从零构建Flink SQL计算平台 - 1平台搭建
一、理想与现实
Apache Flink 是一个分布式流批一体化的开源平台。Flink 的核心是一个提供数据分发、通信以及自动容错的流计算引擎。Flink 在流计算之上构建批处理,并且原生的支持迭代计算,内存管理以及程序优化。
实时计算(Alibaba Cloud Realtime Compute,Powered by Ververica)是阿里云提供的基于 Apache Flink 构建的企业级大数据计算平台。在 PB 级别的数据集上可以支持亚秒级别的处理延时,赋能用户标准实时数据处理流程和行业解决方案;支持 Datastream API 作业开发,提供了批流统一的 Flink SQL,简化 BI 场景下的开发;可与用户已使用的大数据组件无缝对接,更多增值特性助力企业实时化转型。
Apache Flink 社区迎来了激动人心的两位数位版本号,Flink 1.10.0 正式宣告发布!作为 Flink 社区迄今为止规模最大的一次版本升级,Flink 1.10 容纳了超过 200 位贡献者对超过 1200 个 issue 的开发实现,包含对 Flink 作业的整体性能及稳定性的显著优化、对原生 Kubernetes 的初步集成以及对 Python 支持(PyFlink)的重大优化。
Flink 1.10 同时还标志着对 Blink的整合宣告完成,随着对 Hive 的生产级别集成及对 TPC-DS 的全面覆盖,Flink 在增强流式 SQL 处理能力的同时也具备了成熟的批处理能力。
在过去的2019年,大数据领域的Flink异常火爆,从年初阿里巴巴高调收购Flink的母公司,到秋天发布的1.9以及最近的1.10版本完成整合阿里Blink分支,各类分享文章和一系列国内外公司应用案例,都让人觉得Flink是未来大数据领域统一计算框架的趋势。尤其是看过阿里云上的实时计算平台,支持完善的SQL开发和批流都能处理的模式让人印(直)象(流)深(口)刻(水)。但是相对于公有云产品,稍微有点规模的公司都更愿意使用开源产品搭建自己的平台,可是仔细研究Flink的官方文档和源码,准备撸起袖子开干时,才发现理想和现实的差距很大……
首先是阿里实时计算平台产品的SQL开发界面:
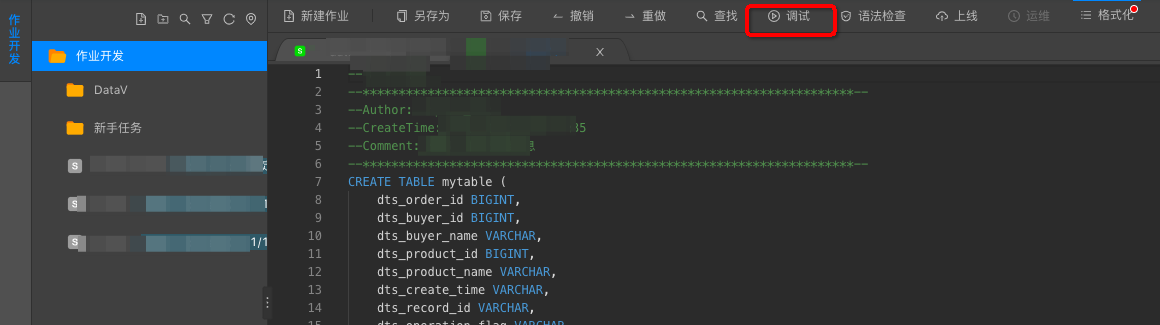
然而现实中Flink所支持的SQL开发API是这样的:
// create a TableEnvironment for specific planner batch or streaming
TableEnvironment tableEnv = ...; // see "Create a TableEnvironment" section
// register a Table
tableEnv.registerTable("table1", ...) // or
tableEnv.registerTableSource("table2", ...); // or
tableEnv.registerExternalCatalog("extCat", ...);
// register an output Table
