吴裕雄--天生自然HADOOP操作实验学习笔记:hdfs分布式文件系统安装
实验目的
复习安装jdk
学习免密码登录
掌握安装配置hdfs集群的方法
掌握hdfs集群的简单使用和检查其工作状态
实验原理
1.hdfs是什么
hadoop安装的第一部分是安装hdfs,hdfs是一个磁盘文件系统,提供的功能类似于本地文件系统一样,可以通过命令进行增删改查文件,不同的是,hdfs通过将很多机器放在一起组成一个节点,大大提高了存储文件和处理文件的能力,也简化了对文件的操作。
2.hdfs的组成
hdfs的文件系统主要包括两个部分:namenode(管理节点)和datanode(工作节点),namenode管理元数据信息,datanode则保存真正的数据。另外hdfs中有文件块的定义,datanode上的文件都是切成块进行管理,块大小可以配置,默认是64M,可能新版本是128M。由于namenode保存的元数据比较重要,如果发生意外可能会丢失,所以会有一个备份,称为secondaryNamenode。namenode、datanode、secondarynamenode都是独立的java进程。
3.hdfs的读写文件过程
上传文件的过程 :client通过命令上传文件,首先会检查文件的大小、创建日期等信息,然后根据文件大小切块,切块之后将每个块放到datanode上,放到datanode的时候,每个块默认有三个副本,namenode会保存这个文件的大小、块信息、存放位置等元数据信息。 client通过命令读文件,首先namenode会根据路径得到数据的块信息,然后就近得到所需要的文件块,再将文件块重新组合成新文件,返回给用户。
4.hdfs的安装过程
根据上面的描述我们可以知道,一个hdfs要正常工作,需要配置namenode的地址、datanode地址,datanode的数据存放位置。其余的,例如数据块大小,可以使用默认值,也可以自己配置。另外集群工作,还需要我们前面配置过的自动时间同步、免密码登录。再加上安装java,就可以安装好hdfs集群了。
5.namenode和datanode
HDFS集群有两类节点以管理节点-工作节点模式运行,即一个namenode(管理节点)和多个datanode(工作节点)。namenode管理文件系统的命名空间。它维护着文件系统树及整颗树内所有的文件和目录。这些信息以两个文件形式永久保存在本地磁盘上:命名空间镜像文件和编辑日志文件。namenode也记录着每个文件中各个块所在的数据节点信息,但它并不永久保存块的位置信息,因为这些信息会在系统启动时根据节点信息重建。
datanode是文件系统的工作节点。它们根据需要存储并检索数据块(受客户端或namenode调度),并且定期向namenode发送他们所存储的块列表。
实验环境
- 操作系统
服务器1:Linux_Centos
服务器2:Linux_Centos
服务器3:Linux_Centos
服务器4:Linux_Centos
操作机:Windows_7
服务器1默认用户名:root,密码:123456
服务器2默认用户名:root,密码:123456
服务器3默认用户名:root,密码:123456
服务器4默认用户名:root,密码:123456
操作机默认用户名:hongya,密码:123456
