Python3爬虫基础实战篇之机票数据采集
项目:艺龙国内机票实时数据爬虫
使用模块:requests(请求模块),js2py(js执行模块),json(解析json),xpath(解析网页)。
项目流程:
- 分析网站数据来源。
- 编写爬虫脚本。
- 验证数据准确性。
- js逆向破解参数生成。
- 更换请求参数城市(飞机起飞城市和落地城市或日期)测试结果是否正常。
1.分析网站数据来源
进入艺龙机票列表搜索页,附上链接http://flight.elong.com/flightsearch/list?departCity=bjs&arriveCity=sha&departdate=2018-12-24,链接参数日期自行更改。
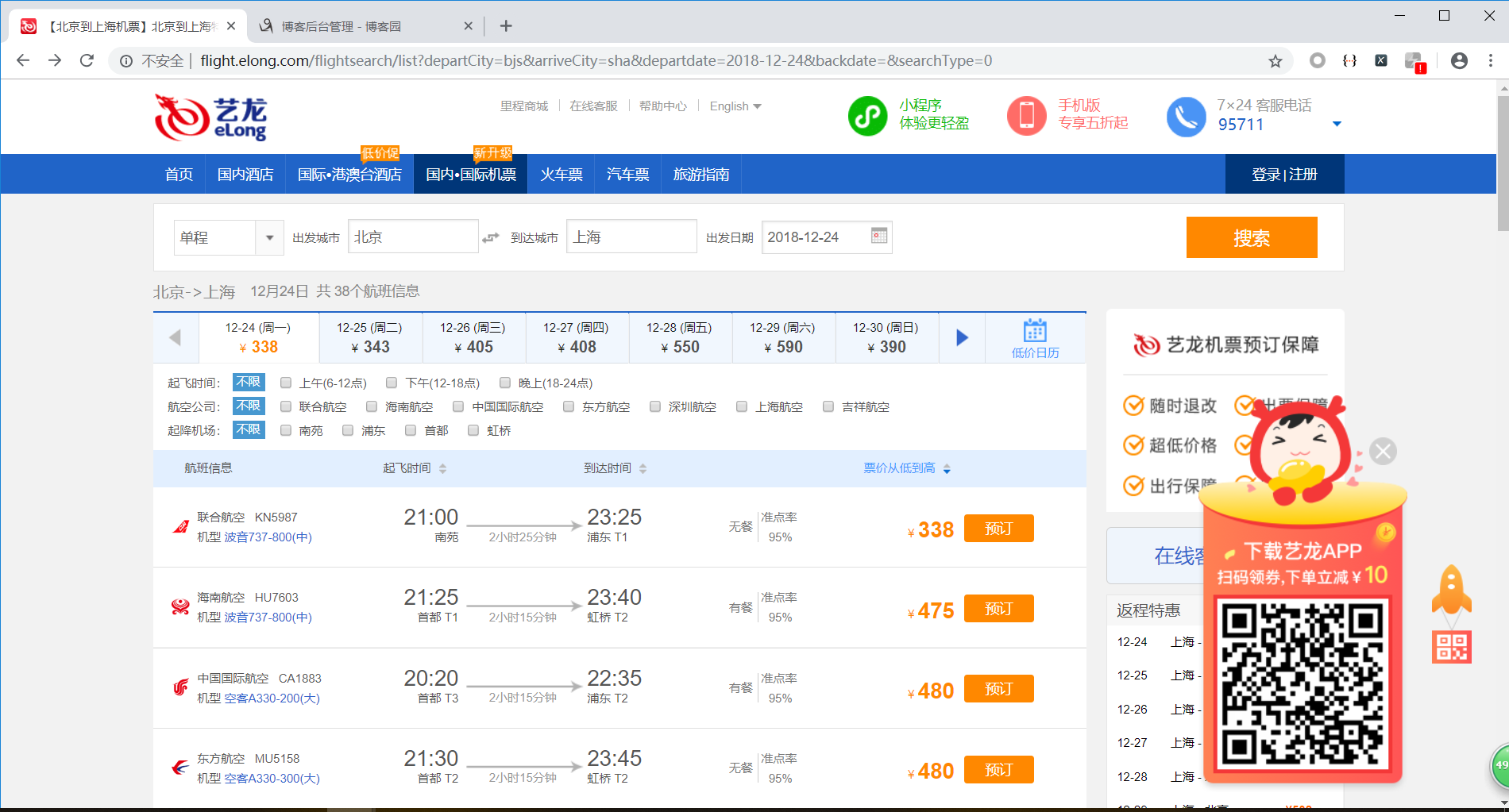
一般情况数据为调用接口获得,或是在页面中嵌入,这里很明显是调用了接口。
F12打开开发者工具(谷歌浏览器),选择network中的xhr,然后刷新页面或重新搜索,查看调用的接口。(这一步也可以使用抓包工具,推荐使用Fiddler,网上有许多汉化版的,看个人习惯吧。)

调用了四个接口,点击接口查看返回结果,确定数据来源。
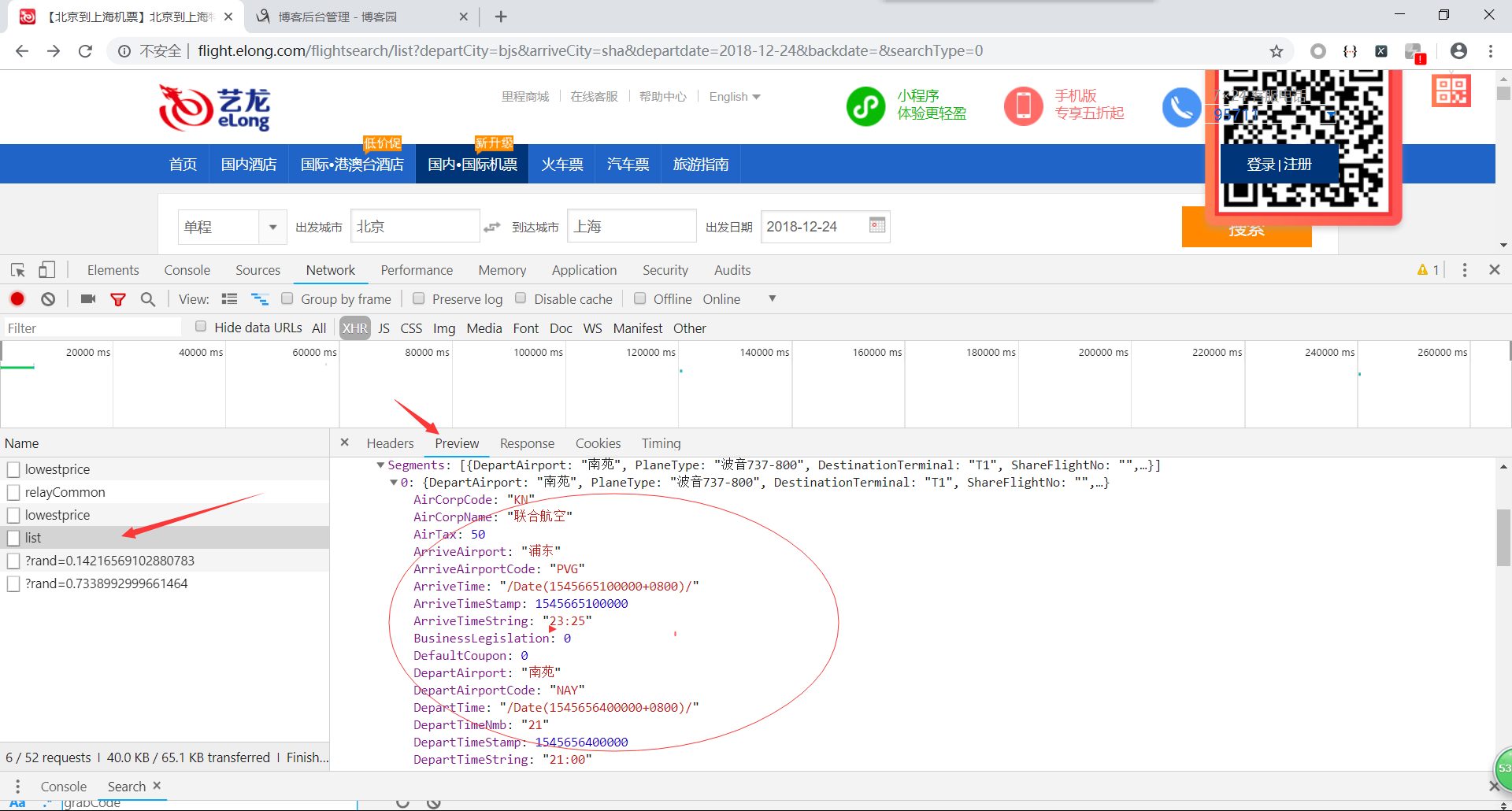
看到出发机场,航空公司名称之类的英文,ok,就是这个了,点击进入Headers。

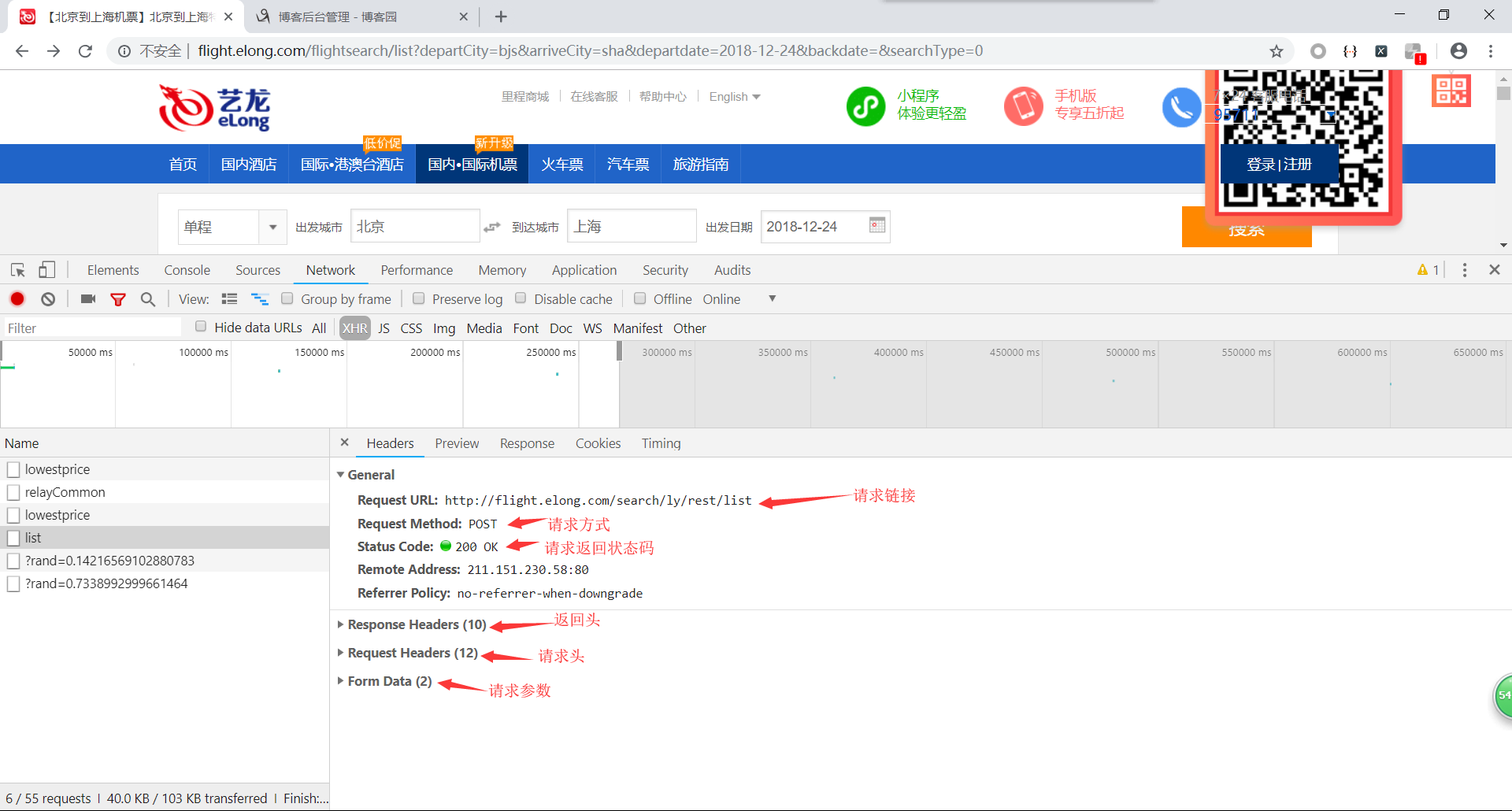
数据来源已经确定,下面我们来构造爬虫请求接口。
2.编写爬虫脚本
快速上手requests模块,链接已备好 http://docs.python-requests.org/zh_CN/latest/user/quickstart.html
直接上代码(提示:代码中的请求参数grabcode的值需要自己抓取,有时效性,过期无返回结果导致代码报错):
import requests #导入requests模块
#请求链接
url = 'http://flight.elong.com/search/ly/rest/list'
#构造请求头 接口中请求头有的参数最好全写上,之后再了解这些请求头信息是干什么的,这里不做介绍
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36',
}
#请求参数
data = {
