(4)一起来看下mybatis框架的缓存原理吧
本文是作者原创,版权归作者所有.若要转载,请注明出处.本文只贴我觉得比较重要的源码,其他不重要非关键的就不贴了
我们知道.使用缓存可以更快的获取数据,避免频繁直接查询数据库,节省资源.
MyBatis缓存有一级缓存和二级缓存.
1.一级缓存也叫本地缓存,默认开启,在一个sqlsession内有效.当在同一个sqlSession里面发出同样的sql查询请求,Mybatis会直接从缓存中查找。如果没有则从数据库查找
下面我们贴一下一级缓存的测试结果
String resource = "mybatis.xml";
//读取配置文件,生成读取流
InputStream inputStream = Resources.getResourceAsStream(resource);
//返回的DefaultSqlSessionFactory是SqlSessionFactory接口的实现类,
//这个类只有一个属性,就是Configuration对象,Configuration对象用来存放读取xml配置的信息
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
//SqlSession是与数据库打交道的对象 SqlSession对象中有上面传来的Configuration对象,
//SqlSession对象还有executor处理器对象,executor处理器有一个dirty属性,默认为false
//返回的DefaultSqlSession是SqlSession接口的实现类
SqlSession sqlSession = sqlSessionFactory.openSession();
//SqlSession sqlSession2 = sqlSessionFactory.openSession();
//通过动态代理实现接口 ,用动态代理对象去帮我们执行SQL
//这里生成mapper实际类型是org.apache.ibatis.binding.MapperProxy
DemoMapper mapper = sqlSession.getMapper(DemoMapper.class);
DemoMapper mapper2 = sqlSession.getMapper(DemoMapper.class);
//这里用生成的动态代理对象执行
String projId="0124569b738e405fb20b68bfef37f487";
String sectionName="标段";
List<ProjInfo> projInfos = mapper.selectAll(projId, sectionName);
List<ProjInfo> projInfos2 = mapper2.selectAll(projId, sectionName);
System.out.println(projInfos.hashCode());//这里和下面那条的查询结果的hashcode是一样的
System.out.println(projInfos2.hashCode());//
sqlSession.close(); sqlSession = sqlSessionFactory.openSession();
DemoMapper mapper5 = sqlSession.getMapper(DemoMapper.class);
