职位画像分析(pandas/ matplotlib)
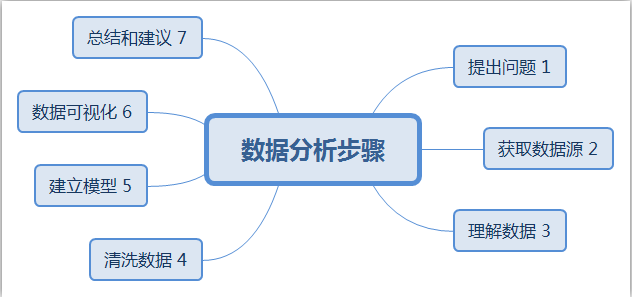
一、数据分析的步骤
二、提出问题
(1) 分析数据分析师主要的技能排名?
(2) 分析数据分析师薪资和岗位地点、学历、工作年限的关系?
(3) 数据分析师的学历需求?
(4) 不同城市数据分析师的需求?(地图展示)
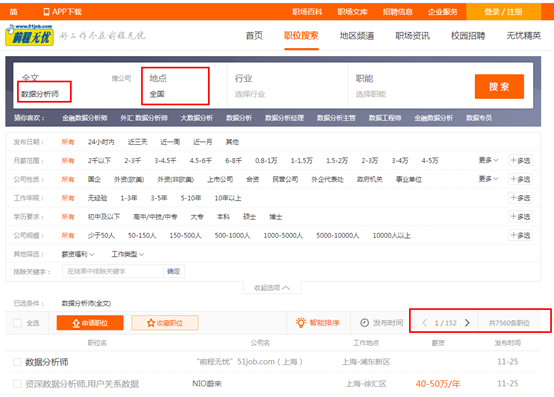
三、获取数据源
选择前程无忧官网
关键词:数据分析师
范围:全国
总记152页信息,共7560条职位信息
获取数据方法:
开发工具:pycharm
开发环境:Window 8
开发语言:python
爬虫的主要步骤:
1指定url
2获取requests模块响应对象
3解析数据
获取:名称,地点,薪资(年薪(万)),工作经验,学历和岗位要求
4数据持久化
将名称、地点、薪资、工作经验存入本地51job_data.csv文件,将岗位要求存入本地51job_info.txt文件,将解析的词频数据存入本地51job_skill.csv文件。
注意事项:
(1)先爬取一页数据保存在本地进行数据解析测试以免因直接测试请求过多被网站反爬处理
(2)正式爬取中利用UA池/IP池(反爬处理)、进程池(异步操作提高效率)
(3)对于几十万,上百万数据采用scrapy爬虫框架爬取
四、理解数据
爬取的数据源保存在51job_data.csv文件中
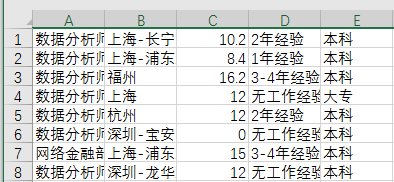
共有五个字段:名称,地点,薪资(年薪(万)),工作经验,学历
共有7538条数据
五、数据清洗

本次分析采用Jupyter Notebook分析,数据集为本地excel文件
(1)选择子集
本次分析的有51job_data.csv和51job_skill.csv两个子集,51job_skill.csv共有61条数据,直接用excel进行处理
本次选择51job_data.csv清洗
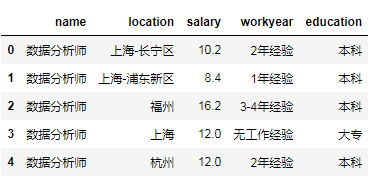
(2)列表重命名
# 列表从命名
f = open('51job_data.csv','r',encoding='GBK',errors='ignore')
data = pd.read_csv(f,sep=',',names=['name','location','salary','workyear','education'])
f.close()
data.head()
(3)删除重复值
print('删除重复值前大小',data.shape)
# 删除重复销售记录
data = data.drop_duplicates()
print('删除重复值后大小',data.shape)

(4)缺失值处理 info也可以查看字段的数据类型
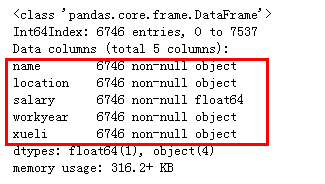
# 显示没有缺失值
(5)一致化处理
本次不需要处理
(6)数据排序
本次不需要处理
# (7)异常值处理
data.describe()
#描述指标:查看出“salary”值不能小于0
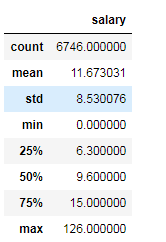
结果显示salary指标正常
六、建立模型
