【Java心得总结七】Java容器下——Map
我将容器类库自己平时编程及看书的感受总结成了三篇博文,前两篇分别是:【Java心得总结五】Java容器上——容器初探和【Java心得总结六】Java容器中——Collection,第一篇从宏观整体的角度对Java中强大的容器类库做了一个简单总结而第二篇专门针对容器类库中的Collection部分进行了总结。这篇博文将对容器类库中的Map部分进行一个整理总结。
一、初识Map
Map:一组成对的“键值对”对象,允许你使用键来查找值。(注:Map其实是将键与值形成的二元组按照一维线性的方式组织起来,这里值得注意的是值可以使一个Collection或者Map,即嵌套结构,如:Map<String,Integer>,Map<Integer,List<String>>,Map<String,Map<String>>(注:所有的基本类型在泛型声明中都必须用其对应的包装类型,关于基本类型及泛型请见博文:【Java心得总结一】Java基本类型和包装类型解析和【Java心得总结三】Java泛型上——初识泛型)从另一个角度来考虑Map,其实Map相当于ArrayList或者更简单的数组的一种扩展、推广。在数组中我们可以利用下标即数字访问数组当中的不同元素,那么数字与对象之间形成了一种关联,那么如果将这个数字的概念扩展成为对象,那同样的我们可以将对象与对象之间关联起来。即Map,也称为映射表、关联数组、字典允许我们使用一个对象来查找某个对象。
Map可以说是我们平时编程中用到的最多的类库之一了,它说来与数据库中的数据表有些像,但又不同。我们以一个班级成绩存储的例子来做讨论:如果我们想在程序中存储一个班级每个同学的成绩可以用Map<String,Integer>,String部分用来存学生的姓名,Integer用来存学生的成绩;如果我们想存班级每个同学更多的信息,比如不止一门课的成绩,那么我们可以这么用Map<String,List<Integer>>;又如果我们存的每个同学的信息想更完整些比如同学A的语文95、数学98、英语100,那么我们可以这么声明Map<String,Map<String,Integer>>。下面是代码示例:
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map; public class Main {
public static void main(String args[]) {
// 首先声明一个Map,录入每个同学的一门课成绩
Map<String, Integer> oneGrade = new HashMap<String, Integer>();
oneGrade.put("小明", 98);
oneGrade.put("小红", 95);
System.out.println("Map<string,Integer>: ");
System.out.println(oneGrade); // 其次我们想给每个同学录入更多的成绩
Map<String, List<Integer>> manyGrades = new HashMap<String, List<Integer>>();
// 录入小明的几科成绩
List<Integer> tmp = new ArrayList<Integer>();
tmp.add(98);
tmp.add(96);
tmp.add(93);
manyGrades.put("小明", tmp);
// 录入小红的几科成绩
tmp.clear();
tmp.add(95);
tmp.add(99);
tmp.add(100);
manyGrades.put("小红", tmp);
System.out.println("Map<String,List<Integer>>: ");
System.out.println(manyGrades); // 再次我们想保留每个同学究竟哪门课的了多少分的具体信息
