Python高级应用程序设计任务要求
Python高级应用程序设计任务要求
用Python实现一个面向主题的网络爬虫程序,并完成以下内容:
(注:每人一题,主题内容自选,所有设计内容与源代码需提交到博客园平台)
名称:爬取爱彼迎房源信息(泉州地区)
2.主题式网络爬虫爬取的内容与数据特征分析
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
设计方案:使用request库和beautifulSoup库对爱彼迎网站进行访问,采集与处理数据,将爱彼迎房源数据分析出来、数据可视化和持久化。
技术难点主要是对爱彼迎页面的分析和采集。
1.主题页面的结构特征
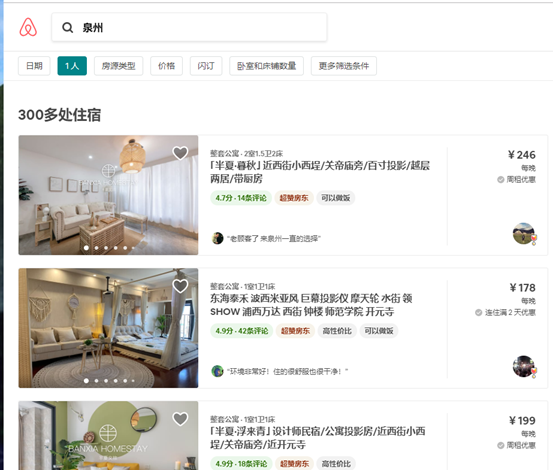
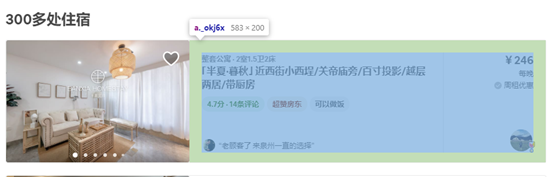
2.Htmls页面解析
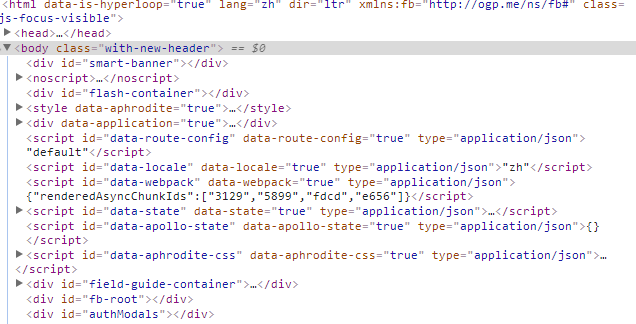
3.节点(标签)查找方法与遍历方法
(必要时画出节点树结构)
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
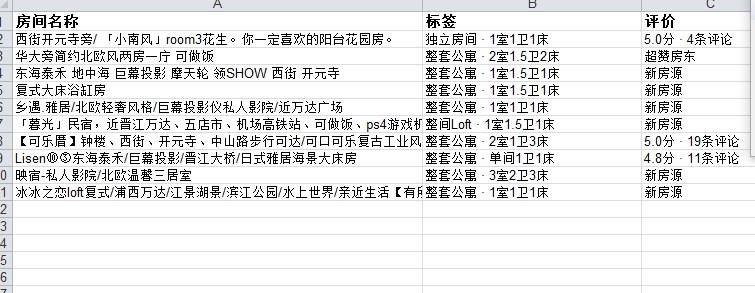


1.数据爬取与采集
def getinfo(self,url):
# 获取网页数据
try:
#伪装UA
ua = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36'}
#读取网页
r = requests.get(url, headers=ua)
# 获取状态
r.raise_for_status()
# 状态判断
if (r.status_code == 200):
r.encoding = chardet.detect(r.content)["encoding"]
return r.text
return None
except:
return "下载错误" def getHouseInfo(self,html):
'''
获取用户基本信息
'''
# 初始化BeautifulSoup库
soup = BeautifulSoup(html, "html.parser")
# 创建字典
def getHouseInfo(self,html):
'''
获取用户基本信息
'''
# 初始化BeautifulSoup库
soup = BeautifulSoup(html, "html.parser")
# 创建字典
datas = []
# div._1wbi47zw > div._hgs47m > div._10ejfg4u > div._y5sok6 > div._qlq27g > a._okj6x
s = soup.select("div._1wbi47zw > div._hgs47m > div._10ejfg4u > div._y5sok6 > div._qlq27g > a._okj6x")
#循环上面房间数据
for i in s:
# 临时数组
data = {}
# 取出房间名称
name = i.select("div._qrfr9x5")
# 打印
print(str(name[0].get_text()))
# 加入成员
data['房间名称'] = str(name[0].get_text())
#取出房间的tags标签
tags = i.select("span._faldii7")
# 打印
print(str(tags[0].get_text()))
# 标签
data['标签'] = str(tags[0].get_text())
# 打印
print(str(tags[1].get_text()))
# 评分
data['评价'] = str(tags[1].get_text())
# 加入字典
datas.append(data)
# 返回
return datas
def grab(self):
url = "https://www.airbnb.cn/s/%E6%B3%89%E5%B7%9E/homes"
print('--------------开始下载')
html = self.getinfo(url)
print('--------------开始解析')
house = self.getHouseInfo(html)
print("成功解析:%s条信息"%len(house))
for i,value in enumerate(house):
print('******** %s ********'%(i+1))
for item in value.items():
print("%s\t:%s"%item)
print('*******************')
# 持久化
self.write_data(house) if __name__ == '__main__':
house = house()
house.grab()
5.数据持久化
def set_style(self,name,height,bold=False):