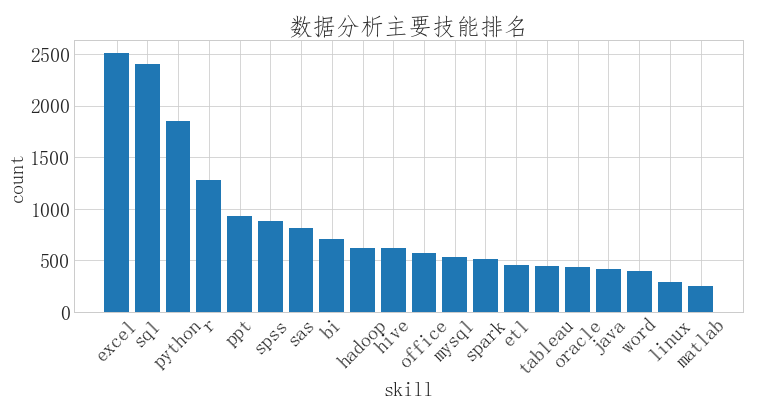
(1) 分析数据分析师主要的技能排名
# names=[] 增加列名
job_skill = pd.read_csv('51job_skill.csv',sep=',',names=['skill','count'])
job_skill.head()
# 按值进行排序 sort_values()
s = job_skill.sort_values('count',ascending=False)
# 重命名行名(index):排序后的列索引值是之前的行号,需要修改成从0到N按顺序的索引值
s=s.reset_index(drop=True)
s = s.head(20)
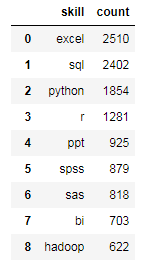
# 柱状图 bar
fig = plt.figure(figsize=(12,5))
plt.bar(s['skill'],s['count'])
plt.xlabel('skill')
plt.ylabel('count')
plt.xticks(rotation=45)
plt.title('数据分析主要技能排名')
制作词云
# 因为在词云中没有显示 r
job_skill.loc[0,'skill']='R语言'# 单个字符,无法展示
fig,ax = plt.subplots(figsize=(16,9))
mask = plt.imread('demo6.jpg')# 读入背景图片,作为词云图的参数
mycloudword = WordCloud(width=800,height=600,scale=1,margin=2,
background_color='white',
min_font_size=5,# 最小文字大小
max_font_size=70,
max_words=200,
mask=mask,
random_state=100,# 随机颜色方案,
font_path='C:\windows\Fonts\STZHONGS.TTF'# 显示中文字体
).generate(text)# 传入一个字符串
ax.imshow(mycloudword)
ax.axis('off')
mycloudword.to_file('skil.jpg') 注:STZHONGS.TTF华文中宋
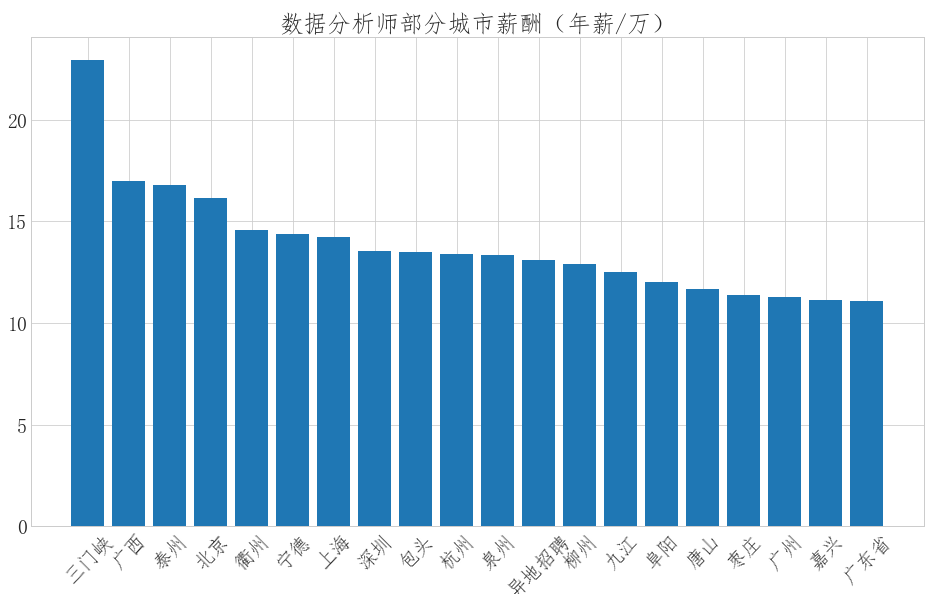
(2) 分析数据分析师薪资和岗位地点、学历、工作年限的关系?
薪资与地点关系
"""统计不同城市的平均薪资"""
data['city']=data['location'].str.extract('(\w+)-?').fillna('未知')
mean_salary = data.groupby('city')['salary'].mean().round(2)# 保留两位小数位数
mean_salary = mean_salary.sort_values(ascending=False).head(20)
fig = plt.figure(figsize=(16,9))
plt.bar(mean_salary.index,mean_salary.values)
plt.xticks(rotation=45)