tableEnv.registerTableSink("outputTable", ...);
// create a Table from a Table API query
Table tapiResult = tableEnv.scan("table1").select(...);
// create a Table from a SQL query
Table sqlResult = tableEnv.sqlQuery("SELECT ... FROM table2 ... ");
// emit a Table API result Table to a TableSink, same for SQL result
tapiResult.insertInto("outputTable");
// execute
tableEnv.execute("jobName");
最后翻遍Flink文档发现提供了一个实验性质的命令行SQL客户端:
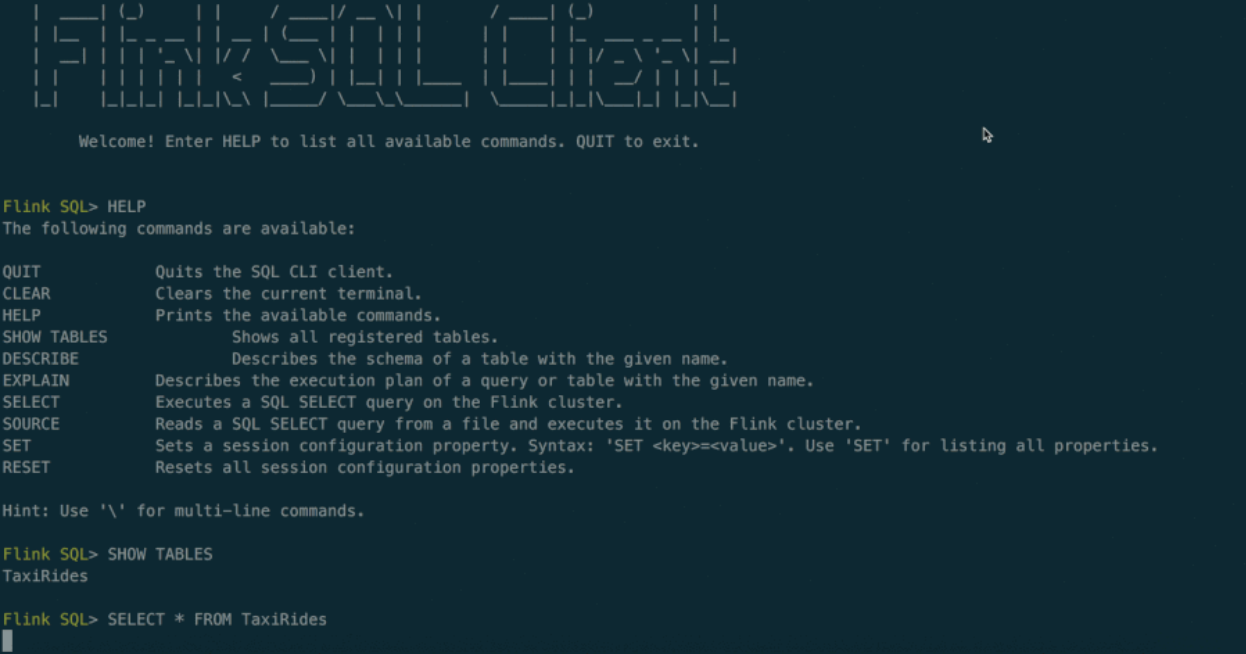
此外当我们用开源Flink代码部署一套集群后,整个集群有 JobManager 和 TaskManager 两种角色,其中 JobManager 提供了一个简单的管理界面,提供了上传Jar包执行任务的功能,以及一些简单监控界面,此外还提供一系列管理和监控的 Rest Api,可惜都没有和SQL层面直接相关的东西。
之所以有这一系列理想与现实的差异,是因为Flink更多的定位在计算引擎,在开发界面等方面暂时投入较少,但是每写一个SQL然后嵌入到代码中编译成JAR包上传到Flink集群执行是客(小)户(白)所不能接受的,这也就需要我们自己开发一套以SQL作业为中心的管理平台(对用户暴露的web系统),由该平台管理 Flink 集群,共同构成 Flink SQL 计算平台。
二、平台功能梳理
一个完整的SQL平台在产品流程上至少(第一版)需要有以下部分。
SQL作业管理:新增、调试、提交、下线SQL任务
数据源和维表管理:用DDL创建数据源表,其中维表也是一种特殊数据源
数据汇管理:用DDL创建数据结果表,即 insert into 结果表 select xxx
UDF管理:上传UDF的jar包
调度和运维:任务定时上下线、任务缩容扩容、savepoint管理
监控:日志查看、指标采集和记录、报警管理
其他:角色和权限管理、文档帮助等等……
除了作为Web系统需要的一系列增删改查和交互展示功能外,大部分Flink集群管理功能可以通过操作Flink集群提供的Rest接口实现,但是其中没有SQL相关内容,也就是前面四项功能(提交SQL、DDL、UDF,后文统称提交作业部分)都需要自己实现和 Flink 的交互代码,因此如何更好地提交作业就成了构建该平台的第一个挑战。
从零构建Flink SQL计算平台 - 1平台搭建的更多相关文章
- OPPO数据中台之基石:基于Flink SQL构建实数据仓库
小结: 1. OPPO数据中台之基石:基于Flink SQL构建实数据仓库 https://mp.weixin.qq.com/s/JsoMgIW6bKEFDGvq_KI6hg 作者 | 张俊编辑 | ...