"p": '{"departCode":"bjs","arriveCityCode":"sha","departDate":"2018-12-24","searchType":"0","classTypes":null,"isBaby":0}',
"grabCode":'',
}
#发起请求
html = requests.post(url, headers=headers,data=data).text
print(html)
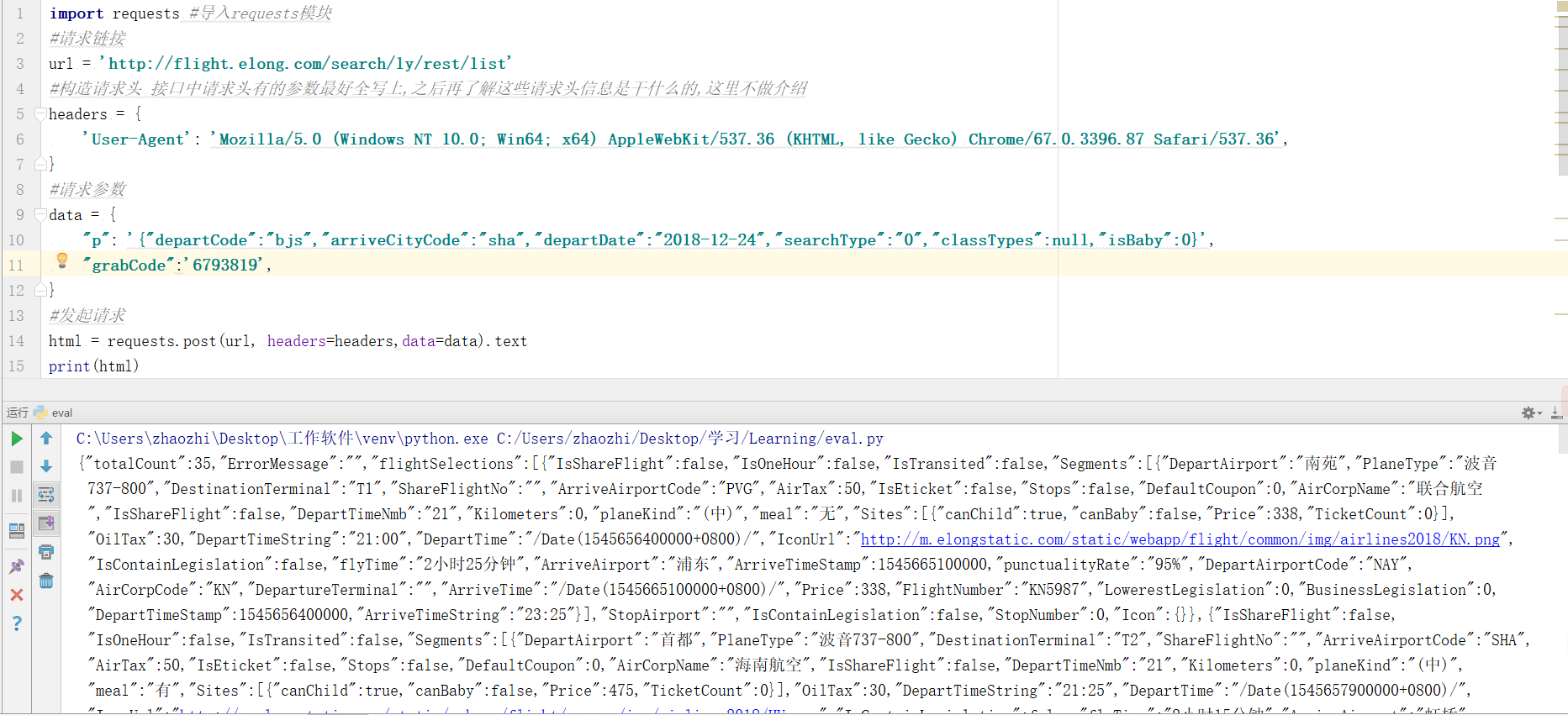
有返回结果并且有数据证明我们请求成功了,但是我们还得进一步验证数据准确性。
3.验证数据是否准确
使用json进一步提取关键数据如航班号,最低价等。
import requests #导入requests模块
import json #导入json
#请求链接
url = 'http://flight.elong.com/search/ly/rest/list'
#构造请求头 接口中请求头有的参数最好全写上,之后再了解这些请求头信息是干什么的,这里不做介绍
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36',
}
#请求参数
data = {
"p": '{"departCode":"bjs","arriveCityCode":"sha","departDate":"2018-12-24","searchType":"0","classTypes":null,"isBaby":0}',
"grabCode":'',
}
#发起请求
html = requests.post(url, headers=headers,data=data).text
#json.loads转化json为一个字典 然后我们可以用字典方法取键和值
html = json.loads(html)["flightSelections"]
#创建结果列表
list = []
for i in html:#遍历所有航班
if len(i["Segments"]) == 1: #只提取单程,多程排除
flightnumber = i["Segments"][0]["FlightNumber"]
price = i["Segments"][0]["Price"]
#航班信息字典
item = {