List<ProjInfo> projInfos5 = mapper5.selectAll(projId, sectionName);
System.out.println(projInfos5.hashCode());//这里和上面两条的查询结果的hashcode是不一样的

好,我们可以看到,上面两条的查询结果的hashcode一样,第三条不一样,一级缓存生效了
2.二级缓存是mapper级别的,就是说二级缓存是以Mapper配置文件的namespace为单位创建的。
二级缓存默认是不开启的,需要手动开启二级缓存,如下需要在mybatis配置文件中的settting标签里面加入开启
<settings>
<!-- 开启二级缓存。value值填true -->
<setting name="cacheEnabled" value="true"/>
<!-- 配置默认的执行器。SIMPLE 就是普通的执行器;
REUSE 执行器会重用预处理语句(prepared statements); BATCH 执行器将重用语句并执行批量更新。默认SIMPLE -->
<setting name="defaultExecutorType" value="SIMPLE"/>
</settings>
实现二级缓存的时候,MyBatis要求返回的对象必须是可序列化的,如图
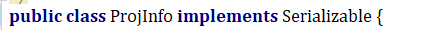
还要在mapper,xml文件中添加cache标签,标签里的readOnly属性需填true 如下:
<cache readOnly="true" ></cache>
<select id="selectAll" resultType="com.lusaisai.po.ProjInfo">
SELECT id AS sectionId,section_name AS sectionName,proj_id AS projId
FROM b_proj_section_info
WHERE proj_id=#{projId} AND section_name LIKE CONCAT('%',#{sectionName},'%')
</select>
我们再来看下二级缓存的运行结果
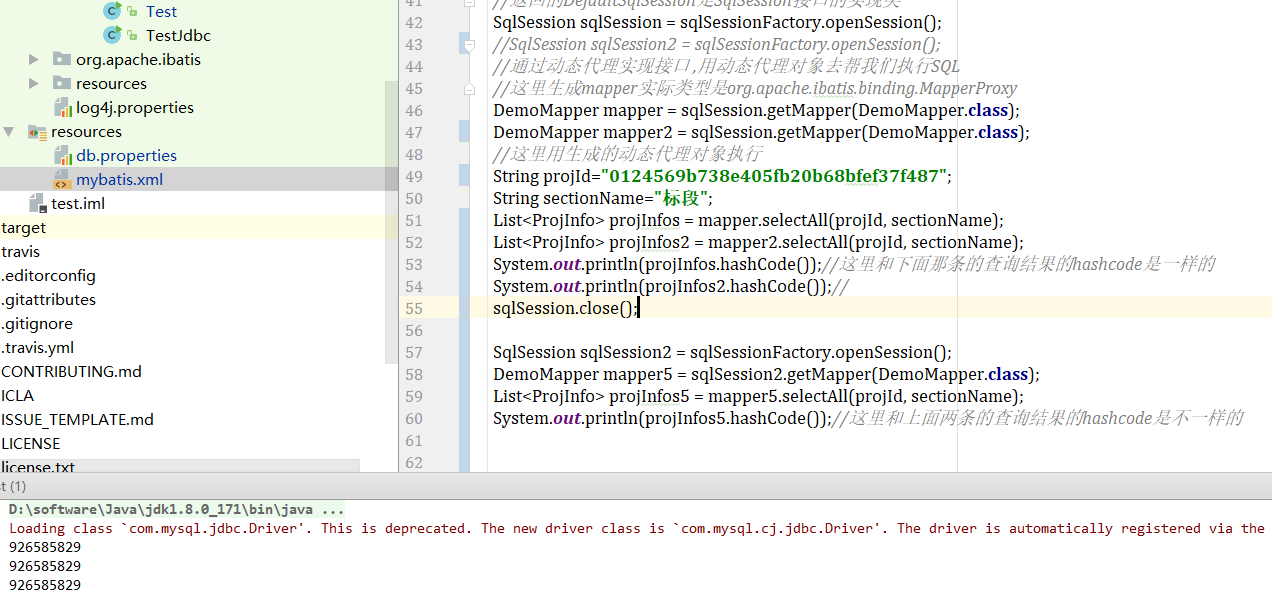
我们可以看到二级缓存也生效了.
下面来看看缓存的源码,大家猜底层是使用什么实现的,前面的流程就不一一看了,主要贴一下缓存的代码,
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
//
BoundSql boundSql = ms.getBoundSql(parameterObject);
CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql);
//这个跟进去看戏,应该是真正的jdbc操作了
return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
我们可以看到,上面的生成了一个缓存的key,具体怎么实现的就先不看了,看下key这个对象有什么属性吧
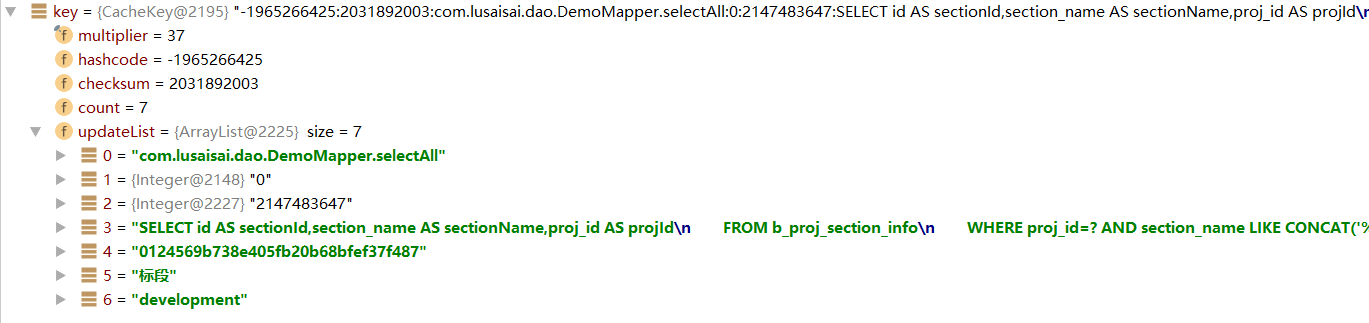
我们可以看到,key对象有这条sql语句除了结果之外的所有信息,还有hashcode等等,我们继续跟进去
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