plt.title('数据分析师部分城市薪酬(年薪/万)')
# 薪资和学历关系
data['education']=data['education'].fillna('无')
xl_salary = data.groupby('education')['salary'].mean().round(2)
xl_salary = xl_salary.sort_values()
fig = plt.figure(figsize=(12,5))
plt.bar(xl_salary.index,xl_salary.values)
plt.xlabel('学历')
plt.xticks(rotation=90)
plt.title('数据分析师部学历和薪资(年薪/万)的关系')

# 薪资和工作年限关系
data['workyear'].value_counts()
data['year']=data['workyear'].map({'无工作经验':0,
'3-4年经验':3.5,
'2年经验':2,
'1年经验':1,
'5-7年经验':6,
'无':0,
'8-9年经验':8.5,
'10年以上经验':10}) year_salary = data.groupby('year')['salary'].mean().round(2)
fig = plt.figure(figsize=(12,5))
plt.plot(year_salary.index,year_salary.values)
plt.plot(year_salary.index,year_salary.values,'ro')
plt.xlabel('工作年限')
plt.xticks(rotation=90)
plt.title('数据分析师部工作经验和薪资(年薪/万)的关系')

# 数据分析师的学历需求
xl_cnt = data.groupby('education')['education'].count()
xl_cnt = xl_cnt.sort_values()
fig = plt.figure(figsize=(12,5))
plt.bar(xl_cnt.index,xl_cnt.values)
plt.xlabel('学历')
plt.xticks(rotation=90)
plt.title('数据分析师部学历需求')

# 数据分析师人才需求量的地理分布
from pyecharts.charts import Map
from pyecharts import options as opts
# # maptype='china' 只显示全国直辖市和省级
# 数据只能是省名和直辖市的名称
# 为了得到城市的省份数据
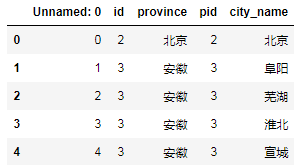
读取本地省份和城市对应的csv文件
# 读取csv文件
city_data=pd.read_csv('province.csv')
city_data.head()
查看文件
city_data.tail()
city_data.info()

data.loc[data['location']=='西藏']
# 发现原数据只有一个西藏的

city_data.loc[city_data['city_name']=='西藏'] # city_data中city_name字段中没有西藏