"flight": flightnumber,
"price": price,
} list.append(item)
print(list)
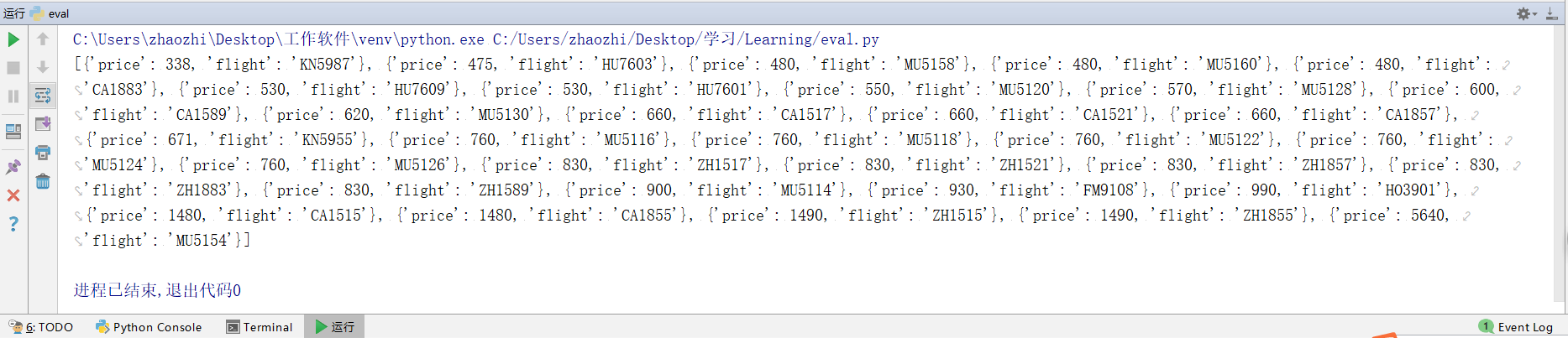
和网页价格对比:

结果正确,证明爬取成功。还没完,上面2,3过程提到grabCode参数的时效性,参数过期会导致接口无返回结果,json解析就会抛出异常。
4.js逆向分析加密请求参数grabCode的生成
接口请求参数中的加密参数都是有迹可循的,前端和后端必须使用相同的加密算法来保证参数的有效性。
后端代码我们不可能看得到,所以就要从前端来分析,前端通过js调用接口,最常见的是jquery库来实现ajax请求。(js原生也可以实现ajax请求)
查找调用接口js位置:
通过关键字grabCode,来查找js调用接口的位置。(这里也可以通过其他方法如请求方式Post来搜索位置)
F12打开开发者工具,使用全局搜索search。
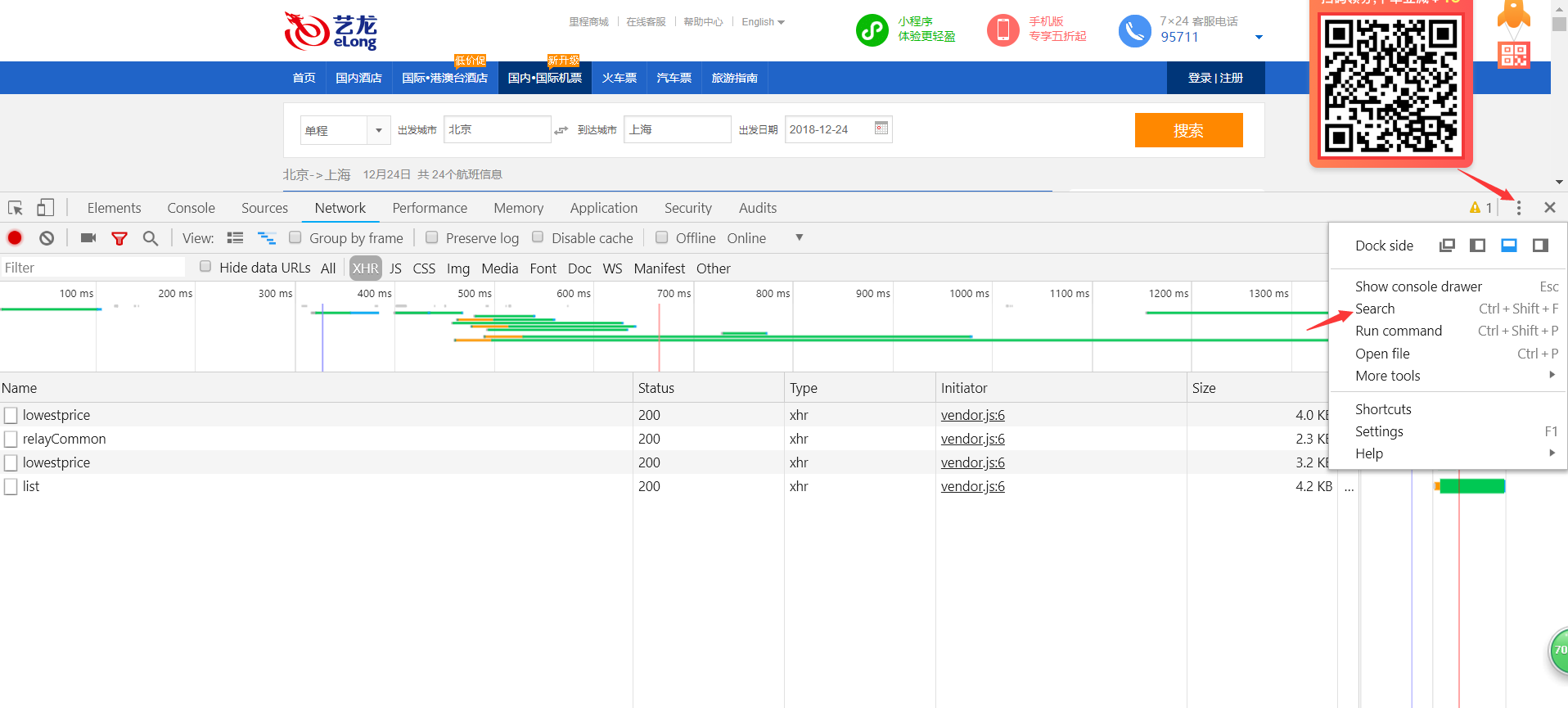
搜索参数名称grabCode
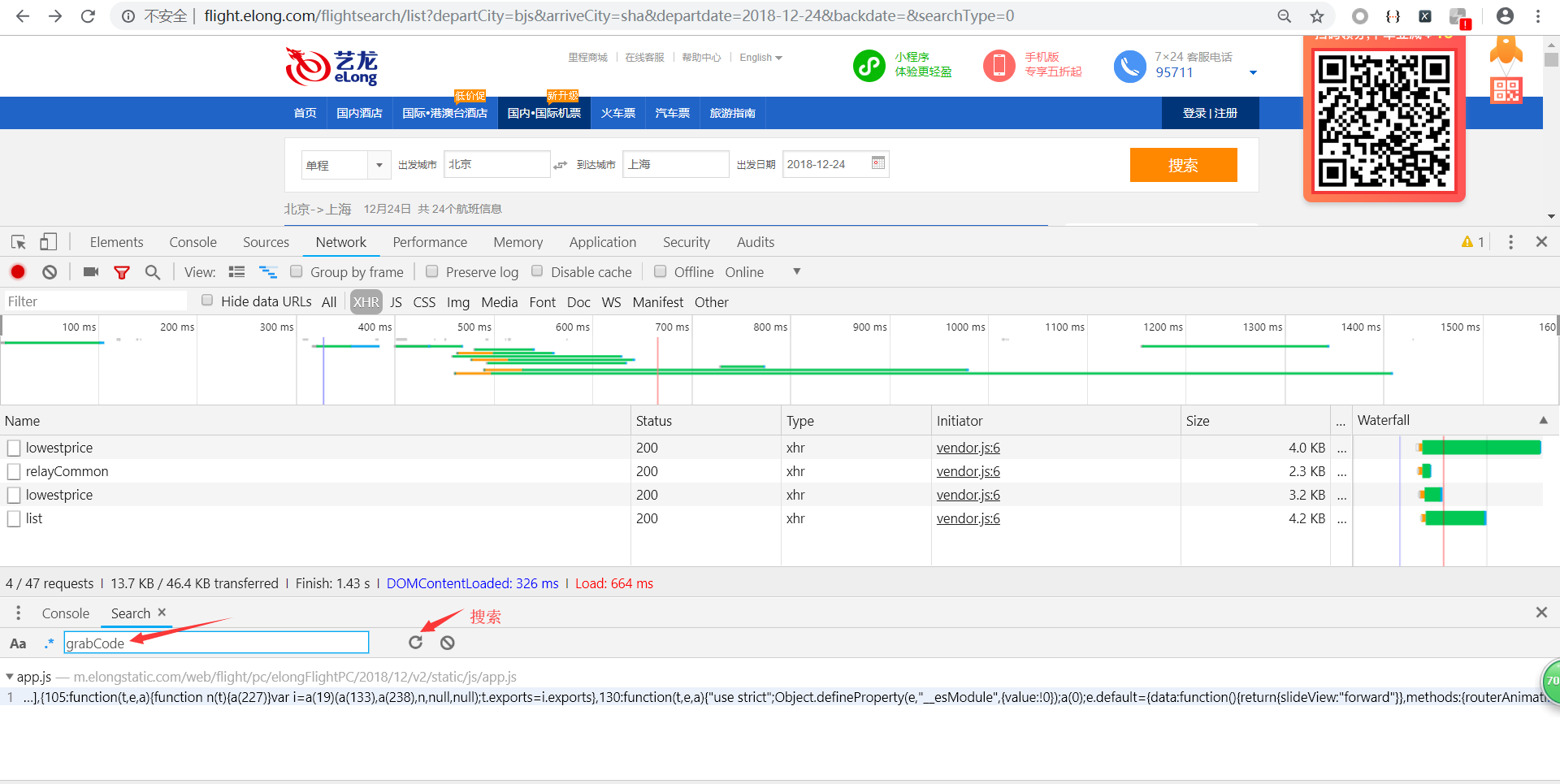
找到了,点击第一个搜索结果,进入查看js,点击左下角的图标格式化js。
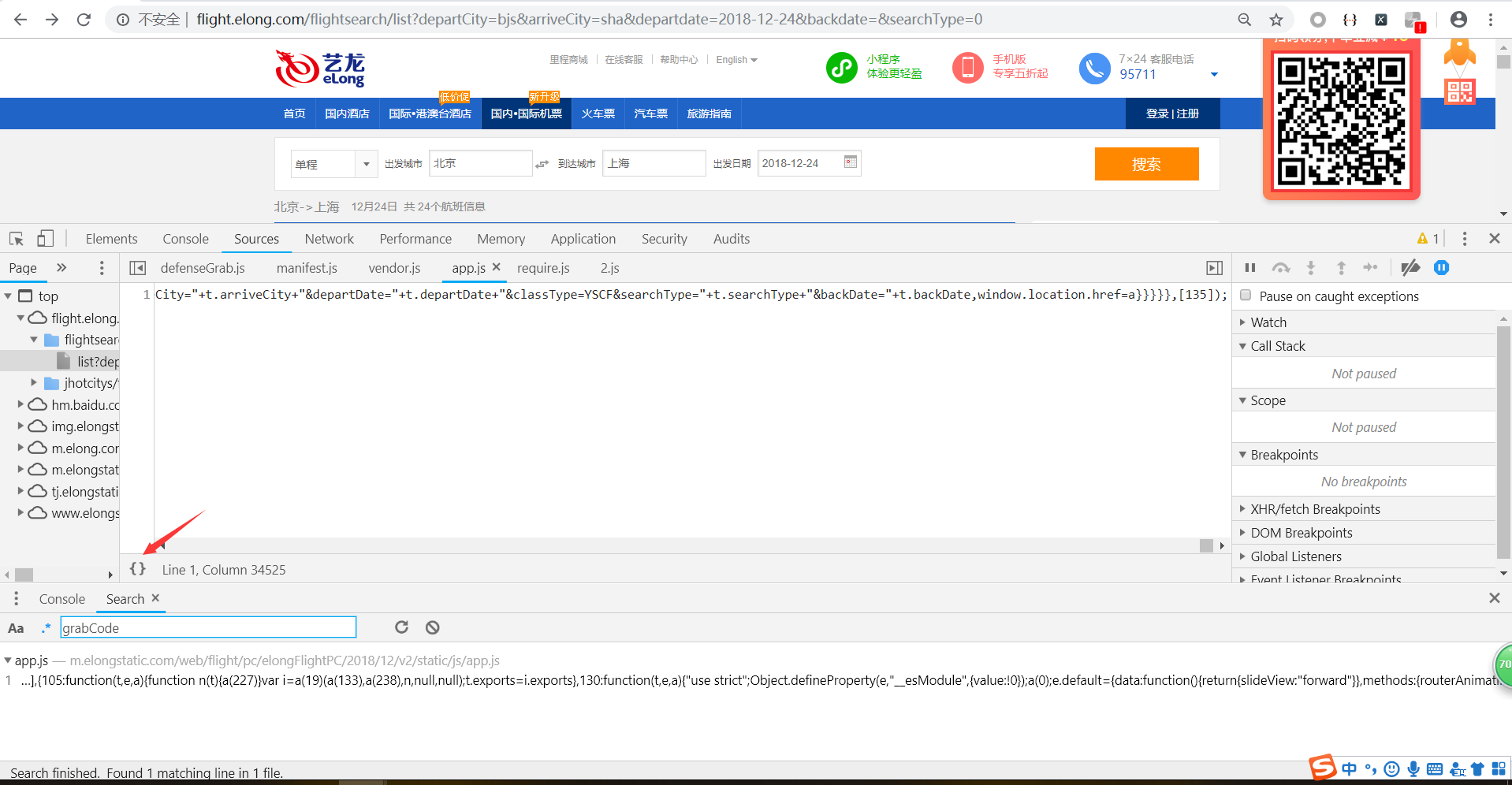
使用ctrl+f搜索grabCode的位置
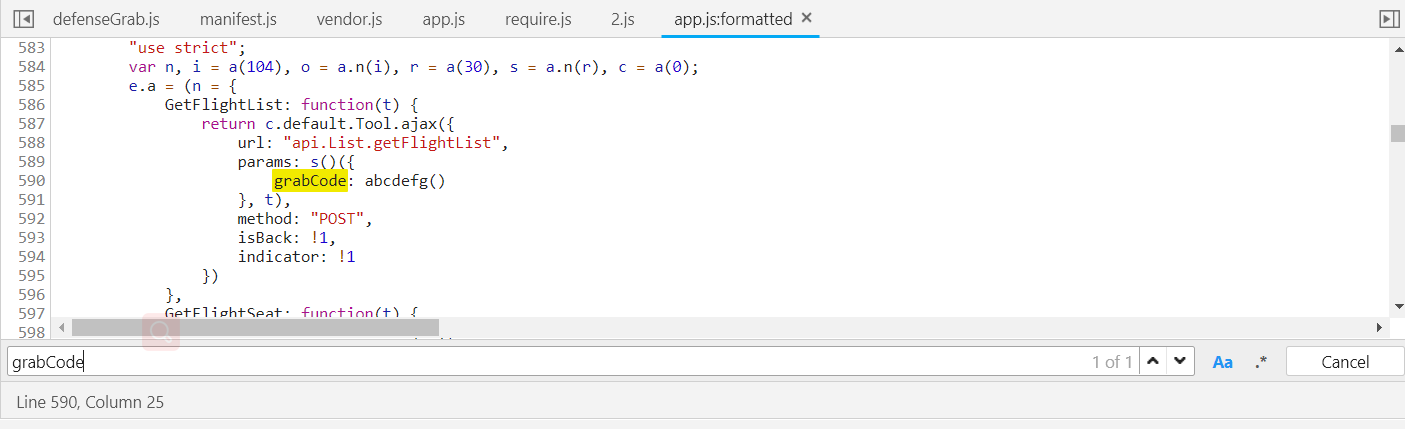
很清晰的可以看到这里就是使用了ajax调用list接口的方法url(接口地址),params(请求参数),methods(请求方式)。
grabCode的值是调用了abcdefg函数。(下面我们可以用js断点调试来获取函数abcdefg的位置,或是按照刚才的方法使用全局搜索来查找也可以,调试更方便一点)
js断点调试:
如图,在grabCode调用方法的行标点击,变成蓝色,表示断点成功,然后刷新页面。

搜索结果正在加载被截断,进一步证实了参数生成就是调用函数abcdefg。
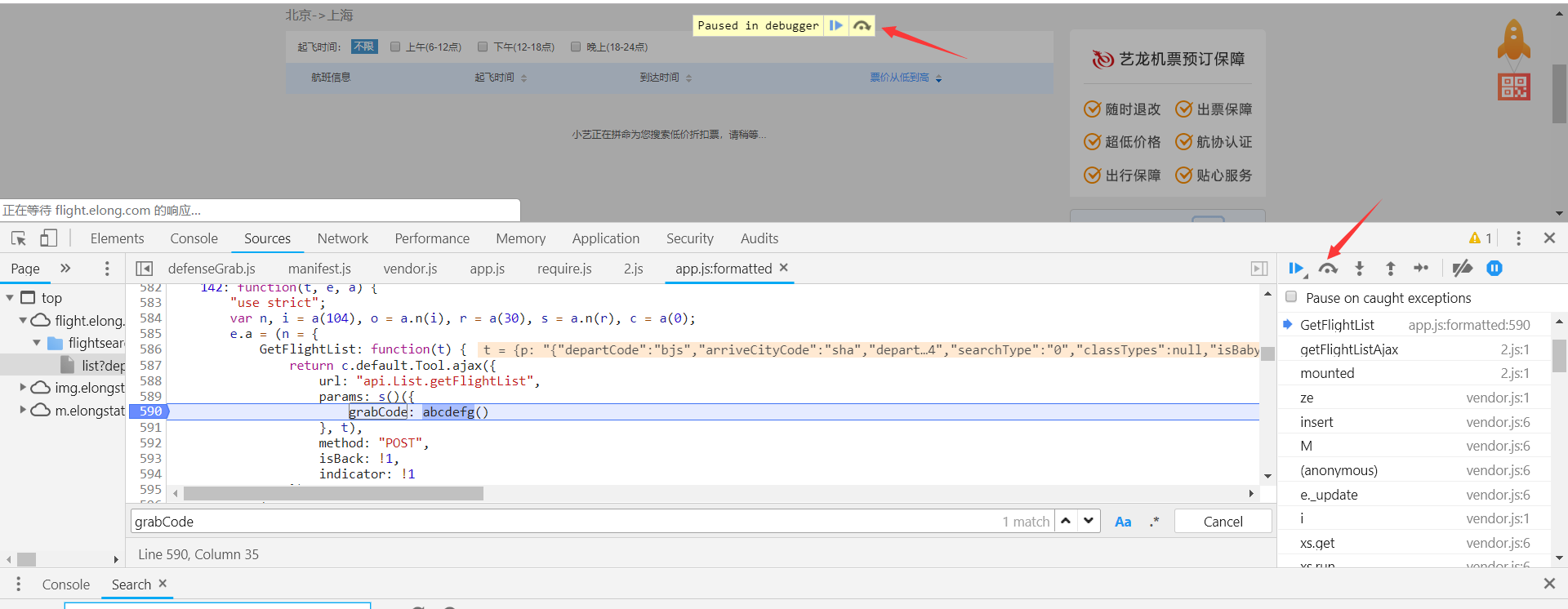
这个小图标的功能叫”逐语句执行“或者叫”逐步执行“,这是我个人理解的一个叫法,意思就是,每点击它一次,js语句就会往后执行一句,它还有一个快捷键,F10。
