Elasticsearch分布式架构
Reference
1. http://solutionhacker.com/elasticsearch-architecture-overview/
2. https://github.com/batscars/advanced-java/blob/master/docs/high-concurrency/es-write-query-search.md
Elasticsearch是如何组织数据的
- Elasticsearch索引是组织数据的一个逻辑单位(类似数据库),保存在索引上的数据是一堆Json格式的相关文档
- 一个Elasticsearch索引包括一个或者多个分片,分布在不同的节点上(7.x版本后默认只有一个分片),主分片的数量在索引创建之后就确定了无法修改
- 每个分片可以拥有一个或者多个副本,默认为1。ES会保证主分片和副本分片不在同一个节点上。
- 每个分片就是个Lucene索引用来保存数据,且本身就是一个搜索引擎
- 一个Lucene索引包含多个分段,每个分段本身就是一个倒排索引
- 对于每一个搜索请求,索引中的每个分段都会被搜索,每个分段都需要消耗cpu,文件句柄和内存。所以分段数量越多,搜索的性能越低。lucene会在后台将小的分段合并成大的分段,将合并后的分段写入磁盘,删除旧的小分段。
- ES包含三种常见的节点类型: master,data和client。master节点主要负责协调集群任务,比如在节点间分配分片,添加和删除索引。data节点负责通过分片保存数据,创建索引,数据搜索,聚合等操作。client节点主要作为负载均衡的角色,帮助做创建索引和搜索请求的路由。
Elasticsearch搜索过程
分为两个阶段:
- 查询阶段:搜索请求首先到达协调节点,并将查询转发到索引中每个分片的副本(主副本或副本副本)。 每个分片将在本地执行查询,并将最相关的结果的文档ID(默认为10)传递回协调节点,协调节点将依次合并并排序以找到最相关的全局结果的文档ID。
- 提取阶段:在协调节点对所有结果进行排序以生成文档的全局排序列表之后,它随后从所有分片中请求原始文档。 所有分片将会获取所有需要获取的字段,然后将其返回到协调节点。 最后,最终的搜索结果被发送回客户端。
Index Refresh
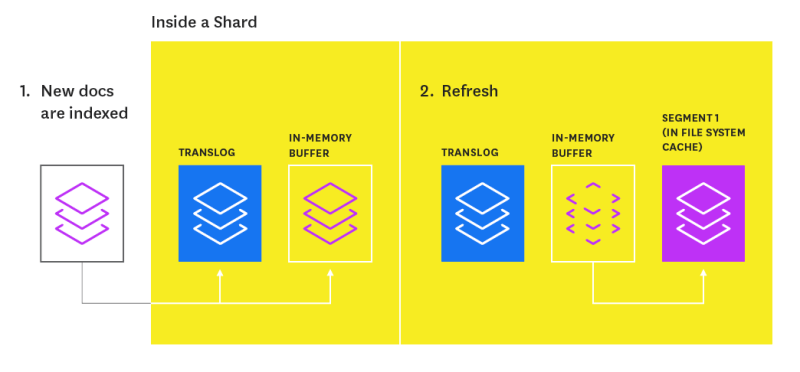
提交文档索引请求后,它将添加到Translog并写入内存缓冲区。 下一次刷新索引时(默认情况下每秒进行一次),刷新过程将根据内存缓冲区的内容创建一个新的内存段,以便现在可以搜索文档。 然后它将清空内存缓冲区。 随着时间的流逝,会创建一堆分段。 随后,分段会在后台随时间合并在一起,以确保有效利用资源(每个段都使用文件句柄,内存和CPU)。 索引刷新是一项昂贵的操作,这就是为什么要定期进行刷新(默认设置),而不是在每次索引操作之后进行刷新。 如果您打算索引很多文档,而又不需要立即获取新信息以进行搜索,则可以通过减少刷新频率直到索引完成,或者甚至通过禁用索引来优化索引性能而不是搜索性能。如下图所示
Index Flush
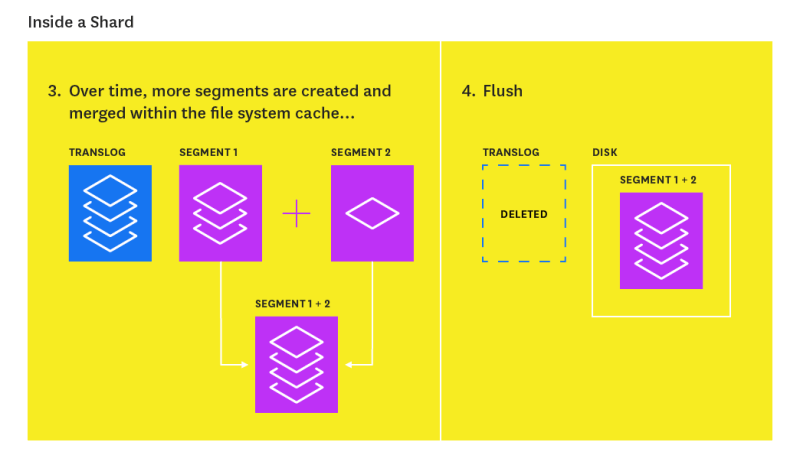
在上面的索引刷新过程中创建的内存中段不持久且不安全。 如果由于任何原因该节点关闭,它们将消失。 由于存在Translog,因此仍可以通过重播来恢复更改。 该日志每5秒或在每次成功索引,删除,更新或批量请求(以先到者为准)后,都会提交到磁盘。 但是,Translog有其自身的大小限制。 因此,每隔30分钟,或者每当事务日志达到最大大小(默认情况下为512MB)时,就会触发刷新。 在刷新期间,将刷新内存缓冲区中的所有文档(存储在新段中),所有内存段都将提交到磁盘,并清除Translog。
删除/更新数据
如果是删除操作,commit 的时候会生成一个 .del 文件,里面将某个 doc 标识为 deleted 状态,那么搜索的时候根据 .del 文件就知道这个 doc 是否被删除了。
如果是更新操作,就是将原来的 doc 标识为 deleted 状态,然后新写入一条数据。
Elasticsearch分布式架构的更多相关文章
- 【分布式搜索引擎】Elasticsearch分布式架构原理
一.相关概念介绍 1)集群(cluster) 一个集群(cluster)由一个或多个节点组成. 这些节点具有相同的cluster.name,它们协同工作,分享数据和负载.当加入新的节点或者删除一个节点 ...