步骤1:使用xshell进行连接
1.1登陆操作机。运行xshell,连接服务器。以连接服务器1为例。
名称:node6
主机(服务器1IP以实验为准):90.10.10.32
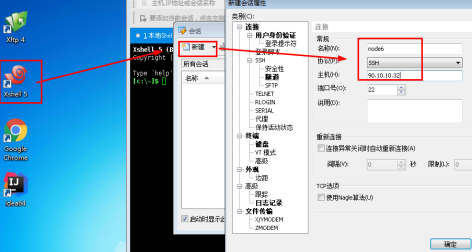
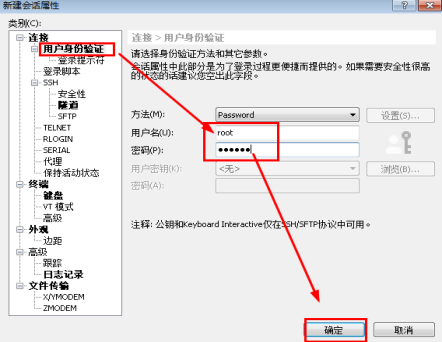
1.2进行用户身份验证。
用户名:root
密码:123456
1.3相同方法连接服务器2、3、4,其名称分别命名为node7、node8、node9。然后进行连接。连接成功后见下图:

步骤2:添加映射
2.1修改/etc/hosts文件,使其与真实环境中的服务器主机名相对应,添加ip和主机名。(四台服务器都需要修改,IP地址以实验为准)
vi /etc/hosts
添加内容:
90.10.10.32 node6
90.10.10.16 node7
90.10.10.46 node8
90.10.10.30 node9
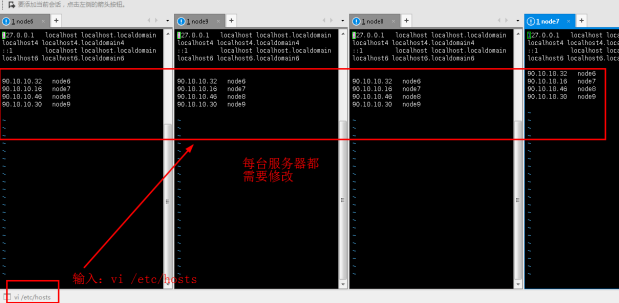
保存退出。
步骤3:配置免密码登陆、时间同步
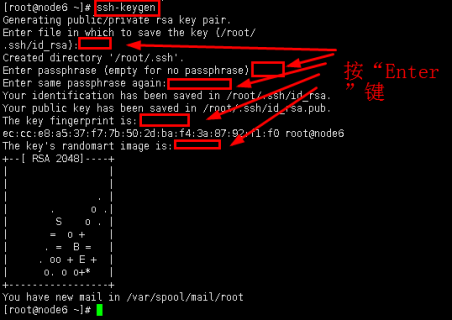
3.1主节点namenode需要控制datanode的启停,所以需要配置namenode到所有节点(包括自身节点)的免密码登陆。(四台节点都需要配置)
在namenode生成密钥和公钥,命令:
ssh-keygen
3.2将公钥复制到需要免密码登陆的节点上(四台节点都需要执行),命令: ssh-copy-id IP(服务器IP或主机名)
ssh-copy-id node6
ssh-copy-id node7
ssh-copy-id node8
ssh-copy-id node9
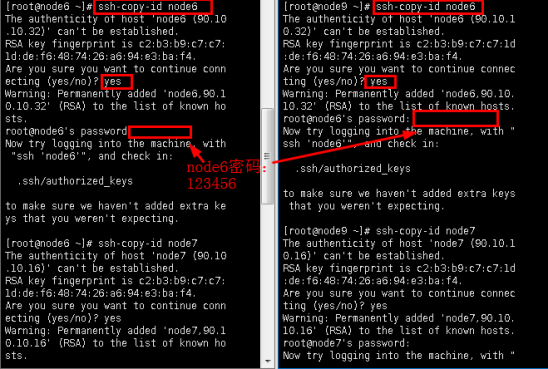
上图中命令仅以node6为例,其他公钥复制,需要同学们自行执行。
3.3关闭防火墙,同步时间
service iptables stop
date -s 10:00
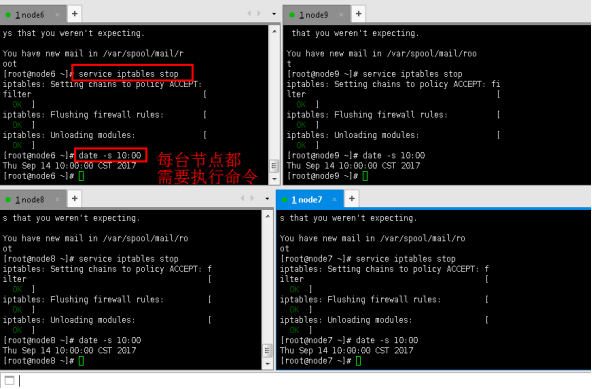
步骤4:解压Hadoop,配置文件
4.1首先解压安装包,并将其复制到/home/hadoop/soft/目录下(每台节点都需要执行)。
tar -zxvf /opt/pkg/hadoop-2.6.0-cdh5.5.2.tar.gz -C /home/hadoop/soft/

4.2配置hadoop的环境变量,另外由于hadoop的bin目录和sbin目录都有命令,所以将这两个路径都添加到PATH环境变量,编辑~/.bash_profile文件(注意这个文件是个隐藏文件),原文件已经配置好,不需要修改原有内容(每台节点都需要执行)。
vi ~/.bash_profile

4.3退出配置文件之后,执行命令,使环境变量生效(每台节点都执行)。
source ~/.bash_profile

步骤5:修改hadoop的配置文件
注:本步骤也需要每台节点都需要执行,也可以先在一台机器执行,然后复制到其他节点。
5.1配置文件hadoop-env.sh。其路径在/home/hadoop/soft/hadoop-2.6.0-cdh5.5.2/etc/hadoop下。
