tensorflow张量排序
本篇记录一下TensorFlow中张量的排序方法
tf.sort和tf.argsort
# 声明tensor a是由1到5打乱顺序组成的
a = tf.random.shuffle(tf.range(5))
# 打印排序后的tensor
print(tf.sort(a,direction='DESCENDING').numpy())
# 打印从大到小排序后,数字对应原来的索引
print(tf.argsort(a,direction='DESCENDING').numpy())
index = tf.argsort(a,direction='DESCENDING')
# 按照索引序列取值
print(tf.gather(a,index)) # 返回最大的两个值信息
res = tf.math.top_k(a,2)
# indices返回索引
print(res.indices)
# values返回值
print(res.values)

计算准确率实例:
# 定义模型输出预测概率
prob = tf.constant([[0.1,0.2,0.7],[0.2,0.7,0.1]])
# 定义y标签
target = tf.constant([2,0])
# 求top3的索引
k_b = tf.math.top_k(prob,3).indices
# 将矩阵进行转置,即把top-1,top-2,top-3分组
print(tf.transpose(k_b,[1,0]))
# 将y标签扩展成与top矩阵相同维度的tensor,方便比较
target = tf.broadcast_to(target,[3,2]) # 实现求准确率的方法
def accuracy(output,target,topk=(1,)):
maxk = max(topk)
batch_size = target.shape[0] pred = tf.math.top_k(output,maxk).indices
pred = tf.transpose(pred,perm=[1,0])
target_ = tf.broadcast_to(target,pred.shape)
correct = tf.equal(pred,target_) res = []
for k in topk:
correct_k = tf.cast(tf.reshape(correct[:k],[-1]),dtype=tf.float32)
correct_k = tf.reduce_sum(correct_k)
acc = float(correct_k/batch_size)
res.append(acc)
return res
import tensorflow as tf
import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = ''
tf.random.set_seed(2467) def accuracy(output, target, topk=(1,)):
maxk = max(topk)
batch_size = target.shape[0] pred = tf.math.top_k(output, maxk).indices
pred = tf.transpose(pred, perm=[1, 0])
target_ = tf.broadcast_to(target, pred.shape)
# [10, b]
correct = tf.equal(pred, target_) res = []
for k in topk:
correct_k = tf.cast(tf.reshape(correct[:k], [-1]), dtype=tf.float32)
correct_k = tf.reduce_sum(correct_k)
acc = float(correct_k* (100.0 / batch_size) )
res.append(acc) return res output = tf.random.normal([10, 6])
output = tf.math.softmax(output, axis=1)
target = tf.random.uniform([10], maxval=6, dtype=tf.int32)
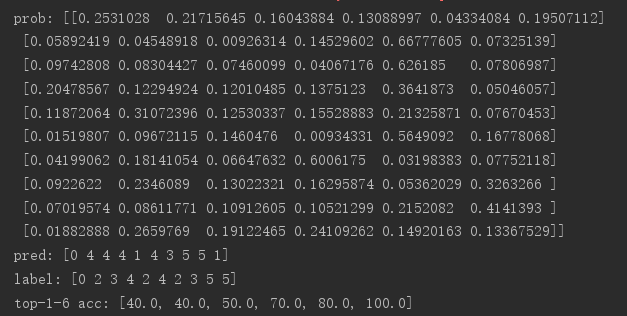
print('prob:', output.numpy())
pred = tf.argmax(output, axis=1)
print('pred:', pred.numpy())
print('label:', target.numpy()) acc = accuracy(output, target, topk=(1,2,3,4,5,6))
print('top-1-6 acc:', acc)
tensorflow张量排序的更多相关文章
- AI - TensorFlow - 张量(Tensor)
张量(Tensor) 在Tensorflow中,变量统一称作张量(Tensor). 张量(Tensor)是任意维度的数组. 0阶张量:纯量或标量 (scalar), 也就是一个数值,例如,\'Howd ...
- Tensorflow张量
张量常规解释 张量(tensor)理论是数学的一个分支学科,在力学中有重要应用.张量这一术语起源于力学,它最初是用来表示弹性介质中各点应力状态的,后来张量理论发展成为力学和物理学的一个有力的数学工具. ...
- tensorflow 张量的阶、形状、数据类型及None在tensor中表示的意思。
x = tf.placeholder(tf.float32, [None, 784]) x isn't a specific value. It's a placeholder, a value th ...
