利用ImageAI库只需几行python代码超简实现目标检测
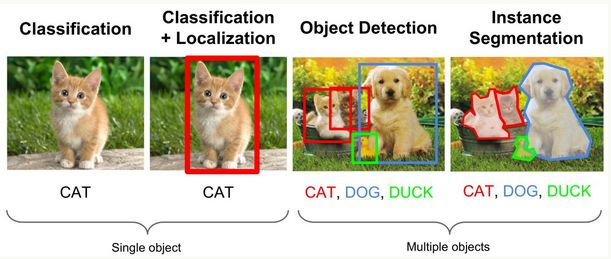
什么是目标检测
目标检测关注图像中特定的物体目标,需要同时解决解决定位(localization) + 识别(Recognition)。相比分类,检测给出的是对图片前景和背景的理解,我们需要从背景中分离出感兴趣的目标,并确定这一目标的描述(类别和位置),因此检测模型的输出是一个列表,列表的每一项使用一个数组给出检出目标的类别和位置(常用矩形检测框的坐标表示)。
通俗的说,Object Detection的目的是在目标图中将目标用一个框框出来,并且识别出这个框中的是啥,而且最好的话是能够将图片的所有物体都框出来。
目标检测算法
目前目标检测领域的深度学习方法主要分为两类:两阶段(Two Stages)的目标检测算法;一阶段(One Stage)目标检测算法。
Two Stages
首先由算法(algorithm)生成一系列作为样本的候选框,再通过卷积神经网络进行样本(Sample)分类。也称为基于候选区域(Region Proposal)的算法。常见的算法有R-CNN、Fast R-CNN、Faster R-CNN等等。
One Stage
不需要产生候选框,直接将目标框定位的问题转化为回归(Regression)问题处理,也称为基于端到端(End-to-End)的算法。常见的算法有YOLO、SSD等等。
python实现
本文主要讲述如何实现目标检测,至于背后的原理不过多赘述,可以去看相关的论文。
ImageAI是一个简单易用的计算机视觉Python库,使得开发者可以轻松的将最新的最先进的人工智能功能整合进他们的应用。
ImageAI本着简洁的原则,支持最先进的机器学习算法,用于图像预测,自定义图像预测,物体检测,视频检测,视频对象跟踪和图像预测训练。
依赖
- Python 3.5.1(及更高版本)
- pip3
- Tensorflow 1.4.0(及更高版本)
- Numpy 1.13.1(及更高版本)
- SciPy 0.19.1(及更高版本)
- OpenCV
- pillow
- Matplotlib
- h5py
- Keras 2.x
安装
- 命令行安装
pip3 install https://github.com/OlafenwaMoses/ImageAI/releases/download/2.0.1/imageai-2.0.1-py3-none-any.whl
- 下载imageai-2.1.0-py3-none-any.whl 安装文件并在命令行中指定安装文件的路径
pip3 install .\imageai-2.1.0-py3-none-any.whl
使用
Image支持的深度学习的算法有RetinaNet,YOLOv3,TinyYoLOv3。ImageAI已经在COCO数据集上预先训练好了对应的三个模型,根据需要可以选择不同的模型。可以通过下面的链接进行下载使用:
- Download RetinaNet Model - resnet50_coco_best_v2.0.1.h5
- Download YOLOv3 Model - yolo.h5
- Download TinyYOLOv3 Model - yolo-tiny.h5
以上模型可以检测并识别以下80种不同的目标:
person, bicycle, car, motorcycle, airplane,
bus, train, truck, boat, traffic light, fire hydrant, stop_sign,
parking meter, bench, bird, cat, dog, horse, sheep, cow,
elephant, bear, zebra, giraffe, backpack, umbrella,
handbag, tie, suitcase, frisbee, skis, snowboard,
sports ball, kite, baseball bat, baseball glove, skateboard,
surfboard, tennis racket, bottle, wine glass, cup, fork, knife,
spoon, bowl, banana, apple, sandwich, orange, broccoli, carrot,
hot dog, pizza, donot, cake, chair, couch, potted plant, bed,
dining table, toilet, tv, laptop, mouse, remote, keyboard,
cell phone, microwave, oven, toaster, sink, refrigerator,
book, clock, vase, scissors, teddy bear, hair dryer,
toothbrush
先来看看完整的代码,使用YOLOv3算法对13张照片进行目标识别。
from imageai.Detection import ObjectDetection
import os
detector = ObjectDetection()
detector.setModelTypeAsYOLOv3()
detector.setModelPath("./model/yolo.h5")
detector.loadModel()
path = os.getcwd()
input_image_list = os.listdir(path+"\pic\input")
input_image_list = sorted(input_image_list, key = lambda i:len(i),reverse = False)
size = len(input_image_list)
for i in range(size):
input_image_path = os.path.join(path+"\pic\input", input_image_list[i])
output_image_path = os.path.join(path+"\pic\output", input_image_list[i])