//MappedStatement的作用域是全局共享的,这里的cache是接口,有多个实现类
Cache cache = ms.getCache();
if (cache != null) {
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
ensureNoOutParams(ms, boundSql);
@SuppressWarnings("unchecked")
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) {
list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
}
}
//前面是缓存处理跟进去
return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
我们看下Cache 的实现类

有很多,这里就不深究了,继续往下看,我们看下list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql)这行代码,这是处理一级缓存的方法,点进去看下
这里用到我们前面生成的key了
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List<E> list;
try {
queryStack++;
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
//进这里,继续跟
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
// issue #601
deferredLoads.clear();
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
clearLocalCache();
}
}
return list;
}
我们关注下list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;这行代码,点进去看下
@Override
public Object getObject(Object key) {
return cache.get(key);
}
我截个图,看下上图的PerpetualCache对象底层是怎么实现的
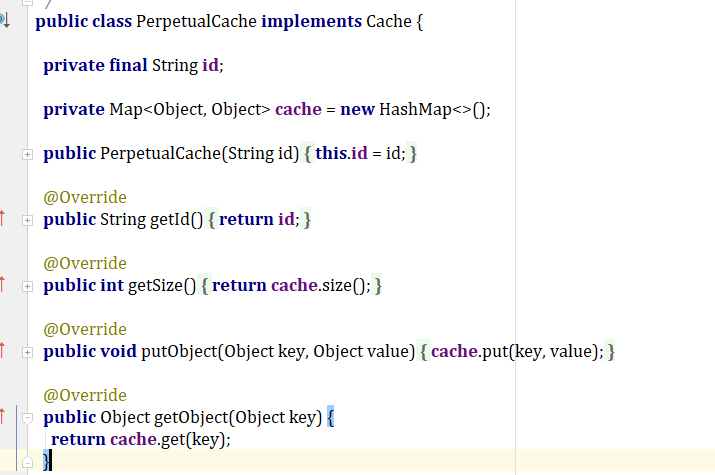
好,很明显了,这里一级缓存是用的hashmap实现的.
下面我们看下二级缓存的代码,上面的List<E> list = (List<E>) tcm.getObject(cache, key);这行代码跟进去
public Object getObject(Cache cache, CacheKey key) {
return getTransactionalCache(cache).getObject(key);
}
继续跟
@Override
public Object getObject(Object key) {
// issue #116
Object object = delegate.getObject(key);
if (object == null) {
entriesMissedInCache.add(key);
}
// issue #146
if (clearOnCommit) {
