动手学习pytorch——(1)线性回归
最近参加了伯禹教育的动手学习深度学习项目,现在对第一章(线性回归)部分进行一个总结。
这里从线性回归模型之从零开始的实现和使用pytorch的简洁两个部分进行总结。
损失函数,选取平方函数来评估误差,公式如下:
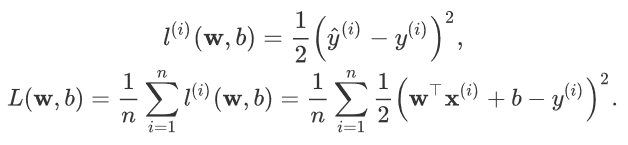
1)从零开始实现
首先设置真实的权重和偏差w,b。随机生成一个二维数组并由此生成对应的真实labels。
num_inputs = 2 #二个自变量
num_examples = 1000 # set true weight and bias in order to generate corresponded label
true_w = [2, -3.4]
true_b = 4.2 features = torch.randn(num_examples, num_inputs, dtype=torch.float32)
#1000*2 labels = true_w[0] * features[:, 0] + true_w[1] * features[:, 1] + true_b labels += torch.tensor(np.random.normal(0, 0.01, size=labels.size()),
dtype=torch.float32)
#加上一点正态分布的噪声
对于回归问题的数据,可以先用TensorData进行封装,然后再用DataLoader读取。
初始化模型参数,这里用下图的代码进行初始化。其实在pytorch中可以用torch.nn.init.normal_(tensor, a=0, b=1)等方法进行初始化。
w = torch.tensor(np.random.normal(0,0.01(num_inputs,1)),dtype=torch.float32)
b = torch.zeros(1, dtype=torch.float32) w.requires_grad_(requires_grad=True)
b.requires_grad_(requires_grad=True)
接着定义模型、损失函数和优化函数。
def linreg(X, w, b):
return torch.mm(X, w) + b def squared_loss(y_hat, y):
return (y_hat - y.view(y_hat.size())) ** 2 / 2
def sgd(params, lr, batch_size):
for param in params:
param.data -= lr * param.grad / batch_size #参数更新,这里用param.data,手动更新而不使用梯度来自动更新
最后训练,如下:
lr = 0.03 #设置学习率和epoch
num_epochs = 5 net = linreg
loss = squared_loss for epoch in range(num_epochs): # training repeats num_epochs times
# in each epoch, all the samples in dataset will be used once
# X is the feature and y is the label of a batch sample
for X, y in data_iter(batch_size, features, labels):
l = loss(net(X, w, b), y).sum()
# calculate the gradient of batch sample loss
l.backward()
# using small batch random gradient descent to iter model parameters
sgd([w, b], lr, batch_size)
# reset parameter gradient
w.grad.data.zero_()
b.grad.data.zero_()
train_l = loss(net(features, w, b), labels)
print('epoch %d, loss %f' % (epoch + 1, train_l.mean().item()))
2)pytorch简洁实现
import torch.utils.data as Data
import torch.optim as optim batch_size = 10 # combine featues and labels of dataset
dataset = Data.TensorDataset(features, labels) # put dataset into DataLoader
data_iter = Data.DataLoader(
dataset=dataset, # torch TensorDataset format
batch_size=batch_size, # mini batch size
shuffle=True, # whether shuffle the data or not
num_workers=2, # read data in multithreading
) class LinearNet(nn.Module):
def __init__(self, n_feature):
super(LinearNet, self).__init__() # call father function to init
self.linear = nn.Linear(n_feature, 1) # function prototype: `torch.nn.Linear(in_features, out_features, bias=True)` def forward(self, x):
y = self.linear(x)
return y net = LinearNet(num_inputs) init.normal_(net[0].weight, mean=0.0, std=0.01) #参数初始化
init.constant_(net[0].bias, val=0.0) loss = nn.MSELoss()
optimizer = optim.SGD(net.parameters(), lr=0.03) # built-in random gradient descent function num_epochs = 3
for epoch in range(1, num_epochs + 1):
for X, y in data_iter:
output = net(X)
l = loss(output, y.view(-1, 1)) #count loss
optimizer.zero_grad() # reset gradient, equal to net.zero_grad()
l.backward() # backpropogation
optimizer.step() # gradient optimizing
print('epoch %d, loss: %f' % (epoch, l.item())) # result comparision
dense = net[0]
print(true_w, dense.weight.data)
print(true_b, dense.bias.data)
动手学习pytorch——(1)线性回归的更多相关文章
- 动手学习Pytorch(4)--过拟合欠拟合及其解决方案
过拟合.欠拟合及其解决方案 过拟合.欠拟合的概念 权重衰减 丢弃法 模型选择.过拟合和欠拟合 训练误差和泛化误差 在解释上述现象之前,我们需要区分训练误差(training error)和泛化误差 ...