- Demo:基于 Flink SQL 构建流式应用
Flink 1.10.0 于近期刚发布,释放了许多令人激动的新特性.尤其是 Flink SQL 模块,发展速度非常快,因此本文特意从实践的角度出发,带领大家一起探索使用 Flink SQL 如何快速构 ...
- 使用flink Table &Sql api来构建批量和流式应用(3)Flink Sql 使用
从flink的官方文档,我们知道flink的编程模型分为四层,sql层是最高层的api,Table api是中间层,DataStream/DataSet Api 是核心,stateful Stream ...
- (二)基于商品属性的相似商品推荐算法——Flink SQL实时计算实现商品的隐式评分
系列随笔: (总览)基于商品属性的相似商品推荐算法 (一)基于商品属性的相似商品推荐算法--整体框架及处理流程 (二)基于商品属性的相似商品推荐算法--Flink SQL实时计算实现商品的隐式评分 ( ...
- Apache Flink SQL
本篇核心目标是让大家概要了解一个完整的 Apache Flink SQL Job 的组成部分,以及 Apache Flink SQL 所提供的核心算子的语义,最后会应用 TumbleWindow 编写 ...
- Flink SQL 如何实现数据流的 Join?
无论在 OLAP 还是 OLTP 领域,Join 都是业务常会涉及到且优化规则比较复杂的 SQL 语句.对于离线计算而言,经过数据库领域多年的积累,Join 语义以及实现已经十分成熟,然而对于近年来刚 ...
- [源码分析] 带你梳理 Flink SQL / Table API内部执行流程
[源码分析] 带你梳理 Flink SQL / Table API内部执行流程 目录 [源码分析] 带你梳理 Flink SQL / Table API内部执行流程 0x00 摘要 0x01 Apac ...
- [源码分析]从"UDF不应有状态" 切入来剖析Flink SQL代码生成 (修订版)
[源码分析]从"UDF不应有状态" 切入来剖析Flink SQL代码生成 (修订版) 目录 [源码分析]从"UDF不应有状态" 切入来剖析Flink SQL代码 ...
- Flink sql 之 TopN 与 StreamPhysicalRankRule (源码解析)
基于flink1.14的源码做解析 公司内有很多业务方都在使用我们Flink sql平台做TopN的计算,今天同事突然问到我,Flink sql 是怎么实现topN的 ? 蒙圈了,这块源码没看过啊 , ...
随机推荐
- html中如何清除浮动
在html中,浮动可以说是比较常用的.在页面的布局中他有着很大的作用,但是浮动中存在的问题也是比较多的.现在我们简单说一下怎么去除浮动 首先我们先简单的看一下浮动: 首先我们先创建一个简单的div,并 ...
- REST 风格架构
------------------------------ 时间不多了, 抓紧做一些有意义的事情 REST 风格架构 1. 他是面向资源进行开发的 2. 他是基于HTTP 协议进行开发 ...
- CSS学习笔记--Div+Css布局实战(入门)
基本页面布局 本教程带着大家做一个简单的页面布局 最重效果如下: 1.第一部,先创建上下左右4个DIV <!DOCTYPE html> <html> <head lang ...
- TypeScript躬行记(6)——高级类型
本节将对TypeScript中类型的高级特性做详细讲解,包括交叉类型.类型别名.类型保护等. 一.交叉类型 交叉类型(Intersection Type)是将多个类型通过“&”符号合并成一个新 ...
- Sea.js 手册与文档
Sea.js 手册与文档 首页 | 索引 目录 何为 CommonJS 何为 CommonJS 模块 为何封装模块 何为 CommonJS? CommonJS 是一个有志于构建 JavaScript ...
- javaIO笔记
原创 File类 实例化 new File(path); File.separator 分隔符 创建文件的常规做法
- 验证码,java
这几天打算写一个验证码出来 遇到了几个问题 imageio写入失败:原因我创建文件的时候是先建立一个text文本,然后修改后缀,图片写不进去,还有没有编译 图像扭曲:粘连的问题,目前解决图像扭曲的问题 ...
- Docker 代理脱坑指南
Docker 代理配置 由于公司 Lab 服务器无法正常访问公网,想要下载一些外部依赖包需要配置公司的内部代理.Docker 也是同理,想要访问公网需要配置一定的代理. Docker 代理分为两种,一 ...
- Codeforces_828
A.模拟,注意单人的时候判断顺序. #include<bits/stdc++.h> using namespace std; int n,a,b; int main() { ios::sy ...
- Codeforces 961C Chessboard(将碎了的、染色乱了的棋盘碎片拼一起)
题目链接:点击打开链接 Magnus decided to play a classic chess game. Though what he saw in his locker shocked hi ...