cd /home/hadoop/soft/hadoop-2.6.0-cdh5.5.2/etc/hadoop
ls
vim hadoop-env.sh

添加Java环境变量:
export JAVA_HOME=/home/hadoop/soft/jdk1.8.0_121
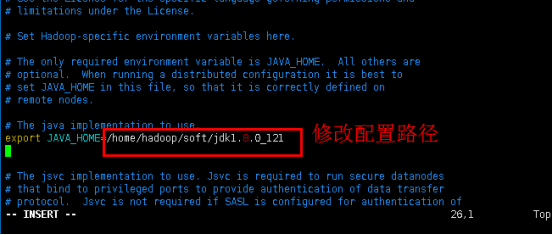
保存退出。
5.2配置同目录下的core-site.xml文件。
vim core-site.xml
添加内容:其中第一个node6是namenode的IP地址,第二个是datanode存放数据的目录
<property>
<name>fs.defaultFS</name>
<value>hdfs://node6:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/data/hadoop</value>
</property>

ESC键退出编辑,然后“:wq”保存退出。
5.3配置同目录下的master文件(目录下没有此文件,直接新建并添加内容),添加namenode的地址(每台节点都需要执行)。
vim master
添加内容:
node 6 //以node6为主节点

配置同目录下的slaves文件,添加datanode的地址(每台节点都需要执行)。
vim slaves
添加datanode:
node7
node8
node9
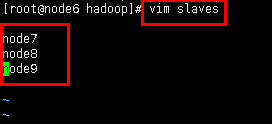
保存退出。
注意:如果实验中每个节点都执行比较麻烦,可以先在node6中实验,然后使用命令复制到其他三个节点中。
scp -r /home/hadoop/soft/hadoop-2.6.0-cdh5.5.2 root@node7:/home/hadoop/soft/
scp -r /home/hadoop/soft/hadoop-2.6.0-cdh5.5.2 root@node8:/home/hadoop/soft/
scp -r /home/hadoop/soft/hadoop-2.6.0-cdh5.5.2 root@node9:/home/hadoop/soft/
这里的hadoop是用户名,例如第一个命令的意思是:使用hadoop用户将这个文件夹拷贝到node7的指定路径下,路径根据实际情况配置。
步骤6:启动集群
6.1启动集群之前,需要主节点中格式化hdfs(仅主节点执行)。
hdfs namenode -format
对于询问输入:Y
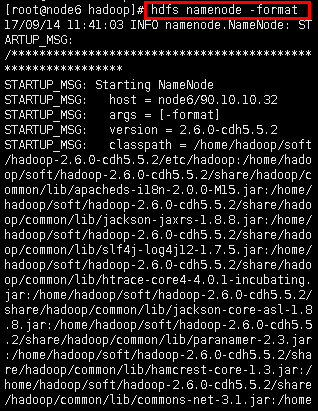
如果显示successfully formatted,代表格式化成功:
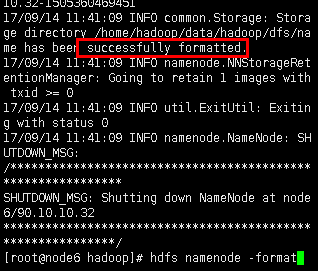
注:如果全部节点都格式化,最后检查集群时,datanode的进程会是SecondaryNameNode。这是错误的。这时,很多配置文件都已改变,修复起来比较困难。可以参看步骤7.2解决方法。如果还不能出现正确结果,建议重新进行实验。
6.2启动hdfs的命令。直接在主节点node6上启动即可,因为主节点启动的同时也启动了其节点的hdfs。
cd ..
cd ..