detections, extract_detected_objects = detector.detectObjectsFromImage(input_image=input_image_path,
output_image_path=output_image_path,
extract_detected_objects=True)
print('------------------- %d -------------------' % int(i + 1))
for eachObject in detections:
print(eachObject["name"], " : ", eachObject["percentage_probability"], " : ", eachObject["box_points"])
print('------------------- %d -------------------' % int(i + 1))
首先第一行导入ImageAI Object Detection类,在第二行导入os库。
然后创建了ObjectDetection类的新实例,接着就可以选择要使用的算法。分别有以下三个函数:
.setModelTypeAsRetinaNet()
.setModelTypeAsYOLOv3()
.setModelTypeAsTinyYOLOv3()
选择好算法之后就要设置模型文件路径,这里给出的路径必须要和选择的算法一样。
.setModelPath()
- 参数path(必须):模型文件的路径
载入模型。
.loadModel()
- 参数detection_speed(可选):最多可以减少80%的时间,但是会导致精确度的下降。可选的值有: “normal”, “fast”, “faster”, “fastest” 和 “flash”。默认值是 “normal”。
通过os库的函数得到输入输出文件的路径等,这不是本文重点,跳过不表。
开始对图像进行目标检测。
.detectObjectsFromImage()
- 参数input_image(必须):待检测图像的路径
- 参数output_image(必须):输出图像的路径
- 参数parameter minimum_percentage_probability(可选):能接受的最低预测概率。默认值是50%。
- 参数display_percentage_probability(可选):是否展示预测的概率。默认值是True。
- 参数display_object_name(可选):是否展示识别物品的名称。默认值是True。
- 参数extract_detected_objects(可选):是否将识别出的物品图片保存。默认是False。
返回值根据不同的参数也有不同,但都会返回一个an array of dictionaries。字典包括以下几个属性:
* name (string)
* percentage_probability (float)
* box_points (tuple of x1,y1,x2 and y2 coordinates)
前面说过可以识别80种目标,在这里也可以选择只识别自己想要的目标。
custom = detector.CustomObjects(person=True, dog=True)
detections = detector.detectCustomObjectsFromImage( custom_objects=custom, input_image=os.path.join(execution_path , "image3.jpg"), output_image_path=os.path.join(execution_path , "image3new-custom.jpg"), minimum_percentage_probability=30)
首先用定义自己想要的目标,其余的目标会被设置为False。然后配合.detectCustomObjectsFromImage()进行目标检测。
主要的代码基本如上所述,接下来看结果。先看看图片中只有一个目标的效果。


------------------- 10 -------------------
dog : 98.83476495742798 : (117, 91, 311, 360)
dog : 99.24255609512329 : (503, 133, 638, 364)
dog : 99.274742603302 : (338, 38, 487, 379)
------------------- 10 -------------------
效果还是不错的。再看看如果图片中有多个目标识别的结果如何。


------------------- 4 -------------------
book : 55.76887130737305 : (455, 74, 487, 146)
book : 82.22097754478455 : (466, 11, 482, 69)
tv : 99.34800863265991 : (25, 40, 182, 161)
bed : 88.7190580368042 : (60, 264, 500, 352)
cat : 99.54025745391846 : (214, 125, 433, 332)
------------------- 4 -------------------
识别度还是很高的,背后人眼都看不清的书本都能被识别。
附录
GitHub:https://github.com/Professorchen/Computer-Vision/tree/master/object-detection
利用ImageAI库只需几行python代码超简实现目标检测的更多相关文章
- 只需几行 JavaScript 代码,网页瞬间有气质了!
最近在网上闲逛,发现一个特别好玩的 JavaScript 库,叫 RoughNotation.干嘛用的呢?就是在网页上给文字加标注,比如下划线.方框.高亮文字背景等,不过是手写风格的!截图给大家感受下 ...
- 在PHP中使用CURL,“撩”服务器只需几行——php curl详细解析和常见大坑
在PHP中使用CURL,"撩"服务器只需几行--php curl详细解析和常见大坑 七夕啦,作为开发,妹子没得撩就"撩"下服务器吧,妹子有得撩的同学那就左拥妹子 ...