# 因为provice_data以 data的city字段和city_data的city_name字段进行连接

city_data.loc[364]=[364,28,'西藏',28,'西藏']
province_data = pd.merge(data,city_data,how='inner',left_on='city',right_on='city_name')
d = province_data['province'].value_counts() map_obj = Map()
# tolist 功能转化为列表
value = d.values.tolist()
attr = d.index.tolist()
mdata=[list(z) for z in zip(attr,value)]
map_obj.add('职位数',mdata,'china')
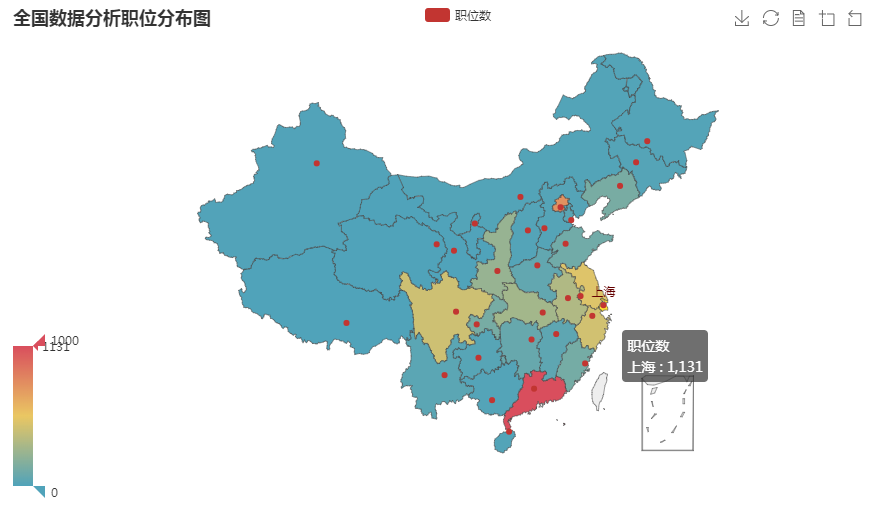
map_obj.set_global_opts(title_opts=opts.TitleOpts(title='全国数据分析职位分布图'),
visualmap_opts=opts.VisualMapOpts(max_=1000),
toolbox_opts=opts.ToolboxOpts())
map_obj.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
map_obj.render('test.html')# 把图保存到本地
map_obj.render_notebook()# 在notebook 中进行展示
七、总结和建议
总结:
(1)数据分析师的主要计能前3是excel、sql,python
(2)数据分析师城市薪资排行前3的是三门峡,广西,和台洲,和常识中的北上广深有出入
(3)数据分析师学历和年薪的关系中,按薪资降序排列,第一名是博士学历,第二是硕士,第三是本科,其中本科和硕士的年薪差别不大
(4)数据分析是工作年限和薪资的关系,从图中看出数据分析师的薪资和薪资成正比关系
(5)数据分析师的学历需求,需求最大的是本科,其次是大专,博士、硕士需求量少
(6)数据分析师人才需求量的地理分布可以看出,数据分析师的人才需求主要集中在北上广地区
建议:
对于求职者:
技能方面主要掌握excel、sql、python就可以满足一般企业需求
学历方面:至少是本科
求职地区:北上广深
职位画像分析(pandas/ matplotlib)的更多相关文章
- python 数据分析工具之 numpy pandas matplotlib
作为一个网络技术人员,机器学习是一种很有必要学习的技术,在这个数据爆炸的时代更是如此. python做数据分析,最常用以下几个库 numpy pandas matplotlib 一.Numpy库 为了 ...
- Python模块简介及安装 [numpy,pandas,matplotlib,scipy,statsmodels,Gensim,sklearn,keras]
https://pan.baidu.com/s/1bpVv3Ef 67bd 模块安装文件下载地址 pip install "numpy-1.12.0b+mkl-cp35- ...