Map<String, Map<String, Integer>> detailGrades = new HashMap<String, Map<String, Integer>>();
//录入小明的具体每门课程的成绩
Map<String,Integer> tmp1 = new HashMap<String, Integer>();
tmp1.put("语文", 98);
tmp1.put("数学", 96);
tmp1.put("英语", 93);
detailGrades.put("小明", tmp1);
//录入小红的具体每门课的成绩
tmp1.clear();
tmp1.put("语文", 95);
tmp1.put("数学", 99);
tmp1.put("英语", 100);
detailGrades.put("小红", tmp1);
System.out.println("Map<String,Map<String,Integer>>: ");
System.out.println(detailGrades);
}
}/* Output:
Map<string,Integer>:
{小明=98, 小红=95}
Map<String,List<Integer>>:
{小明=[95, 99, 100], 小红=[95, 99, 100]}
Map<String,Map<String,Integer>>:
{小明={语文=95, 英语=100, 数学=99}, 小红={语文=95, 英语=100, 数学=99}}
*///:~
上面的代码非常的简单,值得注意的是
1.如果我们在Map中嵌套了List或者Map那么我们向Map中put数据的时候要先new一个List或者Map(关于List见博文:【Java心得总结六】Java容器中——Collection);
2.我们使用了Map中的库函数clear(),即清空整个Map中的数据,关于Map的API我就不再赘述,官网相当详细;
3.在输出的时候,大家看到我只是直接将Map的引用给了打印函数,可以看到输出的结果会以{key1=value1,key2=value2...}的形式给出;
4.在Map声明时,我们用Map接口持有了HashMap的引用,关于Map接口的不同实现我们将在下面讨论。
二、Map接口的不同实现
先上图,Map的架构图:
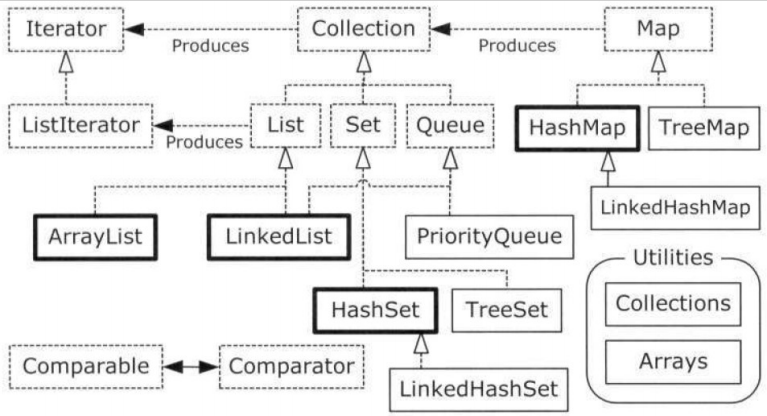
Map结构图
——摘自 《Thinking in java》第17章图
从图中我们可以清晰的看到Map接口的具体实现有三个HashMap,TreeMap和LinkedHashMap(Map接口还有WeakHashMap、ConcurrentHashMap、IdentityHashMap等实现,在多线程编程中会用到ConrrentHashMap,另外两个转为特殊问题设计不常用就暂不总结了):
- HashMap:Map基于散列表的实现(它取代了Hashtable)。插入和查询键值对的开销是固定的。可以通过构造器设置容量和负载因子,以调整容器的性能。
- LinkedHashMap:类似于HashMap,但是迭代遍历它时,取得“键值对”的顺序是其插入次序,或者是最近最少使用(LRU)的次序。只比HashMap慢一点;而在迭代访问时反而更快,因为它使用链表维护内部次序。
- TreeMap:基于红黑树的实现。查看“键”或“键值树”时,它们会被排序(次序由Comparable或Comparator决定)。TreeMap的特点在于,所得到的结果是经过排序的。TreeMap是唯一的带有subMap()方法的Map,它可以返回一个子树。
- ConcurrentHashMap:一种线程安全的Map,它不涉及同步加锁。(以后自己在多线程编程方面有了总结再来讨论)
下面是一个经典的代码示例,展示了这几种不同Map实现的特点:
//: containers/Maps.java
// Things you can do with Maps.