- 在PHP中使用CURL,“撩”服务器只需几行
在PHP中使用CURL,“撩”服务器只需几行https://segmentfault.com/a/1190000006220620 七夕啦,作为开发,妹子没得撩就“撩”下服务器吧,妹子有得撩的同学那就 ...
- 一个 11 行 Python 代码实现的神经网络
一个 11 行 Python 代码实现的神经网络 2015/12/02 · 实践项目 · 15 评论· 神经网络 分享到:18 本文由 伯乐在线 - 耶鲁怕冷 翻译,Namco 校稿.未经许可,禁止转 ...
- 200行Python代码实现2048
200行Python代码实现2048 一.实验说明 1. 环境登录 无需密码自动登录,系统用户名shiyanlou 2. 环境介绍 本实验环境采用带桌面的Ubuntu Linux环境,实验中会用到桌面 ...
- 40多行python代码开发一个区块链。
40多行python代码开发一个区块链?可信吗?我们将通过Python 2动手开发实现一个迷你区块链来帮你真正理解区块链技术的核心原理.python开发区块链的源代码保存在Github. 尽管有人认为 ...
- 10 行 Python 代码实现模糊查询/智能提示
10 行 Python 代码实现模糊查询/智能提示 1.导语: 模糊匹配可以算是现代编辑器(如 Eclipse 等各种 IDE)的一个必备特性了,它所做的就是根据用户输入的部分内容,猜测用户想要的 ...
- 20行Python代码爬取王者荣耀全英雄皮肤
引言王者荣耀大家都玩过吧,没玩过的也应该听说过,作为时下最火的手机MOBA游戏,咳咳,好像跑题了.我们今天的重点是爬取王者荣耀所有英雄的所有皮肤,而且仅仅使用20行Python代码即可完成. 准备工作 ...
- 10行Python代码计算汽车数量
当你还是个孩子坐车旅行的时候,你玩过数经过的汽车的数目的游戏吗? 在这篇文章中,我将教你如何使用10行Python代码构建自己的汽车计数程序. 以下是环境及相应的版本库: Python版本 3.6.9 ...
随机推荐
- 浅谈 JavaScript 中 Array 类型的方法使用
前言:Array 类型是 JavaScript 中除了 Object 类型以外最常用的类型. 一.创建数组 JavaScript 中的数组与其他语言中的数组有着很大的区别.例如Java.PHP等语言中 ...
- c++ 二分答案
c++ 二分答案 问题 使得x^x达到或超过n位数字的最小正整数x是多少?n<=2000000000 分析 对与这种较难求解的问题,我们很难想出较好的解决策略.但是,我们至少知道答案一定在1与2 ...
- 【全网首发】使用vs2017+qt5.12.4编译64位debug和release的qgis3.4.9
一.摘要: 搜索网络没有发现一篇文章完整的介绍如何编译qgis3.4.x的debug版本,官方的指导也长时间不再更新. 所以前前后后花了4天搞定qgis的debug编译,并成功运行,废话不多说,直接上 ...
- springmvc上传文件踩过的坑
@RequestMapping("/addTweet") public String addTweet(TweetVO tweetVO, HttpServletRequest re ...
- 如何在vue中监听scroll,从而实现滑动加载更多
首先需要明确3个定义: 文档高度:整个页面的高度 可视窗口高度:你看到的浏览器可视屏幕高度 滚动条滚动高度: 滚动条下滑过的高度 当 文档高度 = 可视窗口高度 + 滚动条高度 时,滚动条正好到底. ...
- E11000 duplicate key error index
E11000 duplicate key error index mongodb插入报错,重复主键问题,有唯一键值重复 一般使用collection.insertOne(doc);插入一条已存在主键的 ...
- 解密Kafka吞吐量高的原因
众所周知kafka的吞吐量比一般的消息队列要高,号称the fastest,那他是如何做到的,让我们从以下几个方面分析一下原因. 生产者(写入数据) 生产者(producer)是负责向Kafka提交数 ...
- Java 面向对象面试题
1.Java面向对象的三种特性 封装:封装是把数据和操作数据的方法封装起来,对数据的访问只能通过已定义的接口进行访问. Java的四种访问控制符: - 默认的(default):不使用任何修饰符,在同 ...
- NetworkStream.Read
Reads data from the NetworkStream. 参数 buffer 类型:System.Byte[]类型 Byte 的数组,它是内存中用于存储从 NetworkStream 读取 ...
- js - 原生ajax访问后台读取数据并显示在页面上
1.前台调用ajax访问后台方法,并接收数据 <%@ page contentType="text/html;charset=UTF-8" language="ja ...