究竟是什么毁了我的impl实现
Impl模式早就有过接触(本文特指通过指针完成impl),我晓得它具有以下优点:
- 减少头文件暴露出来的非必要内部类(提供静态库,动态库时尤其重要);
- 减小文件间的编译依存关系,大型代码库的编译时间就不会那么折磨人了。
Impl会带来性能的损耗,每次访问都因为指针增加了间接性,还有一个微小的指针内存消耗。但是基于以上优点,除非你十分确定它造成了性能损耗,否则就让它存在吧。
Qt中大量使用Impl,具体可见https://wiki.qt.io/D-Pointer中关于Q_D和Q_Q宏的解释。
然而,如何使用智能指针,我是说基于std::unique_ptr实现正确的impl模式,就有点意思了。
错误做法
#include <boost/noncopyable.hpp>
#include <memory>
class Trace1 : public boost::noncopyable {
public:
Trace1();
~Trace1() = default;
void test();
private:
class TraceImpl;
std::unique_ptr<TraceImpl> _impl;
};
这是我初版代码,关于_impl的实现细节,存放于cpp中,如下所示:
class Trace1::TraceImpl {
public:
TraceImpl() = default;
static std::string test() {
return "hello trace1";
}
};
Trace1::Trace1() :
_impl(std::make_unique<Trace1::TraceImpl>()) {
}
void Trace1::test() {
std::cout << _impl->test() << std::endl;
}
很无情,我遇到了错误,错误如下所示:
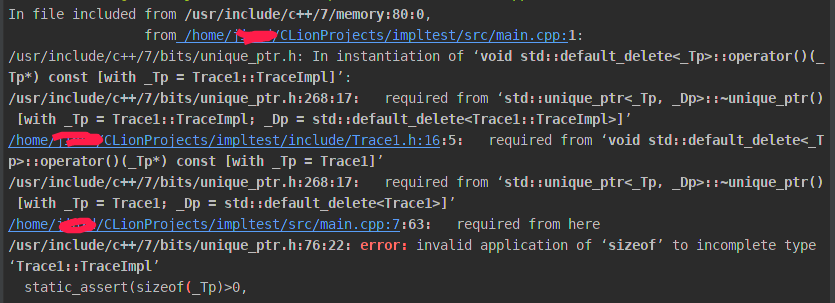
为什么会这样呢,报错信息提示TraceImpl是一个不完整的类型。
其实,就是编译器看到TraceImpl,无法在编译期间确定TraceImpl的大小。此处我们使用的是std::unique_ptr,其中存放的是一个指针,没必要知道TraceImpl的具体大小(换成std::shared_ptr就不会这个报错)。
错误分析
往上看报错信息,发现std::unique_ptr的析构函数有点意思:
/usr/include/c++/7/bits/unique_ptr.h: In instantiation of ‘void std::default_delete<_Tp>::operator()(_Tp*) const [with _Tp = Trace1::TraceImpl]’:
/usr/include/c++/7/bits/unique_ptr.h:268:17: required from ‘std::unique_ptr<_Tp, _Dp>::~unique_ptr() [with _Tp = Trace1::TraceImpl; _Dp = std::default_delete<Trace1::TraceImpl>]’
/home/jinxd/CLionProjects/impltest/include/Trace1.h:16:5: required from ‘void std::default_delete<_Tp>::operator()(_Tp*) const [with _Tp = Trace1]’
/usr/include/c++/7/bits/unique_ptr.h:268:17: required from ‘std::unique_ptr<_Tp, _Dp>::~unique_ptr() [with _Tp = Trace1; _Dp = std::default_delete<Trace1>]’
报错信息中,有两段提到了析构函数,而且都是默认析构函数:std::default_delete<_Tp>。应该知道,我们的代码在编译的时候,会被编译器往里面添加点作料。按照c++的哲学就是,你不需要知道我们添加了什么,你只需要晓得添加后的结果是什么。可是,为了解决错误,我们必须知道大概添加了什么。
代码中,Trace1的析构函数标记为default,函数体中无具体代码,Trace1的析构函数有很大的可能性被inline了。如果函数被inline了,那么引用Trace1.h的main文件中,析构函数会被文本段落展开。
以前我就就在想,析构函数中没有代码,展开也不应该产生影响。错就错在,编译之后的析构函数被扩展了,塞入了_impl的销毁代码。销毁_impl必然会调用到std::unique_ptr的析构函数。std:unique_ptr在销毁的时候,会调用构造函数中传来的析构函数(如果你没有显式提供析构函数,那么就是用编译器扩展的默认析构函数)。此处调用TraceImpl的默认析构函数,发现类只有前置声明(具体实现在Trace1.cpp文件中,main中没有引入此文件),因此不知道TraceImpl的实际大小。