- Elasticsearch基础分布式架构
写在前面的话:读书破万卷,编码如有神-------------------------------------------------------------------- 参考内容: <Ela ...
- Elasticsearch系列---分布式架构机制讲解
概要 本篇主要介绍Elasticsearch的数据索引时的分片机制,集群发现机制,primary shard与replica shard是如何分工合作的,如何对集群扩容,以及集群的容错机制. 分片机制 ...
- Elasticsearch由浅入深(二)ES基础分布式架构、横向扩容、容错机制
Elasticsearch的基础分布式架构 Elasticsearch对复杂分布式机制的透明隐藏特性 Elasticsearch是一套分布式系统,分布式是为了应对大数据量. Elasticsearch ...
- 分布式搜索引擎Elasticsearch的架构分析
一.写在前面 ES(Elasticsearch下文统一称为ES)越来越多的企业在业务场景是使用ES存储自己的非结构化数据,例如电商业务实现商品站内搜索,数据指标分析,日志分析等,ES作为传统关系型数据 ...
- Elasticsearch学习笔记(四)ElasticSearch分布式机制
一.Elasticsearch对复杂分布式机制透明的隐藏特性 1.分片机制: (1)index包含多个shard,每个shard都是一个最小工作单元,承载部分数据,lucene实例,完整的建立索引和处 ...
- Elasticsearch分布式机制和document分析
1. Elasticsearch对复杂分布式机制的透明隐藏特性 1.1)分片机制 1.2)集群发现机制 1.3)shard负载均衡 1.4)shard副本,请求路由,集群扩容,shard重分配 2. ...
- 搭建ELK日志分析平台(上)—— ELK介绍及搭建 Elasticsearch 分布式集群
笔记内容:搭建ELK日志分析平台(上)-- ELK介绍及搭建 Elasticsearch 分布式集群笔记日期:2018-03-02 27.1 ELK介绍 27.2 ELK安装准备工作 27.3 安装e ...
- Zookeeper在分布式架构中的应用
Zookeeper 是一个高性能.高可靠的分布式协调系统,是 Google Chubby 的一个开源实现.Zookeeper 能够为分布式应用提供一致性服务,提供的功能包括:配置维护.域名服务.分布式 ...
随机推荐
- C++ 对TXT 的串并行读写
任务说明:有36篇文档,现在要读入,并统计词频,字典长度25,希望能够比较串并行读写操作的时间差距. 串行读入并统计词频 // LoadDocsInUbuntu.cpp // #include < ...
- Linux(Centos)安装Java JDK及卸载
步骤一.下载安装包 a. 因为Java JDK区分32位和64位,所以安装之前需先判断一下我们操作系统为多少位·,命令如下: uname -a 解释:如果有x86_64就是64位的,没有就是32位 ...
- 下载STRING数据库检索互作关系结果为空,但是在STRING网站却能检索出互作关系,为什么呢???关键词用的是蛋白ID(ENSP开头)
首先介绍下两种方法: 一.本地分析 1.在STRING数据库下载人的互作文件,如下图,第一个文件 https://string-db.org/cgi/download.pl?sessionId=HGr ...
- 1233: 输出杨辉三角前n行
#include <stdio.h> int main() { int n,i,j,ch[15][15],v,k; char *nl = ""; while(scanf ...
- convertto-securestring结果 使用python解密
根据微软帮助文档,convertto-securestring有两种加密模式.如果在指定密码的情况下,则使用aes加密,否则使用windows dpapi加密.而且aes加密也没有指明iv值与加密模式 ...
- css的选择器及它的种类特性?
今天主要说的是选择器的基础, 首先看,选择器的优先级:!important > 行间样式 > id选择器 > class 选择器 == 属性选择器 > 标签选择器 > 通 ...
- ELK同步kafka带有key的Message
需求 kafka中的message带有key,带有相同key值的message后入kafka的意味着更新message,message值为null则意味着删除message. 用logstash来同步 ...
- HDU3836 Equivalent Sets (Tarjan缩点+贪心)
题意: 给你一张有向图,问你最少加多少条边这张图强连通 思路: 缩点之后,如果不为1个点,答案为出度为0与入度为0的点的数量的最大值 代码: #include<iostream> #inc ...
- codeforces 922 B. Magic Forest(枚举、位运算(异或))
题目链接:点击打开链接 Imp is in a magic forest, where xorangles grow (wut?) A xorangle of order n is such a no ...
- HDU6395 Sequence(矩阵快速幂+数论分块)
题意: F(1)=A,F(2)=B,F(n)=C*F(n-2)+D*F(n-1)+P/n 给定ABCDPn,求F(n) mod 1e9+7 思路: P/n在一段n里是不变的,可以数论分块,再在每一段里 ...