我们点击一下,发现刚才断点的代码已被执行。鼠标箭头悬停在abcdefg函数上,点击方法可以直接跳过去。
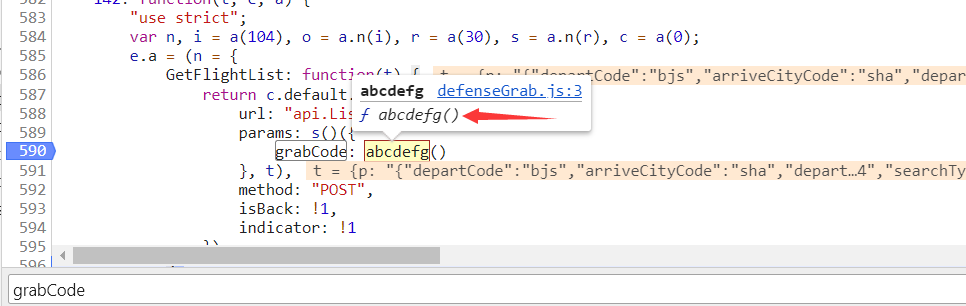
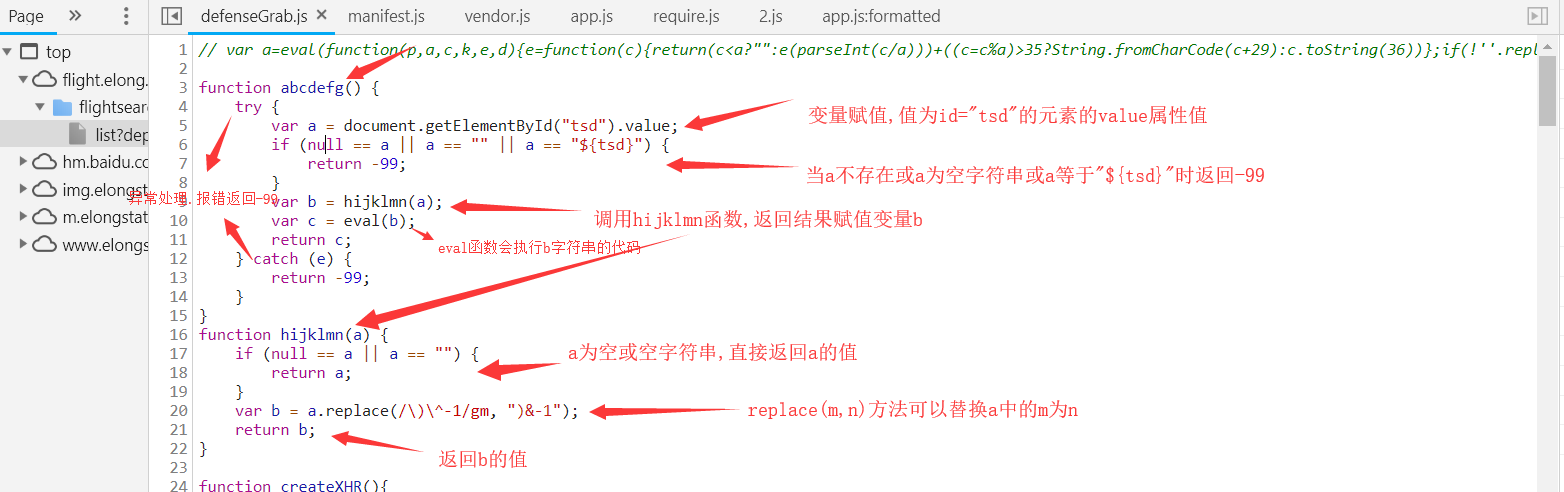
上图对abcdefg函数做了一个解析,了解生成过程,总结一下就是调用网页源代码中的id为tsd的元素的属性值value,替换字符串中的某个值,并调用eval把字符串执行。
取消刚才的断点,在如图所示位置打上新断点,刷新页面。F10执行下一句。
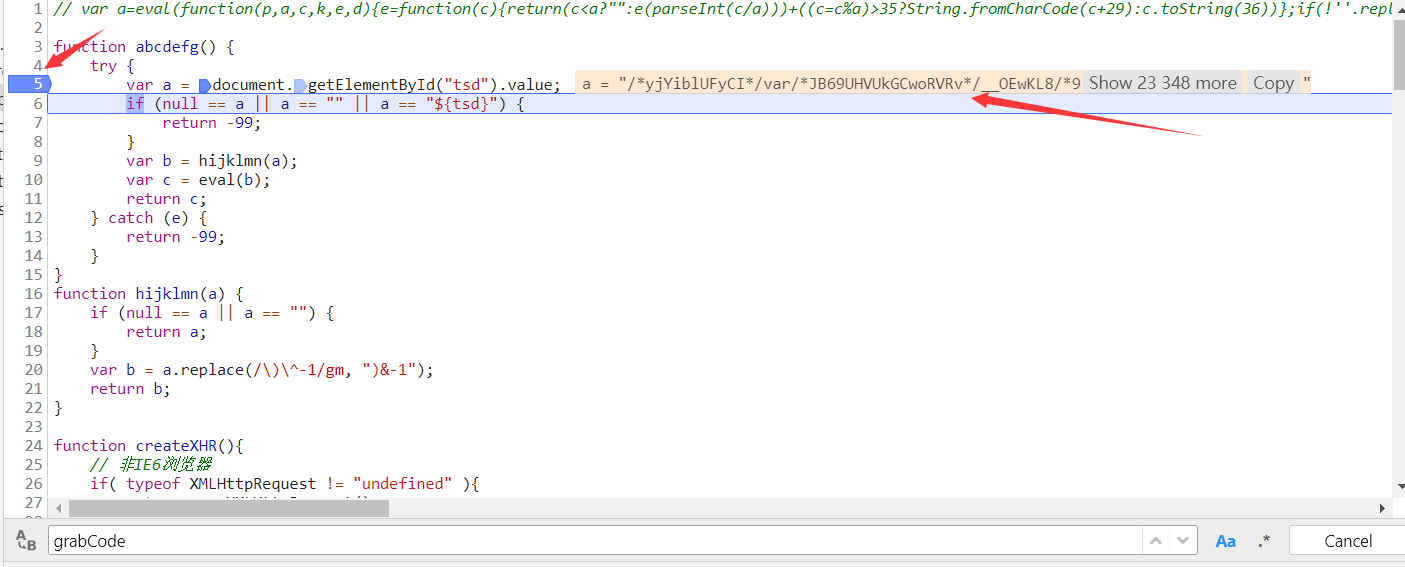
和网页源代码对比一下,ok,正确。
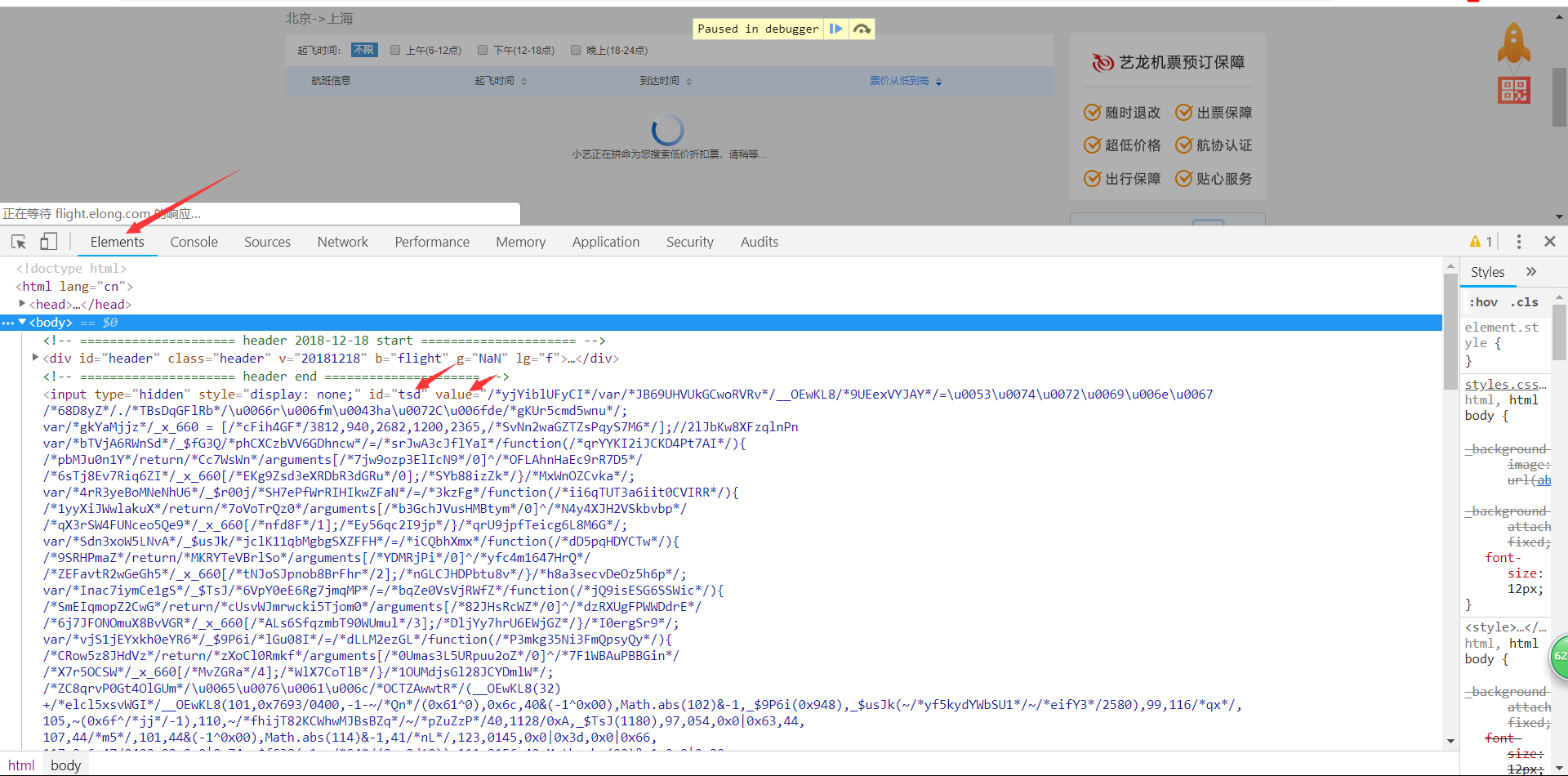
不难看出上面的value值实际为js代码,eval函数会执行这些js代码。
模拟参数生成过程:
我们来使用python模拟一下他的过程:1.获取网页id==“tsd”的属性value的值。2.替换字符使用replace("/\)\^-1/gm", ")&-1")。3.执行js代码。
复制value的值,可以去网页,也可以在js中复制(这里复制出来的格式会有错误,导致js不能执行成功,我们直接去网页抓取好了)。
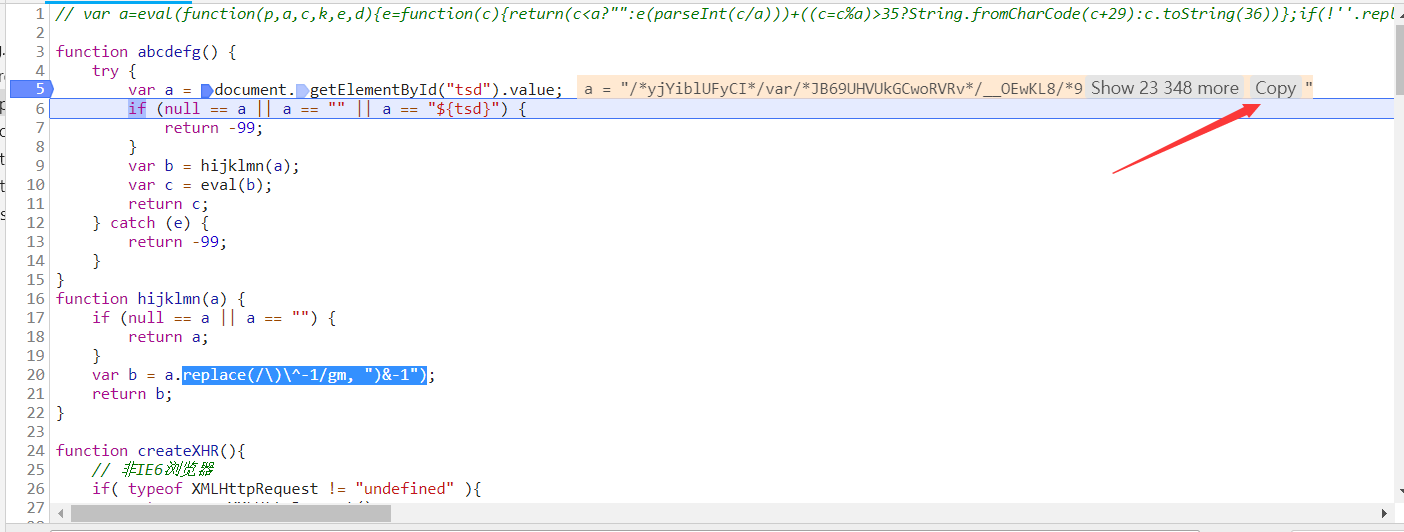
import requests,js2py
from lxml import etree
url_list ='http://flight.elong.com/flightsearch/list?departCity=BJS&arriveCity=SHA&departdate=2018-12-24&backdate=&searchType=0'
html_list = requests.get(url_list).text
html_list = etree.HTML(html_list)
js = html_list.xpath('//input[@id="tsd"]/@value')[0]
js = js.replace("/\)\^-1/gm", ")&-1")
code = js2py.eval_js(js)
print(code)
我们再把这个封装成一个函数来供第二步进行调用,搜索url中的三字码和日期可以用一样的(防止出错)。
更换搜索参数城市三字码或日期测试代码是否能正常运行并返回航班及其价格