import java.util.concurrent.*;
import java.util.*; public class Maps {
public static void printKeys(Map<Integer, String> map) {
System.out.print("Size = " + map.size() + ", ");
System.out.print("Keys: ");
System.out.println(map.keySet()); // 产生一个键的集合
} public static void test(Map<Integer, String> map) {
System.out.println(map.getClass().getSimpleName());
// 用来作为测试数据
Map<Integer, String> testData = new HashMap<Integer, String>();
testData.put(3, "A0");
testData.put(2, "B1");
testData.put(9, "A4");
testData.put(1, "C2");
testData.put(8, "D1");
map.putAll(testData);
// Map有Set的特性,keys键值是不能重复的
map.putAll(testData);
printKeys(map);
// 产生值的一个集合
System.out.print("Values: ");
System.out.println(map.values());
System.out.println(map);
System.out.println("map.containsKey(11): " + map.containsKey(11));
System.out.println("map.get(11): " + map.get(11));
System.out.println("map.containsKey(9): " + map.containsKey(9));
System.out.println("map.get(9): " + map.get(9));
System.out.println("map.containsValue(\"F0\"): "
+ map.containsValue("F0"));
Integer key = map.keySet().iterator().next();
System.out.println("First key in map: " + key);
map.remove(key);
printKeys(map);
map.clear();
System.out.println("map.isEmpty(): " + map.isEmpty());
map.putAll(testData);
// Operations on the Set change the Map:
map.keySet().removeAll(map.keySet());
System.out.println("map.isEmpty(): " + map.isEmpty());
} public static void main(String[] args) {
test(new HashMap<Integer, String>());
test(new TreeMap<Integer, String>());
test(new LinkedHashMap<Integer, String>());
test(new IdentityHashMap<Integer, String>());
test(new ConcurrentHashMap<Integer, String>());
test(new WeakHashMap<Integer, String>());
}
}/* Output:
HashMap
Size = 5, Keys: [1, 2, 3, 8, 9]
Values: [C2, B1, A0, D1, A4]
{1=C2, 2=B1, 3=A0, 8=D1, 9=A4}
map.containsKey(11): false
map.get(11): null
map.containsKey(9): true
map.get(9): A4
map.containsValue("F0"): false
First key in map: 1
Size = 4, Keys: [2, 3, 8, 9]
map.isEmpty(): true
map.isEmpty(): true
TreeMap
Size = 5, Keys: [1, 2, 3, 8, 9]
Values: [C2, B1, A0, D1, A4]
{1=C2, 2=B1, 3=A0, 8=D1, 9=A4}
map.containsKey(11): false
map.get(11): null
map.containsKey(9): true
map.get(9): A4
map.containsValue("F0"): false
First key in map: 1
Size = 4, Keys: [2, 3, 8, 9]
map.isEmpty(): true
map.isEmpty(): true
LinkedHashMap
Size = 5, Keys: [1, 2, 3, 8, 9]
Values: [C2, B1, A0, D1, A4]
{1=C2, 2=B1, 3=A0, 8=D1, 9=A4}
map.containsKey(11): false
map.get(11): null
map.containsKey(9): true
map.get(9): A4
map.containsValue("F0"): false
First key in map: 1
Size = 4, Keys: [2, 3, 8, 9]
map.isEmpty(): true
map.isEmpty(): true
IdentityHashMap
Size = 5, Keys: [2, 9, 8, 3, 1]
Values: [B1, A4, D1, A0, C2]
{2=B1, 9=A4, 8=D1, 3=A0, 1=C2}
map.containsKey(11): false
map.get(11): null
map.containsKey(9): true
map.get(9): A4
map.containsValue("F0"): false
First key in map: 2
Size = 4, Keys: [9, 8, 3, 1]
map.isEmpty(): true
map.isEmpty(): true
ConcurrentHashMap
Size = 5, Keys: [8, 2, 9, 1, 3]
Values: [D1, B1, A4, C2, A0]
{8=D1, 2=B1, 9=A4, 1=C2, 3=A0}
map.containsKey(11): false
map.get(11): null
map.containsKey(9): true
map.get(9): A4
map.containsValue("F0"): false
First key in map: 8
Size = 4, Keys: [2, 9, 1, 3]
map.isEmpty(): true
map.isEmpty(): true
WeakHashMap
Size = 5, Keys: [9, 8, 3, 2, 1]
Values: [A4, D1, A0, B1, C2]
{9=A4, 8=D1, 3=A0, 2=B1, 1=C2}
map.containsKey(11): false
map.get(11): null
map.containsKey(9): true
map.get(9): A4
map.containsValue("F0"): false
First key in map: 9
Size = 4, Keys: [8, 3, 2, 1]
map.isEmpty(): true
map.isEmpty(): true
*///:~
代码很详尽的展示了各个Map实现的特点与功能,输出非常的长,所以我折叠了起来(其中包括了WeakHashMap、ConcurrentHashMap、IdentityHashMap,大家可以看到它们所产生的独特效果,ConcurrentHashMap在这里体现不出来,要在多线程编程中才能体会)。
三、Map的遍历
我们在【Java心得总结五】Java容器上——容器初探介绍过foreach和迭代器,只要实现了Iterable接口的类都能够使用foreach语句进行迭代,Map的遍历当然也需要用到它们。请看下面的一段代码:
import java.util.Map.Entry;
public class EnvironmentVariables {
public static void main(String[] args) {
for (Entry entry : System.getenv().entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}
}
}
代码非常简单,就是打印我们操作系统当中的环境变量,其中System.getenv()会返回一个Map,这个Map里存放的内容就是我们系统的环境变量如我们Java的环境变量java_home: C:\Program Files\Java\jdk1.7.0_11,key值就是java_home,value就是它的路径。而Map的entrySet方法会返回一个Set<Entry>,Set实现了Iterable接口,所以我们可以利用foreach对其进行遍历。
特别说明——Entry:大家可以把这个理解为一个结点或者说一个元组更贴切,Map从宏观的角度有key和value,当然了这里value可以使任何Java中的对象,那么Entry相当于(key,entry)这个元组,把它当作一个整体来看,那么我们调用getKey()就会得到当前元组的key值,同样的调用getValue()就会得到当前元组的value值。
四、散列码
上面我们说了很多也看到了Map的强大功能,但是细心的话一定会发现所有我们声明的Map其中存储的都是Java标准类库中的类,像String、Integer,这里会让我们忽略了某些东西,倘若我们想用Map存储自定义类会发生什么?