问题出来了,为什么需要知道TraceImpl的实际大小呢?可以认为c++中的new是malloc的封装,执行new的时候,其实就是根据类的大小malloc固定大小的空间,反之,delete也就是释放掉指定大小的空间。你不提供声明,这就让编译器很为难,只能报错了。
解决方式
解决方式很简单,一切都是inline引起的,那么我们就让析构函数outline。通过这种方式,将Trace1的析构函数实现转移至Trace1.cpp中,从而发现TraceImpl的具体实现。代码如下所示:
// Trace1.h
class Trace1 : public boost::noncopyable {
public:
Trace1();
~Trace1();
void test();
private:
class TraceImpl;
std::unique_ptr<TraceImpl> _impl;
};
// Trace1.cpp
class Trace1::TraceImpl {
public:
TraceImpl() = default;
static std::string test() {
return "hello trace1";
}
};
Trace1::Trace1() :
_impl(std::make_unique<Trace1::TraceImpl>()) {
}
Trace1::~Trace1() = default;
void Trace1::test() {
std::cout << _impl->test() << std::endl;
}
如此操作,析构函数就可以看见TraceImpl的声明,于是就能正确的执行析构操作。
换个姿势
上文中提及了,std::unique_ptr的构造函数中,第二个入参其实是一个仿函数,那么我们也可以通过仿函数解决这个问题,代码如下所示:
// Trace2.h
class Trace2 : public boost::noncopyable {
public:
Trace2();
~Trace2() = default;
void test();
private:
class TraceImpl;
class TraceImplDeleter {
public:
void operator()(TraceImpl *p);
};
std::unique_ptr<TraceImpl, TraceImplDeleter> _impl;
};
// Trace2.cpp
class Trace2::TraceImpl {
public:
TraceImpl() = default;
static std::string test() {
return "hello trace2";
}
};
void Trace2::TraceImplDeleter::operator()(Trace2::TraceImpl *p) {
delete p;
}
Trace2::Trace2() :
_impl(new Trace2::TraceImpl, Trace2::TraceImplDeleter()) {
}
void Trace2::test() {
std::cout << _impl->test() << std::endl;
}
是的,仿函数的实现置于Trace2.cpp中,完美解决问题。
不过我不喜欢这样的写法,因为没法使用std::make_unique初始化_impl,原因就这么简单。
PS:
如果您觉得我的文章对您有帮助,请关注我的微信公众号,谢谢!

究竟是什么毁了我的impl实现的更多相关文章
- Spring + SpringMVC + Druid + JPA(Hibernate impl) 给你一个稳妥的后端解决方案
最近手头的工作不太繁重,自己试着倒腾了一套用开源框架组建的 JavaWeb 后端解决方案. 感觉还不错的样子,但实践和项目实战还是有很大的落差,这里只做抛砖引玉之用. 项目 git 地址:https: ...
- Repository 仓储,你的归宿究竟在哪?(一)-仓储的概念
写在前面 写这篇博文的灵感来自<如何开始DDD(完)>,很感谢young.han兄这几天的坚持,陆陆续续写了几篇有关于领域驱动设计的博文,让园中再次刮了一阵"DDD探讨风&quo ...
- eclipse maven SLF4J: Failed to load class org.slf4j.impl.StaticLoggerBinder
现象:运行eclipse maven build,console 有红色日志如下: SLF4J: Failed to load class "org.slf4j.impl.StaticLog ...
- reduce个数究竟和哪些因素有关
reduce的数目究竟和哪些因素有关 1.我们知道map的数量和文件数.文件大小.块大小.以及split大小有关,而reduce的数量跟哪些因素有关呢? 设置mapred.tasktracker.r ...