下面附上全部代码,仅供参考学习。
import requests #导入requests模块
import json #导入json
import js2py #导入js执行模块
from lxml import etree #xpath使用lxml的etree解析
def ticket_api(a,b,c):
#请求链接
url = 'http://flight.elong.com/search/ly/rest/list'
#构造请求头 接口中请求头有的参数最好全写上,之后再了解这些请求头信息是干什么的,这里不做介绍
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36',
}
#请求参数
data = {
"p": '{"departCode":"%s","arriveCityCode":"%s","departDate":"%s","searchType":"0","classTypes":null,"isBaby":0}'%(a,b,c),
"grabCode":grabCode(a,b,c),
}
#发起请求
html = requests.post(url, headers=headers,data=data).text
#json.loads转化json为一个字典 然后我们可以用字典方法取键和值
html = json.loads(html)["flightSelections"]
#创建结果列表
list = []
for i in html:#遍历所有航班
if len(i["Segments"]) == 1: #只提取单程,多程排除
flightnumber = i["Segments"][0]["FlightNumber"]
price = i["Segments"][0]["Price"]
#航班信息字典
item = {
"flight": flightnumber,
"price": price,
} list.append(item)
print(list) def grabCode(a,b,c):
url_list ='http://flight.elong.com/flightsearch/list?departCity=%s&arriveCity=%s&departdate=%s&backdate=&searchType=0'%(a,b,c)
