Python抓取豆瓣电影top250!
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者:404notfound 
一直对爬虫感兴趣,学了python后正好看到某篇关于爬取的文章,就心血来潮实战一把吧。当然如果你学的不好,建议可以先去小编的Python交流.裙 :一久武其而而流一思(数字的谐音)转换下可以找到了,里面有最新Python教程项目,一起交流学习进步!
实现目标:抓取豆瓣电影top250,并输出到文件中
1.找到对应的url:https://movie.douban.com/top250
2.进行页面元素的抓取:
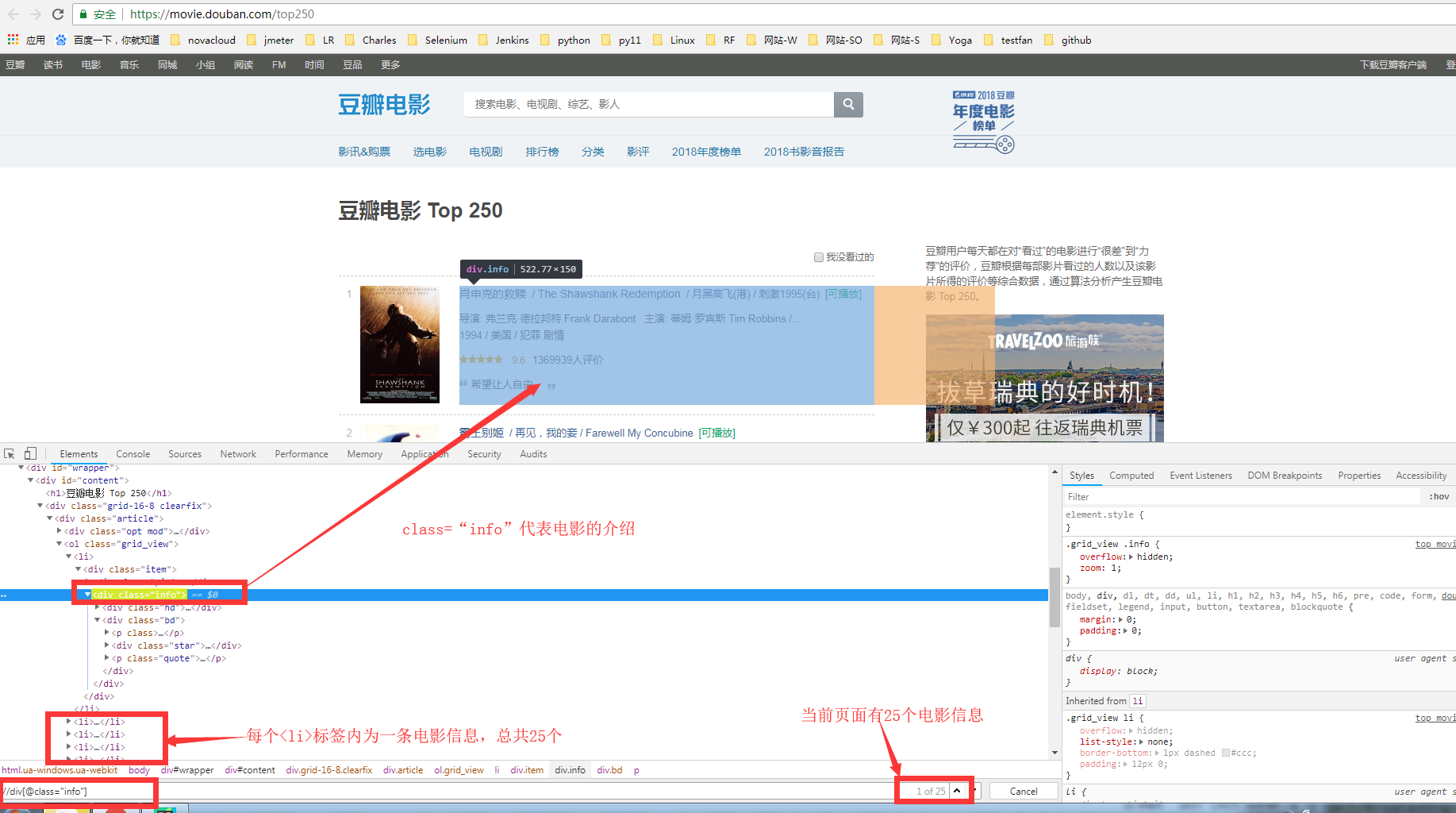
3.编写代码:
第一步:实现抓取第一个页面;
第二步:将其他页面的信息也抓取到;
第三步:输出到文件;
4.代码:
import sys
import io
from selenium import webdriver #改变标准输出,解决输出到文件时遇到的编码问题。
# 如果输出到控制行,不要加这一行
# sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='gb18030') class DouBan:
#初始化driver对象,打开页面,最大化页面
def __init__(self):
self.driver=webdriver.Chrome()
self.driver.get('https://movie.douban.com/top250')
self.driver.maximize_window() # 分页判断,默认显示第一页,输出第一页后,点击下一页按钮,再输出。总共10页
def get_content(self):
for page in range(1,10):
#获取元素定位: 对当前页面中 单个电影元素进行定位
movie = self.driver.find_elements_by_class_name('info') # for循环:循环输出当前页面中单部影片的电影信息(text输出元素的文本内容);
i = 1
for item in movie:
#输出格式: 电影序号 + 电影介绍 +换行展示
print(str(i+ page*25-25)+": "+item.text+'')
print("")
i+=1 # 判断:如果当前页面码小于10,则查找页码的元素,并点击页码。否则不用进行查找,因为最多点击第10页;