sbin/start-dfs.sh
注意程序都在sbin目录下
第一次启动会询问你是否连接,输入:yes

6.3检查集群。在各个节点输入jps命令,查看java进程,如果启动正常,除了Jps本身,namenode还会有另外两个进程,datanode有一个进程。
jps
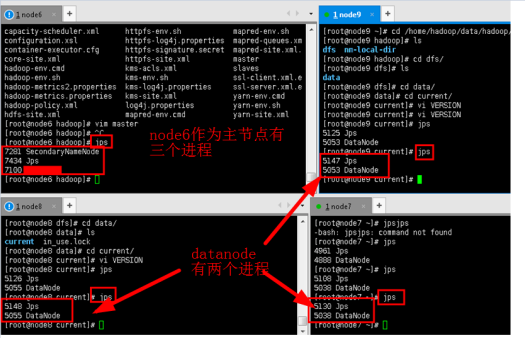
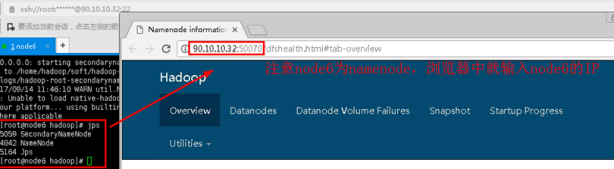
6.4打开浏览器,输入namenode的IP加上端口号50070,出现namenode的UI界面,代表启动成功。可以看到实验中node6是namenode。
输入URL:90.10.10.32:50070
6.5故障检查。启动集群都会有日志打印,如果集群启动失败,可以在hadoop安装目录下的logs文件夹,找到对应的日志文件
cd ~
cd /home/hadoop/soft/hadoop-2.6.0-cdh5.5.2/logs/
ls
tail -20 hadoop-root-datanode-node9.log
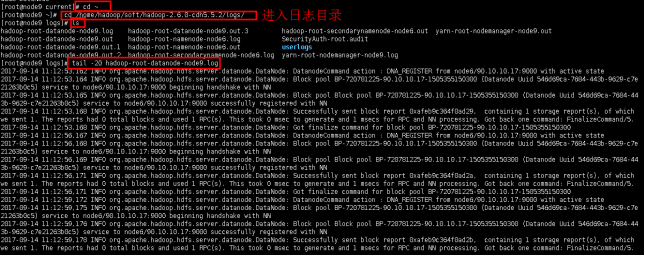
这里是正确的日志,如果有错误,可以根据日志的信息,进行排错。
6.6如果安装好后发现启动dfs时datanode老是启动不了。例如步骤6.3中查看进程,datanode没有出现,而是SecondaryNameNode。可以考虑是不是全部的节点进行了格式化或者格式化了两次namenode。
分别打开current文件夹里的VERSION,可以看到clusterID项正如日志里记录的一样。
cd /home/hadoop/data/hadoop/dfs/data/current/
ls
vi VERSION
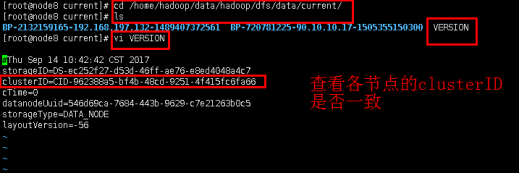
这个问题应该是由于namenode多次格式化造成了namenode和datanode的clusterID不一致!每次格式化时,namenode会更新clusterID,但是datanode只会在首次格式化时确定,因此就造成不一致现象。
吴裕雄--天生自然HADOOP操作实验学习笔记:hdfs分布式文件系统安装的更多相关文章
- 吴裕雄--天生自然HADOOP操作实验学习笔记:分布式及RPC通信简介
实验目的 掌握GOF设计模式的代理模式 了解掌握socket编程.java反射.动态代理 了解NIO.多线程 掌握hadoop的RPC框架使用API 实验原理 1.什么是RPC 在hadoop出现以前 ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:分布式资源调度系统yarn的安装
实验目的 复习配置hadoop初始化环境 复习配置hdfs的配置文件 学会配置hadoop的配置文件 了解yarn的原理 实验原理 1.yarn是什么 前面安装好了hdfs文件系统,我们可以根据需求进 ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:hdfs简单的shell命令
实验目的 了解bin/hadoop脚本的原理 学会使用fs shell脚本进行基本操作 学习使用hadoop shell进行简单的统计计算 实验原理 1.hadoop的shell脚本 当hadoop集 ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:pig简介
实验目的 了解pig的该概念和原理 了解pig的思想和用途 了解pig与hadoop的关系 实验原理 1.Pig 相比Java的MapReduce API,Pig为大型数据集的处理提供了更高层次的抽象 ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:单节点伪分布式安装
实验目的 了解java的安装配置 学习配置对自己节点的免密码登陆 了解hdfs的配置和相关命令 了解yarn的配置 实验原理 1.Hadoop安装 Hadoop的安装对一个初学者来说是一个很头疼的事情 ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:使用hive操作hbase
实验目的 熟悉hive和hbase的操作 熟悉hadoop.hbase.hive.zookeeper的关系 熟练大数据环境的搭建 学会分析日志排除问题 实验原理 1.hive整合hbase原理 前面大 ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:mapreduce代码编程