1)自定义类作为Map的Value:
import java.util.HashMap;
import java.util.Map; class MyClass {
private static int counter = 0;
private int id; public MyClass() {
id = ++counter;
} @Override
public String toString() {
return "自定义类" + id;
}
} public class TestMap {
public static void main(String[] args) {
Map<String, MyClass> testValue = new HashMap<String, MyClass>();
MyClass mc1 = new MyClass();
MyClass mc2 = new MyClass();
testValue.put("NO.1", mc1);
testValue.put("NO.2", mc2);
System.out.println(testValue);
}
}/*
{NO.1=自定义类1, NO.2=自定义类2}
*//:~
我声明了一个MyClass,它给每一个对象会自动分配一个id,并且重载了toString()。在Map中key我用了String,value我用了我们自定义的类,大家会发现毫无问题,轻轻松松就打印出了我们期望得到的结果。难道事情就是这样简单?那么我们再来将自定义类作为key来试试
2)自定义类作为Map的Key(MyClass不变):
public class TestMap {
public static void main(String[] args) {
Map<MyClass, String> testKey = new HashMap<MyClass, String>();
MyClass mc1 = new MyClass();
MyClass mc2 = new MyClass();
testKey.put(mc1, "NO.1");
testKey.put(mc2, "NO.2");
System.out.println(testKey);
// equal()
mc1 = new MyClass();
mc1.id = 1;
testKey.put(mc1, "NO.3");
System.out.println(testKey);
System.out.println("***********");
// hashcode()
mc1 = new MyClass();
mc1.id = 1;
System.out.println(mc1);
System.out.println(testKey);
System.out.println(testKey.containsKey(mc1));
}
}/*
{自定义类1=NO.1, 自定义类2=NO.2}
{自定义类1=NO.1, 自定义类2=NO.2, 自定义类1=NO.3}
***********
自定义类1
{自定义类1=NO.1, 自定义类2=NO.2, 自定义类1=NO.3}
false
*///:~
不知看完代码以及其输出结果后,是否发现了一些问题。
1.我们在前面讨论过Map在key上具有Set的性质,即Map中Key值是不能重复但是在代码26行我们会惊奇的发现运行结果竟然出现了两个相同的key但是有不同的value;
2.在代码18行我将mc1重新new了下,但是我将它的id又设为了1,mc1还是自定义类1,那么testKey中应该有的(而且还有两个!-_-),但是containKey返回的却是false。
要解答这些问题就要引出一个很重要的概念散列码:
1)什么是散列码?
