn模式是否能连接成功:spark-shell --master yarn
大数据学习笔记——Spark完全分布式完整部署教程的更多相关文章
- 大数据学习笔记——Spark工作机制以及API详解
Spark工作机制以及API详解 本篇文章将会承接上篇关于如何部署Spark分布式集群的博客,会先对RDD编程中常见的API进行一个整理,接着再结合源代码以及注释详细地解读spark的作业提交流程,调 ...
- 大数据学习笔记——Hbase高可用+完全分布式完整部署教程
Hbase高可用+完全分布式完整部署教程 本篇博客承接上一篇sqoop的部署教程,将会详细介绍完全分布式并且是高可用模式下的Hbase的部署流程,废话不多说,我们直接开始! 1. 安装准备 部署Hba ...
- 大数据学习笔记——Linux完整部署篇(实操部分)
Linux环境搭建完整操作流程(包含mysql的安装步骤) 从现在开始,就正式进入到大数据学习的前置工作了,即Linux的学习以及安装,作为运行大数据框架的基础环境,Linux操作系统的重要性自然不言 ...
- 大数据学习笔记——Hadoop编程实战之HDFS
HDFS基本API的应用(包含IDEA的基本设置) 在上一篇博客中,本人详细地整理了如何从0搭建一个HA模式下的分布式Hadoop平台,那么,在上一篇的基础上,我们终于可以进行编程实操了,同样,在编程 ...
- 大数据学习笔记——Java篇之集合框架(ArrayList)
Java集合框架学习笔记 1. Java集合框架中各接口或子类的继承以及实现关系图: 2. 数组和集合类的区别整理: 数组: 1. 长度是固定的 2. 既可以存放基本数据类型又可以存放引用数据类型 3 ...
- 大数据学习笔记——Hadoop高可用完全分布式模式完整部署教程(包含zookeeper)
高可用模式下的Hadoop集群搭建 本篇博客将会在之前写过的Linux的完整部署的基础上进行,暂时不会涉及到伪分布式或者完全分布式模式搭建,由于HA模式涉及到的配置文件较多,维护起来也较为复杂,相信学 ...
- 大数据学习笔记5 - Spark
Spark是一个基于内存计算的大数据并行计算框架.所以,Spark并不能完全替代Hadoop,主要用于替代Hadoop中的MapReduce计算模型. 在实际应用中,大数据处理无非是以下几个类型: 复 ...
- 大数据学习笔记——Sqoop完整部署流程
Sqoop详细部署教程 Sqoop是一个将hadoop与关系型数据库之间进行数据传输,批量数据导入导出的工具,注意,导入是指将数据从RDBMS导入到hadoop而导出则是指将数据从hadoop导出到R ...
- 大数据学习笔记之Hadoop(一):Hadoop入门
文章目录 大数据概论 一.大数据概念 二.大数据的特点 三.大数据能干啥? 四.大数据发展前景 五.企业数据部的业务流程分析 六.企业数据部的一般组织结构 Hadoop(入门) 一 从Hadoop框架 ...
随机推荐
- 搭建Nginx七层反向代理
基于https://www.cnblogs.com/Dfengshuo/p/11911406.html这个基础上,在来补充下七层代理的配置方式.简单理解下四层和七层协议负载的区别吧,四层是网络层,负载 ...
- Linux下安装和使用WPS,体验良好
最近,我在ubuntu18.04.3下面使用LibreOffice,感觉良好. 正值政府机关在进行2019年度正版软件使用情况整改,保护知识产权,我表示热烈欢迎并强烈支持. 通过摸底,因为以前采购的w ...
- JavaWeb04-JSP及会话跟踪技术
JSP入门 1 JSP概述 1.1 什么是JSP JSP(Java Server Pages)是JavaWeb服务器端的动态资源.它与html页面的作用是相同的,显示数据和获取数据. 1.2 JSP的 ...
- ubuntu 16.04上源码编译dlib教程 | compile dlib on ubuntu 16.04
本文首发于个人博客https://kezunlin.me/post/c6ead512/,欢迎阅读! compile dlib on ubuntu 16.04 Series Part 1: compil ...
- Flex修改皮肤样式
Flex修改皮肤大致有三种方式: (以button为例) 第一种:修改外观 1.flex项目中新建mxml外观.
- 每天复现一个漏洞--vulhub
phpmyadmin scripts/setup.php 反序列化漏洞(WooYun-2016-199433) 漏洞原理:http://www.polaris-lab.com/index.php/ar ...
- 前端开发单位em
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- CSS中如果实现元素浮动,看这篇文章就足够了
浮动基本介绍 在标准文档流中元素分为2种,块级元素和行内元素,如果想让一些元素既要有块级元素的特点也同时保留行内元素特点,只能让这些元素脱离标准文档流即可. 浮动可以让元素脱离标准文档流,可以实现让多 ...
- 记一次uboot中gunzip解压速度慢的问题排查
背景 在项目中需要用到解压功能,之前还记录了下,将uboot解压代码移植到另外的bootloader中时,碰到的效率问题.最终查明是cache的配置导致的. https://www.cnblogs.c ...
- 都9012了,Java8中的日期时间API你还没有掌握?
一,Java8日期时间API产生的前因后果 1.1 为什么要重新定义一套日期时间API 操作不方便:java中最初的Date不能直接对指定字段进行加减操作也不支持国际化,后来新增了Calendar,但 ...