- TensorFlow—张量运算仿真神经网络的运行
import tensorflow as tf import numpy as np ts_norm=tf.random_normal([]) with tf.Session() as sess: n ...
- Tensorflow张量的形状表示方法
对输入或输出而言: 一个张量的形状为a x b x c x d,实际写出这个张量时: 最外层括号[…]表示这个是一个张量,无别的意义! 次外层括号有a个,表示这个张量里有a个样本 再往内的括号有b个, ...
- 121、TensorFlow张量命名
# tf.Graph对象定义了一个命名空间对于它自身包含的tf.Operation对象 # TensorFlow自动选择一个独一无二的名字,对于数据流图中的每一个操作 # 但是给操作添加一个描述性的名 ...
- tensorflow张量限幅
本篇内容有clip_by_value.clip_by_norm.gradient clipping 1.tf.clip_by_value a = tf.range(10) print(a) # if ...
- 吴裕雄--天生自然TensorFlow2教程:张量排序
import tensorflow as tf a = tf.random.shuffle(tf.range(5)) a tf.sort(a, direction='DESCENDING') # 返回 ...
- Tensorflow Lite从入门到精通
TensorFlow Lite 是 TensorFlow 在移动和 IoT 等边缘设备端的解决方案,提供了 Java.Python 和 C++ API 库,可以运行在 Android.iOS 和 Ra ...
随机推荐
- Go语言实现:【剑指offer】序列化二叉树
该题目来源于牛客网<剑指offer>专题. 请实现两个函数,分别用来序列化和反序列化二叉树. 二叉树的序列化是指:把一棵二叉树按照某种遍历方式的结果以某种格式保存为字符串,从而使得内存中建 ...
- Go语言实现:【剑指offer】把数组排成最小的数
该题目来源于牛客网<剑指offer>专题. 输入一个正整数数组,把数组里所有数字拼接起来排成一个数,打印能拼接出的所有数字中最小的一个.例如输入数组{3,32,321},则打印出这三个数字 ...
- [redis读书笔记] 第二部分 单机数据库 RDB持久化
内存中的rdb是会存为文件以做到RDB持久化的.RDB文件时一个二进制文件. 一 载入与存储 文件的载入是在server启动时进行的(rdbload()),因为AOF的更新频率比RDB高,所以如果AO ...
- Java Stack使用
1.Stack继承自Vector.遵从先进后出的规则. 2.Stack 是线程同步的.(map.List.Set是线程不同步的,需要在外部封装的时候来同步) 试例代码: public static v ...
- 杭电------2048神上帝以及老天爷(C语言写)
#include<stdio.h> ] = { -,-,-,-,-,-,-,-,-,-,-,-,-,-,-,-,-,-,-,-,-,- }; ] = { }; long long jiec ...
- Python 实现转堆排序算法原理及时间复杂度(多图解释)
原创文章出自公众号:「码农富哥」,欢迎转载和关注,如转载请注明出处! 堆基本概念 堆排序是一个很重要的排序算法,它是高效率的排序算法,复杂度是O(nlogn),堆排序不仅是面试进场考的重点,而且在很多 ...
- 我国自主研发的先进辅助驾驶系统(ADAS)控制器产品实现量产配套
来源: http://www.most.gov.cn/kjbgz/201710/t20171023_135606.htm 感谢对我们ADAS团队的肯定!
- oracle11g R2数据库的迁移(同windows系统迁移)使用RMAN
实验环境:windows 2008 R2 & windows 2008 R2 Oracle版本:11.2.0.1.0 源数据库端: 为保证在恢复之后的数据库中得到一致的数据,应禁止用户对数据的 ...
- Winfom 使用 BackgroundWorker 实现进度条
BackgroundWorker 简介(来自百度) BackgroundWorker是·net里用来执行多线程任务的控件,它允许编程者在一个单独的线程上执行一些操作.耗时的操作(如下载和数据库事务)在 ...
- 从零开始一个个人博客 by asp.net core and angular(三)
这是第三篇了,第一篇只是介绍,第二篇介绍了api项目的运行和启动,如果api项目没什么问题了,调试都正常了,那基本上就没什么事了,由于这一篇是讲前端项目的,所以需要运行angular项目了,由于前端项 ...