html_list = requests.get(url_list).text
html_list = etree.HTML(html_list)
js = html_list.xpath('//input[@id="tsd"]/@value')[0]
js = js.replace("/\)\^-1/gm", ")&-1")
code = js2py.eval_js(js)
return code if __name__ == '__main__':
a = "bjs"
b = "czx" #常州czx,上海sha
c = "2018-12-24"
ticket_api(a,b,c)
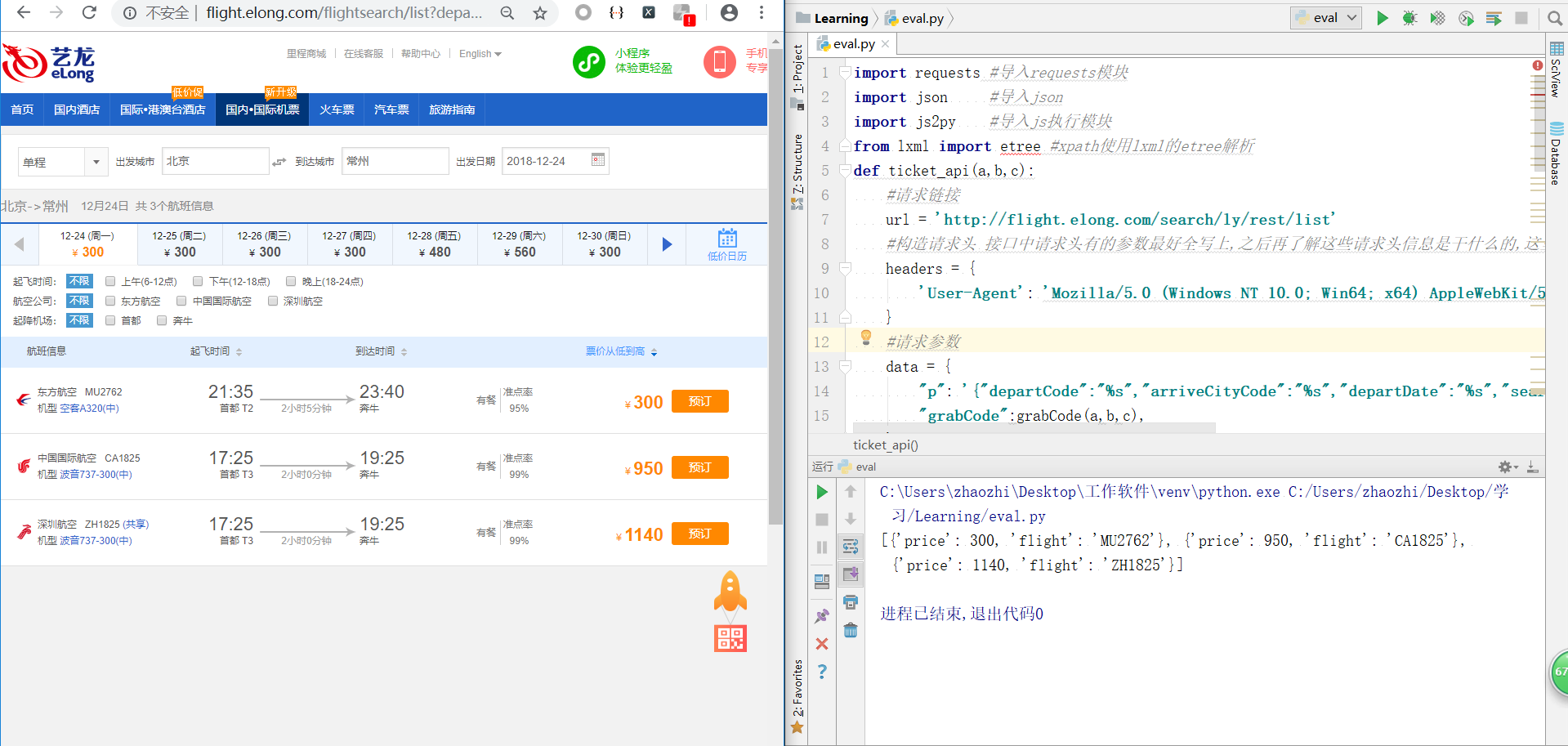
到这一步,基本上算是完成了。
温馨提示
- 如果您对本文有疑问,请在评论部分留言,我会在最短时间回复。
- 如果本文帮助了您,也请评论关注,作为对我的一份鼓励。
- 如果您感觉我写的有问题,也请批评指正,我会尽量修改。
- 本文为原创,转载请注明出处。
- 本文所有代码仅供学习参考,在爬取的同时考虑对方的服务器承受能力,适可而止。
Python3爬虫基础实战篇之机票数据采集的更多相关文章
- javamail模拟邮箱功能发送电子邮件-基础实战篇(javamail API电子邮件实例)
引言: JavaMail 是一种可选的.能用于读取.编写和发送电子消息的包 JavaMail jar包下载地址:http://java.sun.com/products/javamail/downlo ...
- MySQL的初次见面礼基础实战篇
[版权申明] http://blog.csdn.net/javazejian/article/details/61614366 出自[zejian的博客] 关联文章: MySQL的初次见面礼基础实战篇 ...
- Linux Capabilities 入门教程:基础实战篇
该系列文章总共分为三篇: Linux Capabilities 入门教程:概念篇 Linux Capabilities 入门教程:基础实战篇 待续... 上篇文章介绍了 Linux capabilit ...
- Capabilities 入门教程:基础实战篇