- 第一章:AI人工智能 の 数据预处理编程实战 Numpy, Pandas, Matplotlib, Scikit-Learn
本课主题 数据中 Independent 变量和 Dependent 变量 Python 数据预处理的三大神器:Numpy.Pandas.Matplotlib Scikit-Learn 的机器学习实战 ...
- 常用统计分析python包开源学习代码 numpy pandas matplotlib
常用统计分析python包开源学习代码 numpy pandas matplotlib 待办 https://github.com/zmzhouXJTU/Python-Data-Analysis
- numpy+pandas+matplotlib+tushare股票分析
一.数据导入 安装tushare模块包 pip install tushare http://tushare.org/ tushare是一个财经数据接口包 import numpy as np imp ...
- 【python】pandas & matplotlib 数据处理 绘制曲面图
Python matplotlib模块,是扩展的MATLAB的一个绘图工具库,它可以绘制各种图形 建议安装 Anaconda后使用 ,集成了很多第三库,基本满足大家的需求,下载地址,对应选择pytho ...
- numpy, pandas, matplotlib等常用库的学习手册
pandas介绍: 待续 参考资料: 中文:https://www.cnblogs.com/skying555/p/5914391.html 英文:http://www.datadependence. ...
- numpy pandas matplotlib
import numpy as np import pandas as pd import matplotlib.pyplot as plt ---------------numpy--------- ...
- kaggle之数据分析从业者用户画像分析
数据为kaggle社区发布的数据分析从业者问卷调查分析报告,其中涵盖了关于该行业不同维度的问题及调查结果.本文的目的为提取有用的数据,进行描述性展示.帮助新从业的人员更全方位地了解这个行业. 参考学习 ...
随机推荐
- September 08th, 2019. Sunday, Week 37th.
A heavy drew refreshed the earth at night. 夜晚厚重的露水滋养着大地. From Leo Tolstoy. Today is the White Drew D ...
- faster-rcnn训练自己数据+测试
准备使用faster-rcnn进行检测实验.同时笔者也做了mask-rcnn,yolo-v3,ssd的实验,并进行对比. window下使用faster-rcnn https://blog.csdn ...
- 了解angularjs中的生命周期钩子函数$onInit,$onChange,$onDestory,$postLink
壹 ❀ 引 我在前面花了三篇文章用于介绍angularjs的指令directive,组件component,并专门花了一篇文章介绍directive与component的不同,其中提到在compon ...
- centos7安装服务器之安装禅道
Centos7下安装禅道 1. 下载禅道的linux版本 我的centos7的版本为:7.7版本 2. 将下载的包上传到centos7服务器上 3. 将禅道压缩包解压到/opt目录下: 4. 启动禅道 ...
- Java 后台请求第三方系统接口详解
//调用第三方系统接口 PrintWriter out = null; BufferedReader in = null; JSONObject jsonObject = null; Closeabl ...
- JAVA集合框架(一)-综述
目录 什么是java集合框架 使用类型安全的容器 集合框架简图 集合类库主要接口简述 Collection接口方法概览 什么是java集合框架 其实就是java类库提供的一套相当完整的各种数据结构的实 ...
- PAT 1007 Maximum Subsequence Sum 最大连续子序列和
Given a sequence of K integers { N1, N2, …, NK }. A continuous subsequence is defined to be { Ni, Ni ...
- (五十一)c#Winform自定义控件-文字提示-HZHControls
官网 http://www.hzhcontrols.com 前提 入行已经7,8年了,一直想做一套漂亮点的自定义控件,于是就有了本系列文章. GitHub:https://github.com/kww ...
- C#_.NetFramework_Web项目_EXCEL数据导出
[推荐阅读我的最新的Core版文章,是最全的介绍:C#_.NetCore_Web项目_EXCEL数据导出] 项目需引用NPOI的NuGet包: A-2:EXCEL数据导出--Web项目--C#代码导出 ...
- Ecplise设置全局编码为UTF-8
简介 Eclipse工作空间(workspace)的缺省字符编码是操作系统缺省的编码,简体中文操作系统 (Windows XP.Windows 2000简体中文)的缺省编码是GB18030,Windo ...