不必用冗长的线性搜索技术来查找一个键,而是用一个特殊的值,名为“散列码”。散列码可以获取对象中的信息,然后将其转换成那个对象“相对唯一”的整数(int)。这是我从百度百科copy来的一段定义。
相信大家对散列表(或说哈希表)都有了解,我也将维基百科的链接放了上来大家可以去看下。其中有一个散列函数(即哈希函数),而散列函数产生的值就是散列码。
2)为什么需要散列码
大家都知道散列表,散列表能够是我们以O(1)的代价进行查询,那么散列函数的作用就是使每一个对象产生一个散列码,这个散列码将用来映射到内存地址空间,这样在进行查询时就能使得复杂度达到O(1),这其实就是哈希表的知识。
hashCode()和equals()
观察Java的源代码我们很容易发现Object基类中有两个函数hashCode()和equals()。hashCode()就像是哈希函数,用来产生散列码,而equals()函数Map会用来判断当前的键是否与表中存在的键相同。
这就解释了我们上面两个问题,由于Java中所有的类都继承自Object基类,上面两个类也不例外,而在Object中默认是将对象的地址作为散列码的,这就导致了我们重新new了mc1后,虽然新的mc1所有数据与原mc1一模一样,但是两者的地址不同,所以我们在containKey中找不到mc1的原因了;而同样的equals()函数也继承自Object,默认的equals()函数比较的是两个对象的地址,而代码中虽然前后put到Map中的mc1是完全相同的,但是两者地址不同,这就造成了同样的MyClass对象mc1在Map中出现了两次。
在写equals函数时必须满足下列5个条件:
- 自反性。对任意x,x.equals(x)一定返回true
- 对称性。对任意x和y,如果y.equals(x)返回true,则x.equals(y)也返回true。
- 传递性。对任意x、y、z,如果有x.equals(y)返回true,y.equals(z)返回true,则x.equals(z)一定返回true。
- 一致性。对任意x和y,如果对象中用于等价比较的信息没有改变,那么无论调用x.equals(y)多少次,返回的结果应该保持一致。
- 对任何不是null的x,x.equals(null)一定返回false。
下面我们对上面的代码进行修改,让它达到我们想要的效果:
import java.util.HashMap;
import java.util.Map; class MyClass {
private static int counter = 0;
public int id; public MyClass() {
id = ++counter;
} @Override
public String toString() {
return "自定义类" + id;
} @Override
public boolean equals(Object obj) {
return this.id == ((MyClass) obj).id;
} @Override
public int hashCode() {
return id;
}
} public class TestMap {
public static void main(String[] args) {
Map<MyClass, String> testKey = new HashMap<MyClass, String>();
MyClass mc1 = new MyClass();
MyClass mc2 = new MyClass();
testKey.put(mc1, "NO.1");
testKey.put(mc2, "NO.2");
System.out.println(testKey); // equal()
mc1 = new MyClass();
mc1.id = 1;
testKey.put(mc1, "NO.3");
System.out.println(testKey);
System.out.println("***********"); // hashcode()
mc1 = new MyClass();
mc1.id = 1;
System.out.println(mc1);
System.out.println(testKey);
System.out.println(testKey.containsKey(mc1));
}
}/*
{自定义类1=NO.1, 自定义类2=NO.2}
{自定义类1=NO.3, 自定义类2=NO.2}
***********
自定义类1
{自定义类1=NO.3, 自定义类2=NO.2}
true
*///:~
我在MyClass中重载了hashCode()和equals()方法,为了简单我就直接使用了id作为比较和散列码,这样结果就达到了我们预期的效果。
其实散列函数的选择还是比较复杂的,因为散列表中我们要尽可能少的造成冲突,这里我们就是针对特定情况采取了特殊的散列函数选取。从我平时编程的角度而言,将自定义类作为key值的情况还是比较少的,如果真的需要用到,在选取散列函数方面一定要考虑周全,要在简单和性能速度方面做出权衡。
五、Comparable接口
还是上面那个例子,我们如果想要MyClass以id的大小顺序而存储,那么就需要用到TreeMap,我们来试验下:
import java.util.Map;
import java.util.TreeMap; class MyClass {
private static int counter = 0;
public int id; public MyClass() {
id = ++counter;
} @Override
public String toString() {
return "自定义类" + id;
} @Override
public boolean equals(Object obj) {
return this.id == ((MyClass) obj).id;
} @Override
public int hashCode() {
return id;
}
} public class TestMap {
public static void main(String[] args) {
Map<MyClass, String> testTreeMap = new TreeMap<MyClass, String>();
MyClass mc1 = new MyClass();
MyClass mc2 = new MyClass();
MyClass mc3 = new MyClass();
testTreeMap.put(mc1, "NO.1");
testTreeMap.put(mc3, "NO.3");
testTreeMap.put(mc2, "NO.2");
System.out.println(testTreeMap);
}
}/*
Exception in thread "main" java.lang.ClassCastException: MyClass cannot be cast to java.lang.Comparable
at java.util.TreeMap.compare(TreeMap.java:1188)
at java.util.TreeMap.put(TreeMap.java:531)
at TestMap.main(TestMap.java:34)
*///:~
我们会发现当我们使用TreeMap的时候编译虽然通过了,但是在运行的时候编译器返回了一个错误,意思就是MyClass不能强制转换成Comparable,那么就要问Comparable是什么?