# 创建一个样式对象,初始化样式
style = xlwt.XFStyle()
font = xlwt.Font()
font.name = name
font.bold = bold
font.color_index = 4
font.height = height
style.font = font
return style
'''
持久化
'''
def write_data(self,datas):
if datas is None:
return None
try:
# print(help(self.sheet1.write()))
top = list(datas[0].keys())
# 数据表头
for i in range(0, len(datas[0])):
row = 0
col = i
self.sheet1.write(row, col,top[i], self.set_style('Times New Roman', 220, True))
for i in range(0,len(datas)):
row = i+1
col = 0
dictValue = list(datas[i].values())
for colIndex in range(0, len(dictValue)):
col = colIndex
self.sheet1.write(row, col,dictValue[colIndex])
self.sheet1.col(0).width = 15000
self.sheet1.col(1).width = 8000
self.sheet1.col(2).width = 5000
self.f.save('house.xls')
except:
print('持久化失败,请重新开始')
def grab(self):
url = "https://www.airbnb.cn/s/%E6%B3%89%E5%B7%9E/homes"
print('--------------开始下载')
html = self.getinfo(url)
print('--------------开始解析')
house = self.getHouseInfo(html)
print("成功解析:%s条信息"%len(house))
for i,value in enumerate(house):
print('******** %s ********'%(i+1))
for item in value.items():
print("%s\t:%s"%item)
print('*******************')
# 持久化
self.write_data(house) if __name__ == '__main__':
house = house()
house.grab()
# -*- coding: utf-8 -*- import requests
from bs4 import BeautifulSoup
import records
import time
import chardet
import xlwt # 构造字典
dats = [] class house(object): '''
对象初始化
'''
def __init__(self):
self.f = xlwt.Workbook()
# 给表格新建一个名为 sheer1 的工作簿
self.sheet1 = self.f.add_sheet('sheet1', cell_overwrite_ok=True) '''
#设置表格样式
'''
def set_style(self,name,height,bold=False):
# 创建一个样式对象,初始化样式
style = xlwt.XFStyle()
font = xlwt.Font()
font.name = name
font.bold = bold
font.color_index = 4
font.height = height
style.font = font
return style
'''
持久化
'''
def write_data(self,datas):
if datas is None:
return None
try:
# print(help(self.sheet1.write()))
top = list(datas[0].keys())
# 数据表头
for i in range(0, len(datas[0])):
row = 0
col = i
self.sheet1.write(row, col,top[i], self.set_style('Times New Roman', 220, True))
for i in range(0,len(datas)):
row = i+1
col = 0
dictValue = list(datas[i].values())
for colIndex in range(0, len(dictValue)):
col = colIndex
self.sheet1.write(row, col,dictValue[colIndex])