return null;
} else {
return object;
}
}
截个图看下delegate对象的属性,很多层
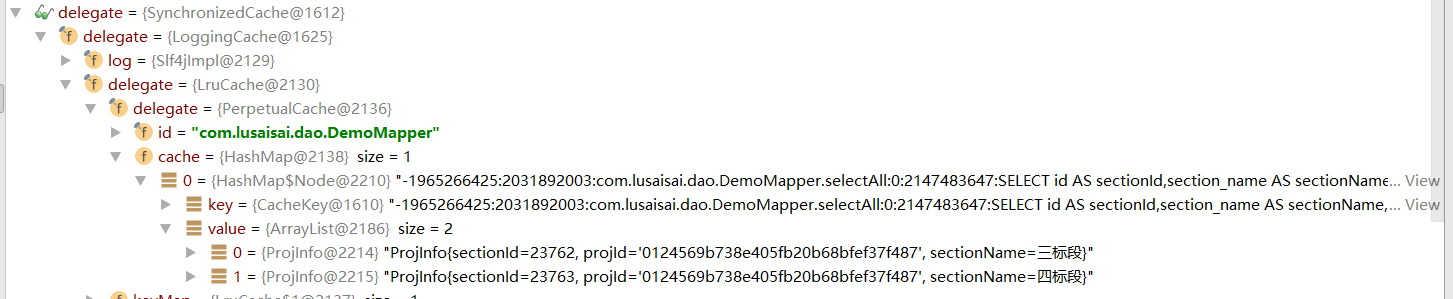
我们可以看到所有数据都在这里了.网上找的图

再来一段缓存的关键代码,这里就是包装了一层层对象的代码
private Cache setStandardDecorators(Cache cache) {
try {
MetaObject metaCache = SystemMetaObject.forObject(cache);
if (size != null && metaCache.hasSetter("size")) {
metaCache.setValue("size", size);
}
if (clearInterval != null) {
cache = new ScheduledCache(cache);
((ScheduledCache) cache).setClearInterval(clearInterval);
}
if (readWrite) {
cache = new SerializedCache(cache);
}
cache = new LoggingCache(cache);
cache = new SynchronizedCache(cache);
if (blocking) {
cache = new BlockingCache(cache);
}
return cache;
} catch (Exception e) {
throw new CacheException("Error building standard cache decorators. Cause: " + e, e);
}
}
好,再来张图总结一下
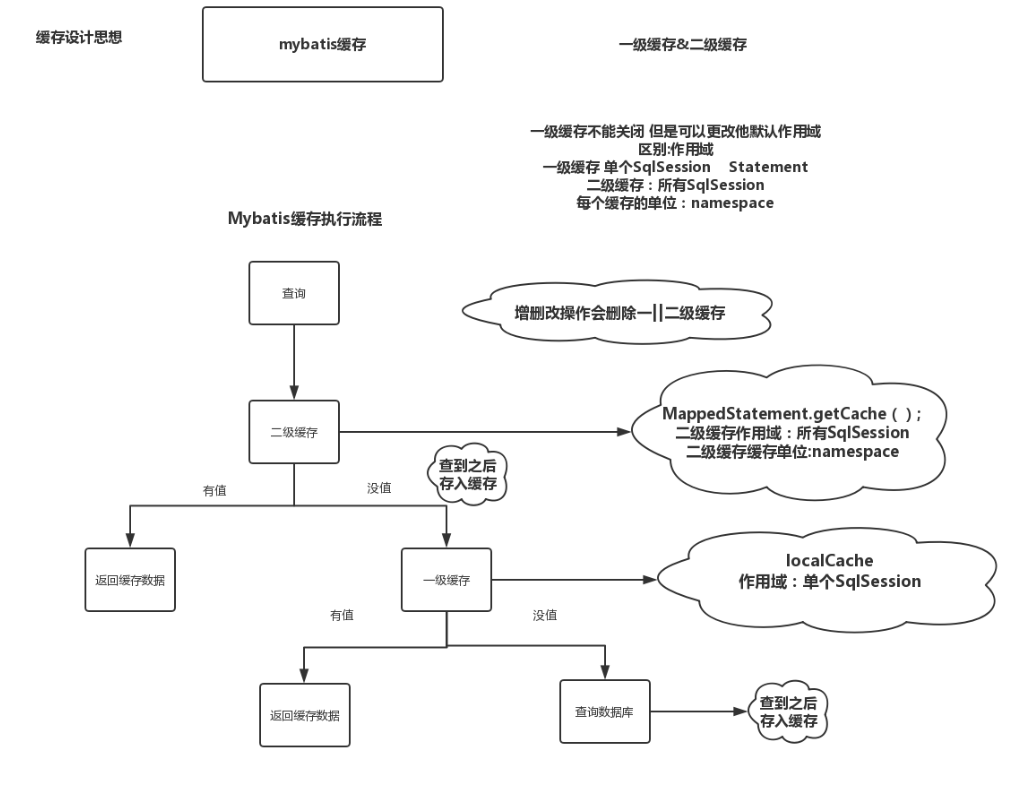
最后,如果我们和spring整合,那么此时mybatis一级缓存就会失效,因为sqlsession交给spring管理,会自动关闭session.
关于如何和spring整合就后面再来讲吧,下面一段时间,我会先研究一下spring源码,spring专题见啦
(4)一起来看下mybatis框架的缓存原理吧的更多相关文章
- MyBatis:二级缓存原理分析
MyBatis从入门到放弃七:二级缓存原理分析 前言 说起mybatis的一级缓存和二级缓存我特意问了几个身边的朋友他们平时会不会用,结果没有一个人平时业务场景中用. 好吧,那我暂且用来学习源码吧.一 ...
- mybatis两级缓存原理剖析
https://blog.csdn.net/zhurhyme/article/details/81064108 对于mybatis的缓存认识一直有一个误区,所以今天写一篇文章帮自己订正一下.mybat ...
- 手写mybatis框架-增加缓存&事务功能
前言 在学习mybatis源码之余,自己完成了一个简单的ORM框架.已完成基本SQL的执行和对象关系映射.本周在此基础上,又加入了缓存和事务功能.所有代码都没有copy,如果也对此感兴趣,请赏个Sta ...
- CodeIgniter框架的缓存原理分解
用缓存的目的:(手册上叙述如下,已经写得很清楚了) Codeigniter 支持缓存技术,以达到最快的速度. 尽管CI已经相当高效了,但是网页中的动态内容.主机的内存CPU 和数据库读取速度等因素直接 ...