- 动手学习Pytorch(6)--卷积神经网络基础
卷积神经网络基础 本节我们介绍卷积神经网络的基础概念,主要是卷积层和池化层,并解释填充.步幅.输入通道和输出通道的含义. 二维卷积层 本节介绍的是最常见的二维卷积层,常用于处理图像数据. 二维 ...
- 动手学习pytorch——(3)多层感知机
多层感知机(multi perceptron,MLP).对于普通的含隐藏层的感知机,由于其全连接层只是对数据做了仿射变换,而多个仿射变换的叠加仍然是一个仿射变换,即使添加更多的隐藏层,这种设计也只能与 ...
- 【动手学pytorch】线性回归
代码及解释 错题整理
- 动手学习Pytorch(7)--LeNet
Convolutional Neural Networks 使用全连接层的局限性: 图像在同一列邻近的像素在这个向量中可能相距较远.它们构成的模式可能难以被模型识别. 对于大尺寸的输入图像,使用全连接 ...
- 动手学习pytorch——(2)softmax和分类模型
内容太多,捡重要的讲. 在分类问题中,通常用离散的数值表示类别,这里存在两个问题.1.输出值的范围不确定,很难判断值的意义.2.真实标签是离散值,这些离散值与不确定的范围的输出值之间的误差难以衡量. ...
- 03_利用pytorch解决线性回归问题
03_利用pytorch解决线性回归问题 目录 一.引言 二.利用torch解决线性回归问题 2.1 定义x和y 2.2 自定制线性回归模型类 2.3 指定gpu或者cpu 2.4 设置参数 2.5 ...
- 动手学习TCP:总结和索引
TCP是一个十分复杂的协议,通过前面几篇文章只涉及了TCP协议中一些基本的概念. 虽然说都是一些TCP最基本的概念,但是试验过程中一直在踩坑,例如:TCP flag设置错误,seq.ack号没有计算正 ...
- 动手学习TCP:TCP特殊状态
前面两篇文章介绍了TCP状态变迁,以及通过实验演示了客户端和服务端的正常状态变迁. 下面就来看看TCP状态变迁过程中的几个特殊状态. SYN_RCVD 在TCP连接建立的过程中,当服务端接收到[SYN ...
随机推荐
- asp.net core 3.x 通用主机是如何承载asp.net core的-上
一.前言 上一篇<asp.net core 3.x 通用主机原理及使用>扯了下3.x中的通用主机,刚好有哥们写了篇<.NET Core 3.1和WorkerServices构建Win ...
- echarts设置柱状图颜色渐变及柱状图粗细大小
series: [ { name: '值', type: 'bar', stack: '总量', //设置柱状图大小 barWidth : 20, //设置柱状图渐变颜色 itemStyle: { n ...
- 原生js面向对象编程-选项卡(点击)
<!DOCTYPE html> <html> <head lang="en"> <meta charset="UTF-8&quo ...
- 七牛云上传视频并截取第一帧为图片(js实现)
本文出自APICloud官方论坛, 感谢论坛版主 东冥羽的分享. 七牛云上传视频并截取第一帧作为视频的封面图. 使用js上传,模块videoPlayer截取第一帧(有专门的截图模块,但是我使用的有点问 ...
- python 枚举类型
在python中枚举是一种类(Enum,IntEnum),存放在enum模块中.枚举类型可以给一组标签赋予一组特定的值. 枚举的特点: 枚举类中不能存在相同的标签名 枚举是可迭代的 不同的枚举标签可以 ...
- Qt Installer Framework翻译(3-4)
更新组件 下图说明了用于更新已安装组件的默认工作流程: 本节使用在macOS上运行的Qt 5维护工具为例,来演示用户如何更新已安装组件. 启动更新程序 用户启动维护工具时,将打开"简介&qu ...
- Codeforces Round #615 (Div. 3)
A. Collecting Coins 题目链接:https://codeforces.com/contest/1294/problem/A 题意: 你有三个姐妹她们分别有 a , b , c枚硬币, ...
- CSS基础应用总结
目录 CSS 样式笔记 文字水平居中和垂直居中 如何设置a标签不带下划线 控件右对齐 div上下居中 控件左右居中 控件展示在同一行 设置文字超出部分...显示 CSS 样式笔记 文字水平居中和垂直居 ...
- 工作笔记-- 源码安装nginx
源码安装nginx 1.安装nginx的依赖包 [root@localhost ~]# yum -y install gcc gcc-c++ openssl openssl-devel pcre pc ...
- qt中的拖拽及其使用技巧
关于qt中的拖放操作,首先可以看这篇官方文档:http://doc.qt.io/qt-5.5/dnd.html 一.QDrag 首先是创建QDrag,可以在mousePressEvent或者mouse ...