1)什么是Comarable接口
Comparable是一个接口,它包含一个compareTo()方法用于比较两个对象之间的大小关系(这里用大小有点不恰当,可能用前后关系更确切些),这个函数的规则是如果两个对象相等则返回0,而如果不相等则要看是从大到小排序还是从小到大排序来分,简单的说就是小于返回-1,大于返回1。具体看代码示例一下就明白了。
2)为什么要使用Comarable接口
相信学习过C语言的朋友都会知道函数指针的一个概念,当我们在写一个对数组进行排序的函数的时候,将数组传入的同时,我们可以传入一个函数指针,让排序结果按照我们期望的来,比如或者从大到小或者从小到大。
同样的TreeMap底层是使用红黑树实现的,那么它要将Map按照Key的值进行排序,那么排序的规则就要由实现Comarable接口中的compareTo函数提供。
下面看下我们修改完成的代码:
import java.util.Map;
import java.util.TreeMap; class MyClass implements Comparable<MyClass> {
private static int counter = 0;
public int id; public MyClass() {
id = ++counter;
} @Override
public String toString() {
return "自定义类" + id;
} @Override
public boolean equals(Object obj) {
return this.id == ((MyClass) obj).id;
} @Override
public int hashCode() {
return id;
} @Override
public int compareTo(MyClass o) {
return (this.id == o.id ? 0 : (this.id < o.id ? -1 : 1));
}
} public class TestMap {
public static void main(String[] args) {
Map<MyClass, String> testTreeMap = new TreeMap<MyClass, String>();
MyClass mc1 = new MyClass();
MyClass mc2 = new MyClass();
MyClass mc3 = new MyClass();
testTreeMap.put(mc1, "NO.1");
testTreeMap.put(mc3, "NO.3");
testTreeMap.put(mc2, "NO.2");
System.out.println(testTreeMap);
}
}/*
{自定义类1=NO.1, 自定义类2=NO.2, 自定义类3=NO.3}
*///:~
大家可以看到程序正常运行了,这里我让MyClass对象按照id从小到大的顺序进行了排序。
其实Comparable接口在出现了两个对象进行比较的情况的时候都会用到,还有一个很常用的地方就是List排序中也会用到。
六、总结
关于Map总结两句话:
- HashMap设计用来快速访问;而TreeMap保持“键”始终处于排序状态,所以没有HashMap快。LinkedHashMap保持元素插入的顺序,但是也通过散列提供了快速访问的能力。
- 在Map中任何作为键的对象都必须具有一个equals()方法;如果键被用于散列Map,那么它必须还具有恰当的hashCode()方法;如果键被用于TreeMap,那么它还必须实现Comparable接口。
到这里Java中容器类库的一些基础东西就全在三篇博文中涵盖了,如果有我在博文中描述有问题的地方还请指正。
另外附上另外两篇博文的地址:
【Java心得总结六】Java容器中——Collection
【Java心得总结七】Java容器下——Map的更多相关文章
- Java学习笔记七:Java的流程控制语句之switch
Java条件语句之 switch 当需要对选项进行等值判断时,使用 switch 语句更加简洁明了.例如:根据考试分数,给予前四名不同的奖品.第一名,奖励笔记本一台:第二名,奖励 IPAD 2 一个: ...
- 菜鸡的Java笔记 第七 - java 数组
数组的基本概念 笔试中经常出现的试题或是问题 1.1 概念 数组指的是一组相关变量的集合 如果用最原始的方式定义100个变量的话没问题但是这些变量的关联实在 ...