self.sheet1.col(0).width = 15000
self.sheet1.col(1).width = 8000
self.sheet1.col(2).width = 5000
self.f.save('house.xls')
except:
print('持久化失败,请重新开始') def getinfo(self,url):
# 获取网页数据
try:
#伪装UA
ua = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36'}
#读取网页
r = requests.get(url, headers=ua)
# 获取状态
r.raise_for_status()
# 状态判断
if (r.status_code == 200):
r.encoding = chardet.detect(r.content)["encoding"]
return r.text
return None
except:
return "下载错误" def getHouseInfo(self,html):
'''
获取用户基本信息
'''
# 初始化BeautifulSoup库
soup = BeautifulSoup(html, "html.parser")
# 创建字典
datas = []
# div._1wbi47zw > div._hgs47m > div._10ejfg4u > div._y5sok6 > div._qlq27g > a._okj6x
s = soup.select("div._1wbi47zw > div._hgs47m > div._10ejfg4u > div._y5sok6 > div._qlq27g > a._okj6x")
#循环上面房间数据
for i in s:
# 临时数组
data = {}
# 取出房间名称
name = i.select("div._qrfr9x5")
# 打印
print(str(name[0].get_text()))
# 加入成员
data['房间名称'] = str(name[0].get_text())
#取出房间的tags标签
tags = i.select("span._faldii7")
# 打印
print(str(tags[0].get_text()))
# 标签
data['标签'] = str(tags[0].get_text())
# 打印
print(str(tags[1].get_text()))
# 评分
data['评价'] = str(tags[1].get_text())
# 加入字典
datas.append(data)
# 返回
return datas def grab(self):
url = "https://www.airbnb.cn/s/%E6%B3%89%E5%B7%9E/homes"
print('--------------开始下载')
html = self.getinfo(url)
print('--------------开始解析')
house = self.getHouseInfo(html)
print("成功解析:%s条信息"%len(house))
for i,value in enumerate(house):
print('******** %s ********'%(i+1))
for item in value.items():
print("%s\t:%s"%item)
print('*******************')
# 持久化
self.write_data(house) if __name__ == '__main__':
house = house()
house.grab()
1.经过对主题数据的分析与可视化,可以得到哪些结论?
经过对主题数据的分析与可视化,可以清晰地了解泉州地区的房源位置、面积、装修风格等信息,清楚地看到哪些房源密集度更高,哪些房源面积大。
通过对本次程序设计任务完成,对python爬虫有了一定的了解,但是还是需要加强学习,在爬取过程中,对数据清洗、可视化等操作还不够熟练,还需进一步加强学习。
Python高级应用程序设计任务要求的更多相关文章
- Python高级应用程序设计任务
Python高级应用程序设计任务要求 用Python实现一个面向主题的网络爬虫程序,并完成以下内容:(注:每人一题,主题内容自选,所有设计内容与源代码需提交到博客园平台) 一.主题式网络爬虫设计方案( ...
- Python高级应用程序设计任务期末作业
Python高级应用程序设计任务要求 用Python实现一个面向主题的网络爬虫程序,并完成以下内容:(注:每人一题,主题内容自选,所有设计内容与源代码需提交到博客园平台) 一.主题式网络爬虫设计方案( ...
- python 高级之面向对象初级
python 高级之面向对象初级 本节内容 类的创建 类的构造方法 面向对象之封装 面向对象之继承 面向对象之多态 面向对象之成员 property 1.类的创建 面向对象:对函数进行分类和封装,让开 ...