实验目的 深入了解mapreduce的底层 了解IDEA的使用 学会通过本地和集群环境提交程序 实验原理 1.回忆mapreduce模型 前面进行了很多基础工作,本次实验是使用mapreduce的AP ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:hbase学生选课案例
实验目的 复习hbase的shell操作和javaAPI操作 了解javaWeb项目的MVC设计 学会dao(数据库访问对象)和service层的代码编写规范 学会设计hbase表格 实验原理 前面我 ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:hbase的javaAPI应用
实验目的 进一步了解hbase的操作 熟悉使用IDEA进行java开发 熟悉hbase的javaAPI 实验原理 前面已经了解通过hbase的shell操作hbase,确实比较难以使用,另外通过hiv ...
随机推荐
- 牛客练习赛39 B 选点(dfs序+LIS)
题意: 有一棵n个节点的二叉树,1为根节点,每个节点有一个值wi.现在要选出尽量多的点. 对于任意一棵子树,都要满足: 如果选了根节点的话,在这棵子树内选的其他的点都要比根节点的值大: 如果在左子树选 ...
- Golang import具体使用
使用gopath的时候,一般引用是从src下一层开始,比如src/github.com/…,引用github.com…,我的工程src/xxx.com/go-qb/…,引用xxx.com/go-qb/ ...
- Go语言实现:【剑指offer】机器人的运动范围
该题目来源于牛客网<剑指offer>专题. 地上有一个m行和n列的方格.一个机器人从坐标0,0的格子开始移动,每一次只能向左,右,上,下四个方向移动一格,但是不能进入行坐标和列坐标的数位之 ...
- C2440 “初始化”: 无法从“std::_Vector_const_iterator<std::_Vector_val<std::_Simple_types<_Ty>>>”转换为“std::_Vector_iterator<std::_Vector_val<std::_Simple_types<_Ty>>>”
错误原因vs已经提醒的很清楚了:无法将const_iterator转换为iterator 我的出错代码是这样的 思考了很久,最后发现原来是因为将函数定义为const的缘故. 总结:当将函数定义为con ...
- 源码编译安装MySQL5.7
一.数据库 概述 什么是数据库?简单来说就是存储数据的仓库.这个仓库它会按照一定的数据结构来对数据进行组织和存储.我们可通过数据库提供的多种方法来管理其中的数据 说比较通俗一点就是计算机中的数据库就是 ...
- 解释为什么不能依赖fail-fast
我的观点fail-fast是什么就不多解释了,应该注意到的是(以ArrayList为例):modCount位于AbstractList中, protected transient int modCou ...
- Java开发最佳实践(一) ——《Java开发手册》之"编程规约"
Java开发手册版本更新说明 专有名词解释 一. 编程规约 (一) 命名风格 (二) 常量定义 (三) 代码格式 (四) OOP 规约 (五) 集合处理 (六) 并发处理 (七) 控制语句 (八) 注 ...
- SAXParseException Content is not allowed in Prolog (前言中不允许有内容)
解析 XML 文件的时候,如 Mybatis 的 Mapper 文件,有时会出现 org.xml.sax.SAXParseException 前言中不允许有内容 的异常,英文就是 Content is ...
- Load_file 常用路径
load_file 常用路径 WINDOWS下: c:/boot.ini //查看系统版本 c:/windows/php.ini //php配置信息 c:/windows/my.ini //MYSQL ...
- SQLPLUS ed无法调出编辑面板 SP2-0107:无须保存
现象: 重新启动oracle启动sqlplus,首先执行ed命令时出错,没有调出编辑命令的文件: SQL> edSP2-0107: 无须保存. 分析:出错的原因可能是临时编辑文件中没有需要执行的 ...