- Spring Boot + Mybatis + Redis二级缓存开发指南
Spring Boot + Mybatis + Redis二级缓存开发指南 背景 Spring-Boot因其提供了各种开箱即用的插件,使得它成为了当今最为主流的Java Web开发框架之一.Mybat ...
- Mybatis拦截器实现原理深度分析
1.拦截器简介 拦截器可以说使我们平时开发经常用到的技术了,Spring AOP.Mybatis自定义插件原理都是基于拦截器实现的,而拦截器又是以动态代理为基础实现的,每个框架对拦截器的实现不完全相同 ...
- mybatis源码专题(2)--------一起来看下使用mybatis框架的insert语句的源码执行流程吧
本文是作者原创,版权归作者所有.若要转载,请注明出处.本文以简单的insert语句为例 1.mybatis的底层是jdbc操作,我们先来回顾一下insert语句的执行流程,如下 执行完后,我们看下数据 ...
- SpringBoot 下 mybatis 的缓存
背景: 说起 mybatis,作为 Java 程序员应该是无人不知,它是常用的数据库访问框架.与 Spring 和 Struts 组成了 Java Web 开发的三剑客--- SSM.当然随着 Spr ...
- 【Mybatis框架】查询缓存(一级缓存)
做Java的各位程序员们,估计SSH和SSM是我们的基础必备框架.也就是说我们都已经至少接触过了这两套常见的集成框架.当我们用SSH的时候,相信很多人都接触过hibernate的两级缓存,同样,相对应 ...
随机推荐
- erlang加密模块crypto的一些使用
crypto 模块描述:该模块提供一系列加密函数: 散列函数-安全散列标准,MD5报文摘要算法(RFC 1321)和MD4报文摘要算法(RFC 1320); Hmac函数-散列消息认证(RFC 210 ...
- Redis哨兵模式实现集群的高可用
先了解一下哨兵都 做了什么工作:Redis 的 Sentinel 系统用于管理多个 Redis 服务器(instance), 该系统执行以下三个任务: 监控(Monitoring): Sentinel ...
- 阿里mysql规范
(一)建表规约 1.[强制]表达是与否概念的字段,必须使用 is_xxx的方式命名,数据类型是 unsigned tinyint( 1表示是,0表示否),此规则同样适用于 odps建表. 说明:任何字 ...
- 控制执行流程之ForEach语法
1.定义 : 一种更加简洁的for语法,用于数组和容器===>>>foreach,无需创建int类型变量对被访问项构建的序列进行计数. 2.经典应用: 对于数组的初始化,如果选用f ...
- Tcloud 云测平台-多服务框架开源
技术栈 Python3.7 + Vue前端github地址:https://github.com/bigbaser/Tcloud后端github地址:https://github.com/bigbas ...
- 词义消除歧义NLP项目实验
词义消除歧义NLP项目实验 本项目主要使用https://github.com/alvations/pywsd 中的pywsd库来实现词义消除歧义 目前,该库一部分已经移植到了nltk中,为了获得更好 ...
- JavaScript之操作符
计算机被发明的初衷仅仅是为了快速实现一些数学计算,然而经过多年发展,计算机已经不单单能实现快速计算这么简单的工作了,现代计算机不仅能够进行数值的计算,还能进行逻辑计算,还具备存储记忆功能,是能够按照程 ...
- javascript数组/对象数组的深浅拷贝问题
一.问题描述 在项目里的一个报名页面需要勾选两条信息(信息一和信息二),由于信息一和信息二所拥有的数据是一致的,所以后台只返回了一个对象数组,然后在前台设置了两个List数组来接收并加以区分.原型如下 ...
- 使用python发邮件(qq邮箱)
今天打算用QQ邮箱作为示例使用的邮箱,其他邮箱基本操作一样. 第一步:首先获取QQ邮箱授权码 1.进入QQ邮箱首页,点击设置,如图, 2.然后点击账户 3.拉到这个地方,开启POP3/SMTP服务服务 ...
- 微服务SpringCloud之注册中心Consul
Consul 介绍 Consul 是 HashiCorp 公司推出的开源工具,用于实现分布式系统的服务发现与配置.与其它分布式服务注册与发现的方案,Consul 的方案更“一站式”,内置了服务注册与发 ...