# 获取底部的页签元素(采用了format格式输出,根据当前页面做加1操作)
if page<10:
page_but = self.driver.find_element_by_xpath('//div[@class="paginator"]//a[contains(text(),{0})]'.format(page + 1))
page_but.click()
else:
pass if __name__ == '__main__':
DouBan().get_content()
5.结果:
1)控制台输出部分截图:

2)如果想要输出到文件,执行命令并重定向到TXT文件中:
python xxxx.py >d:/out_test.txt
6.遇到的问题:
1.多页时,for循环的数字设置,来回试几次就可以了,不难。
2.输出到文件中

真的很简单,不知道你们都懂了没? 如果没懂可以去小编的Python交流.裙 :一久武其而而流一思(数字的谐音)转换下可以找到了,里面有最新Python教程项目,一起交流学习进步!有问题留言问我吧~
Python抓取豆瓣电影top250!的更多相关文章
- Python:python抓取豆瓣电影top250
一直对爬虫感兴趣,学了python后正好看到某篇关于爬取的文章,就心血来潮实战一把吧. 实现目标:抓取豆瓣电影top250,并输出到文件中 1.找到对应的url:https://movie.douba ...
- Python小爬虫——抓取豆瓣电影Top250数据
python抓取豆瓣电影Top250数据 1.豆瓣地址:https://movie.douban.com/top250?start=25&filter= 2.主要流程是抓取该网址下的Top25 ...
- Python爬虫----抓取豆瓣电影Top250
有了上次利用python爬虫抓取糗事百科的经验,这次自己动手写了个爬虫抓取豆瓣电影Top250的简要信息. 1.观察url 首先观察一下网址的结构 http://movie.douban.com/to ...
- python2.7抓取豆瓣电影top250
利用python2.7抓取豆瓣电影top250 1.任务说明 抓取top100电影名称 依次打印输出 2.网页解析 要进行网络爬虫,利用工具(如浏览器)查看网页HTML文件的相关内容是很有必要,我使用 ...
- Python3 抓取豆瓣电影Top250
利用 requests 抓取豆瓣电影 Top 250: import re import requests def main(url): global num headers = {"Use ...