- python高级之函数
python高级之函数 本节内容 函数的介绍 函数的创建 函数参数及返回值 LEGB作用域 特殊函数 函数式编程 1.函数的介绍 为什么要有函数?因为在平时写代码时,如果没有函数的话,那么将会出现很多 ...
- python高级之装饰器
python高级之装饰器 本节内容 高阶函数 嵌套函数及闭包 装饰器 装饰器带参数 装饰器的嵌套 functools.wraps模块 递归函数被装饰 1.高阶函数 高阶函数的定义: 满足下面两个条件之 ...
- python高级之生成器&迭代器
python高级之生成器&迭代器 本机内容 概念梳理 容器 可迭代对象 迭代器 for循环内部实现 生成器 1.概念梳理 容器(container):多个元素组织在一起的数据结构 可迭代对象( ...
- python高级之面向对象高级
python高级之面向对象高级 本节内容 成员修饰符 特殊成员 类与对象 异常处理 反射/自省 单例模式 1.成员修饰符 python的类中只有私有成员和公有成员两种,不像c++中的类有公有成员(pu ...
- python高级之网络编程
python高级之网络编程 本节内容 网络通信概念 socket编程 socket模块一些方法 聊天socket实现 远程执行命令及上传文件 socketserver及其源码分析 1.网络通信概念 说 ...
- python高级之多线程
python高级之多线程 本节内容 线程与进程定义及区别 python全局解释器锁 线程的定义及使用 互斥锁 线程死锁和递归锁 条件变量同步(Condition) 同步条件(Event) 信号量 队列 ...
随机推荐
- WPF 精修篇 窗体唯一(Single) 显示在最前
原文:WPF 精修篇 窗体唯一(Single) 显示在最前 只运行一个窗体 并在一次点击时 显示到最前 发现用 SetForegroundWindow 并不是稳定的有效 最后使用 SetWindowP ...
- React中引用CSS样式的方法
相对于html中引用css的三种方法,react中也有三种方法,一一相对: 1. 行内样式:直接在组件内部定义 <div style={{width:'20px',height:'30px'}} ...
- SQL Server字符串函数STUFF的使用
前言: 最近有个实践练习是将学生报名数据表student中的[st_id]字段的第二个和第三个字符删除,然后在此位置插入新的字符串“200900”,其实就是替换的意思,生成新的字符串. STUFF 函 ...
- 11-Django站点管理
站点管理 内容发布的部分由网站的管理员负责,包括查看.添加.修改.删除数据 开发这些重复的功能是一件单调乏味.缺乏创造力的工作,为此,Django能够根据定义的模型类自动地生成管理模块 在Django ...
- pytest框架之mark标签
对测试用例打标签,在运行测试用例的时候,可根据标签名来过滤要运行的用例. 一.注册标签名 1.创建pytest.ini文件,在文件中按如下方式添加标签名: [pytest] markers = smo ...
- 【计算机网络】如何让Ajax通信过程携带Cookie呢?
Ajax 1. 介绍一下ajax并代码实现 1.1 基本概念 JavaScript 和XML(Asynchronous JavaScript And XML).简单点说,就是使用 XMLHttpReq ...
- oidc hybrid flow 与另外两种模式的异同
很多学习identityserver的文章都没有解释清楚oidc hybrid混合模式的含义.本文将解释hybrid模式与另外两种模式的主要区别. 我们先看一下一手文档: https://openid ...
- Koa 提交和接收 JSON 表单数据
来自 url 中的 query 参数可直接通过 context.query 获取,但 POST 方式提交的表单数据则需要借助中间件的解析来完成,比如 koa-bodyparser. 首先准备好一个表单 ...
- C# read dll config
public static SqlConnection GetSqlConnection() { Configuration myDllConfig = ConfigurationManager.Op ...
- IIS 上部署 ASP.NET Core 应用程序
1.下载 .Net Core Runtime 和 Hosting Bundle 下载地址:https://dotnet.microsoft.com/download/dotnet-core 分别下载 ...