该系列文章总共分为三篇: Linux Capabilities 入门教程:概念篇 Linux Capabilities 入门教程:基础实战篇 待续... 上篇文章介绍了 Linux capabilit ...
- python3.0_day9_scoket基础之篇
一.socket简单介绍 socket通常也称作"套接字",用于描述IP地址和端口,是一个通信链的句柄,应用程序通常通过"套接字"向网络发出请求或者应答网络请求 ...
- Python爬虫【实战篇】scrapy 框架爬取某招聘网存入mongodb
创建项目 scrapy startproject zhaoping 创建爬虫 cd zhaoping scrapy genspider hr zhaopingwang.com 目录结构 items.p ...
- python爬虫【实战篇】模拟登录人人网
requests 提供了一个叫做session类,来实现客户端和服务端的会话保持 使用方法 1.实例化一个session对象 2.让session发送get或者post请求 session = req ...
- Python爬虫【实战篇】获取网易云歌词
先看代码 import requests import json headers = { "User-Agent": "Mozilla/5.0 (iPhone; CPU ...
- Python爬虫【实战篇】bilibili视频弹幕提取
两个重要点 1.获取弹幕的url是以 .xml 结尾 2.弹幕url的所需参数在视频url响应的 javascript 中 先看代码 import requests from lxml import ...
随机推荐
- Numpy的进阶学习
前言: 在学习cs231n编写课后作业代码过程中 .发现自己对计算的向量化vectorized不是很懂,编写不出代码.对numpy的库也只是停留在表面 Numpy Numpy学习库链接 1.numpy ...
- STL 中priority_queue小结
(1)为了运用priority_queue,你必须包含头文件<queue>:#include<queue> (2)在头文件中priority_queue定义如下: nam ...
- 牛客网暑期ACM多校训练营(第三场) A PACM Team 01背包 记录路径
链接:https://www.nowcoder.com/acm/contest/141/A来源:牛客网 Eddy was a contestant participating in ACM ICPC ...