- python爬取豆瓣电影Top250(附完整源代码)
初学爬虫,学习一下三方库的使用以及简单静态网页的分析.就跟着视频写了一个爬取豆瓣Top250排行榜的爬虫. 网页分析 我个人感觉写爬虫最重要的就是分析网页,找到网页的规律,找到自己需要内容所在的地方, ...
- 零基础爬虫----python爬取豆瓣电影top250的信息(转)
今天利用xpath写了一个小爬虫,比较适合一些爬虫新手来学习.话不多说,开始今天的正题,我会利用一个案例来介绍下xpath如何对网页进行解析的,以及如何对信息进行提取的. python环境:pytho ...
- Python 爬取豆瓣电影Top250排行榜,爬虫初试
from bs4 import BeautifulSoup import openpyxl import re import urllib.request import urllib.error # ...
- 一起学爬虫——通过爬取豆瓣电影top250学习requests库的使用
学习一门技术最快的方式是做项目,在做项目的过程中对相关的技术查漏补缺. 本文通过爬取豆瓣top250电影学习python requests的使用. 1.准备工作 在pycharm中安装request库 ...
随机推荐
- 深入理解 PHP 的 7 个预定义接口
深入理解预定义接口 场景:平常工作中写的都是业务模块,很少会去实现这样的接口,但是在框架里面用的倒是很多. 1. Traversable(遍历)接口 该接口不能被类直接实现,如果直接写了一个普通类 ...
- 将 /u 转变为 utf-8 编码
将 /u 转变为 utf-8 编码 PHP实例: $result = {"errno":-1,"message":"\u8bbf\u95ee\u5fa ...
- 力扣(LeetCode)第一个错误的版本 个人题解
你是产品经理,目前正在带领一个团队开发新的产品.不幸的是,你的产品的最新版本没有通过质量检测.由于每个版本都是基于之前的版本开发的,所以错误的版本之后的所有版本都是错的. 假设你有 n 个版本 [1, ...
- 大公司 vs 小公司,你会选哪个?
找工作跟找对象差不多,在确立关系领证前,彼此要多些了解.在了解的基础上,你再确认是否真心喜欢对方,彼此身上有没有相互吸引的特质,两个人的性格是否互补.三观是否匹配.契合度越高,往后才能相互扶持.彼此成 ...
- Condition对象以及ArrayBlockingQueue阻塞队列的实现(使用Condition在队满时让生产者线程等待, 在队空时让消费者线程等待)
Condition对象 一).Condition的定义 Condition对象:与锁关联,协调多线程间的复杂协作. 获取与锁绑定的Condition对象: Lock lock = new Reentr ...
- synchronized:内部锁
synchronized:内部锁 起源: 并行程序开发涉及多线程.多任务间的协作和数据共享 一).内部锁:synchronized 1).定义在方法上 public synchronized void ...
- Linux 配置环境变量的tar
打开工具 连接 到Xshell 6 工具里面 查看是否 配置成功 作为一个真正的程序员,首先应该尊重编程,热爱你所写下的程序,他是你的伙伴,而不是工具.
- Flask入门学习——配置参数的管理方式
一般来说有这么几种方式: 直接操作config的字典对象 app.config["DEBUG"] = True 使用配置文件加载,直接传入文件名 app.config.from_p ...
- 剑指Offer-34.数组中的逆序对(C++/Java)
题目: 在数组中的两个数字,如果前面一个数字大于后面的数字,则这两个数字组成一个逆序对.输入一个数组,求出这个数组中的逆序对的总数P.并将P对1000000007取模的结果输出. 即输出P%10000 ...
- gganimate|创建可视化动图,让你的图表会说话
本文首发于“生信补给站”公众号,https://mp.weixin.qq.com/s/kKQ2670FBiDqVCMuLBL9NQ 更多关于R语言,ggplot2绘图,生信分析的内容,敬请关注小号. ...