- Repository 仓储,你的归宿究竟在哪?(上)
Repository 仓储,你的归宿究竟在哪?(上) 写在前面 写这篇博文的灵感来自<如何开始DDD(完)>,很感谢young.han兄这几天的坚持,陆陆续续写了几篇有关于领域驱动设计的博 ...
- 学习ASP.NET Core,怎能不了解请求处理管道[1]: 中间件究竟是个什么东西?
ASP.NET Core管道虽然在结构组成上显得非常简单,但是在具体实现上却涉及到太多的对象,所以我们在 "通过重建Hosting系统理解HTTP请求在ASP.NET Core管道中的处理流 ...
- Repository 仓储,你的归宿究竟在哪?(三)-SELECT 某某某。。。
写在前面 首先,本篇博文主要包含两个主题: 领域服务中使用仓储 SELECT 某某某(有点晕?请看下面.) 上一篇:Repository 仓储,你的归宿究竟在哪?(二)-这样的应用层代码,你能接受吗? ...
- 简述9种社交概念 SNS究竟用来干嘛?
1.QQ 必备型交流工具基本上每一个网民最少有一个QQ,QQ已经成为网民的标配,网络生活中已经离不开QQ了.虽然大家嘴上一直在骂 QQ这个不好,那个不对,但是很少有人能彻底离开QQ.QQ属于IM软件, ...
- 爬虫 htmlUnit遇到Cannot locate declared field class org.apache.http.impl.client.HttpClientBuilder.dnsResolve错误
当在使用htmlUnit时遇到无法定位org.apache.http.impl.client.HttpClientBuilder.dnsResolver类时,此时所需要的依赖包为: <depen ...
随机推荐
- SAP会计年度变式
会计年度变式用来确定SAP系统中每个公司的会计记账期间的变式.顾名思议,每个公司的会计年度变式必须与其实际使用的会计年度匹配. 在SAP系统中,每个会计年度最多允许有16个记账期间,其中 ...
- iOS---------审核被拒(隔壁群发的)
Hello, We are writing to let you know the results of your appeal for your app The App Review Board e ...
- IDEA org.apache.ibatis.binding.BindingException: Invalid bound statement (not found):
引用地址:https://guozh.net/idea-org-apache-ibatis-binding-bindingexception-invalid-bound-statement-not-f ...
- bayaim_mysql5.6下table_open_cache参数
bayaim_mysql5.6下table_open_cache参数_2017年12月26日10:51:58 原创 作者:bayaim 时间:2017-12-26 10:57:17 1 0删除编辑 ( ...
- django升级2.1python升级3.7时出现的错误:"trying to load '%s': %s" % (entry[1], e) django.template.library.InvalidTemplateLibrary:
django升级2.1python升级3.7时出现如下的错误: "trying to load '%s': %s" % (entry[1], e) django.template. ...
- 微信小程序API交互反馈,wx.showToast显示消息提示框
导读:wx.showToast(OBJECT) 显示消息提示框. OBJECT参数说明: 参数 类型 必填 说明 最低版本 title String 是 提示的内容 icon String 否 图标, ...
- Python—创建进程的三种方式
方式一:os.fork() 子进程是从os.fork得到的值,然后赋值开始执行的.即子进程不执行os.fork,从得到的值开始执行. 父进程中fork之前的内容子进程同样会复制,但父子进程空间独立,f ...
- Linux下磁盘实战操作命令
企业真实场景由于硬盘常年大量读写,经常会出现坏盘,需要更换硬盘.或者由于磁盘空间不足,需添加新硬盘,新添加的硬盘需要经过格式化.分区才能被 Linux 系统所使用. 虚拟机 CentOS 7 Linu ...
- MYSQL5.7的安装(yum、二进制、编译安装)
目录 一.环境说明 二.YUM安装 1.安装MYSQL-YUM源 2.安装说明 3.安装前的准备 4.安装 5.启动 三.变更root密码 四.BINARY-INSTALL 1.基础环境准备 2.建立 ...
- ACWING 95 费解的开关 解题记录
你玩过“拉灯”游戏吗?25盏灯排成一个5x5的方形.每一个灯都有一个开关,游戏者可以改变它的状态.每一步,游戏者可以改变某一个灯的状态.游戏者改变一个灯的状态会产生连锁反应:和这个灯上下左右相邻的灯也 ...