- JavaScript数组方法速查,32个数组的常用方法和属性
JavaScript数组方法速查手册极简版 http://30ke.cn/doc/js-array-method JavaScript数组方法速查手册极简版中共收了32个数组的常用方法和属性,并根据方 ...
- sublime,webstrom,vscode的使用感受,以及对于vue和webpack的支持,还有一些快捷键使用心得
从最开始用sublime3到webstrom再到vscode,我的感觉如下: sublime首次加载项目文件速度较快,每次装插件有点麻烦,插件很丰富,也很好用. webstrom首次加载项目文件速度奇 ...
- WordCount--统计输入文件的字符数、行数、单词数(java)--初级功能
码云地址: https://gitee.com/YuRenDaZ/WordCount 个人PSP表格: PSP2.1 PSP阶段 预估耗时 (分钟) 实际耗时 (分钟) Planning 计划 180 ...
- H5实现扫描二维码功能
为了实现H5扫描二维码功能,我在网上找到了可用的代码:https://github.com/zhiqiang21/WebComponent/tree/master/html5-Qrcode 该程序能基 ...
- .net core 自定义404 500页面
常用处理方式 自己定制网站的404.500页面的方式有很多,比如修改nginx配置文件,指定请求返回码对应的页面, .netframework项目中修改webconfig文件,指定customerro ...
- 由于找不到opencv_world***d.dl,无法继续执行代码。重新安装程序可能会解决此问题。关于opencv使用imshow函数闪退解决方法等问题
1.将缺失的文件放到程序根目录的debug中 2.将Debug x64下的附加依赖项改为只有后缀为d.lib的那个库文件,去除另一个,问题就这么解决了,虽然我也不知道加上另一个为什么就会闪退
- 初学FPGA图像处理,开发板选择建议
我用的是ZYNQ7010的开发板,纯粹是入门学习,对于初学者,使用较多的xlinx入门级的开发板一般是zynq7000系列,淘宝上买的较好的是黑金和米联科,我买的就是黑金的,个人觉得教程很少,学习资料 ...