- Java 学习笔记 (七) Java 参数
head first java page 74 实参: argument 形参: parameter 方法会运用形参, 调用的一方会传入实参. 实参是传给方法的值.当它传入方法后就成了形参, 参数跟局 ...
- 【Java心得总结六】Java容器中——Collection
在[Java心得总结五]Java容器上——容器初探这篇博文中,我对Java容器类库从一个整体的偏向于宏观的角度初步认识了Java容器类库.而在这篇博文中,我想着重对容器类库中的Collection容器 ...
- 【Java心得总结五】Java容器上——容器初探
在数学中我们有集合的概念,所谓的一个集合,就是将数个对象归类而分成为一个或数个形态各异的大小整体. 一般来讲,集合是具有某种特性的事物的整体,或是一些确认对象的汇集.构成集合的事物或对象称作元素或是成 ...
- Java入门记(五):容器关系的梳理(下)——Map
注意:阅读本文及相关源码时,需要数据结构相关知识,包括:哈希表.链表.红黑树. Map是将键(key)映射到值(value)的对象.不同的映射不能包含相同的键:每个键最多只能映射到一个值.下图是常见M ...
- Java基础知识二次学习--第七章 容器
第七章 容器 时间:2017年4月27日15:08:30 章节:07章01节~07章04节 视频长度:20:21 +12:38 +3:55 +2:57 内容:容器API 心得: Java API ...
- 【Java心得总结四】Java泛型下——万恶的擦除
一.万恶的擦除 我在自己总结的[Java心得总结三]Java泛型上——初识泛型这篇博文中提到了Java中对泛型擦除的问题,考虑下面代码: import java.util.*; public clas ...
- JAVA的容器---List,Map,Set (转)
JAVA的容器---List,Map,Set Collection├List│├LinkedList│├ArrayList│└Vector│ └Stack└SetMap├Hashtable├HashM ...
随机推荐
- 常用的一些复杂SQL语句
1.根据表中的birthday统计年龄段人数: //以下代码表示查询出来后的结果集添加一列字段 cast('20以下' as char) as age SELECT COUNT((DATE_FORMA ...
- 使用Aspose.Cells读取Excel
最新更新请访问: http://denghejun.github.io Aspose.Cells读取Excel非常方便,以下是一个简单的实现读取和导出Excel的操作类: 以下是Aspose.Ce ...
- 使用CSS3制作三角形小图标
话不多说,直接写代码,希望能够对大家有所帮助! 1.html代码如下: <a href="#" class="usetohover"> <di ...
- ReactJS入门(四)—— 组件API
本篇将介绍 React 组件的API,其中主要的几个API我们在第一篇的时候便已介绍过,这里可以做个温故知新. 本篇的代码你也可以在我的Github上获取到. setState 参数: nextSta ...
- 借助 Lucene.Net 构建站内搜索引擎(上)
前言:最近翻开了之前老杨(杨中科)的Lucene.Net站内搜索项目的教学视频,于是作为老杨脑残粉的我又跟着复习了一遍,学习途中做了一些笔记也就成了接下来您看到的这篇博文,仅仅是我的个人笔记,大神请呵 ...
- Step by step Dynamics CRM 2011升级到Dynamics CRM 2013
原创地址:http://www.cnblogs.com/jfzhu/p/4018153.html 转载请注明出处 (一)检查Customizations 从2011升级到2013有一些legacy f ...
- SVN+码云 简单使用流程
1.登录码云网站...
- Atitit 图像处理 深刻理解梯度原理计算.v1 qc8
Atitit 图像处理 深刻理解梯度原理计算.v1 qc8 1.1. 图像处理 梯度计算 基本梯度 内部梯度 外部梯度 方向梯度1 2. 图像梯度就是图像边缘吗?2 1.1. 图像处理 梯度计算 ...
- BFC,定位,浮动,7种垂直居中方法
目录 一.BFC与IFC 1.1.BFC与IFC概要 1.2.如何产生BFC 1.3.BFC的作用与特点 二.定位 2.2.relative 2.3.absolute 2.4.fixed 2.5.z- ...
- SSIS 参数的值
一,SSIS Parameter Value 的type 一个Parameter的Value共有三种类型,分别是Design Value,Server Value,Execution Value. D ...