Python爬虫-01:爬虫的概念及分类
# 1. 为什么要爬虫?
“大数据时代”,数据获取的方式:
- 大型企业公司有海量用户,需要收集数据来提升产品体验
【百度指数(搜索),阿里指数(网购),腾讯数据(社交)】 - 数据管理咨询公司: 通过数据团队专门提供大量数据,通过市场调研,问卷调查等
- 政府/机构提供的公开数据
- 中华人民共和国统计局
- World bank
- Nasdaq
- 第三方数据平台购买数据
- 数据堂
- 贵阳大数据交易平台
- 爬虫数据
2. 什么是爬虫?
抓取网页数据的程序
3. 爬虫如何抓取网页数据?
首先需要了解网页的三大特征:
- 每个网页都有自己的
URL(统一资源定位符)来定位 - 网页都使用
HTML(超文本标记语言)来描述页面信息 - 网页都使用
HTTP/HTTPS(超文本传输协议)来传输HTML数据
爬虫的设计思路:
- 首先确定需要爬取的网
URL地址 - 通过
HTTP/HTTPS协议来获取对应的HTML页面 - 提取
HTML页面内有用的数据:
a. 如果是需要的数据--保存
b. 如果有其他URL,继续执行第二步
# 4. Python爬虫的优势?
| 语言 | 优点 | 缺点 |
|---|---|---|
| PHP | 世界上最好的语言 | 对多线程,异步支持不好,并发处理不够 |
| Java | 网络爬虫生态圈完善 | Java语言本身笨重,代码量很大,数据重构成本高 |
| C/C++ | 运行效率和性能几乎最强 | 学习成本很高 |
| python | 语法优美,代码简洁,开发效率高,模块多 |
5. 学习路线
- 抓取
HTML页面:
- HTTP请求的处理:
urllib, urlib2, requests - 处理器的请求可以模拟浏览器发送请求,获取服务器响应的文件
- 解析服务器相应的内容:
re, xpath, BeautifulSoup(bs4), jsonpath, pyquery等- 使用某种描述性语言来给我们需要提取的数据定义一个匹配规则,符合这个规则的数据就会被匹配
- 采集动态
HTML,验证码的处理
- 通用动态页面采集:
Selenium + PhantomJS:模拟真实浏览器加载JS - 验证码处理:
Tesseract机器学习库,机器图像识别系统
Scrapy框架:
- 高定制性,高性能(异步网络框架
twisted)->数据下载快 - 提供了数据存储,数据下载,提取规则等组件
- 分布式策略:
scrapy redis:在scarpy基础上添加了以redis数据库为核心的一套组件,主要在redis做请求指纹去重、请求分配、数据临时存储
- 爬虫、反爬虫、反反爬虫之间的斗争:
User-Agent,代理,验证码,动态数据加载,加密数据
6. 爬虫的分类
6.1 通用爬虫:
1.定义: 搜索引擎用的爬虫系统
2.目标: 把所有互联网的网页爬取下来,放到本地服务器形成备份,在对这些网页做相关处理(提取关键字,去除广告),最后提供一个用户可以访问的借口
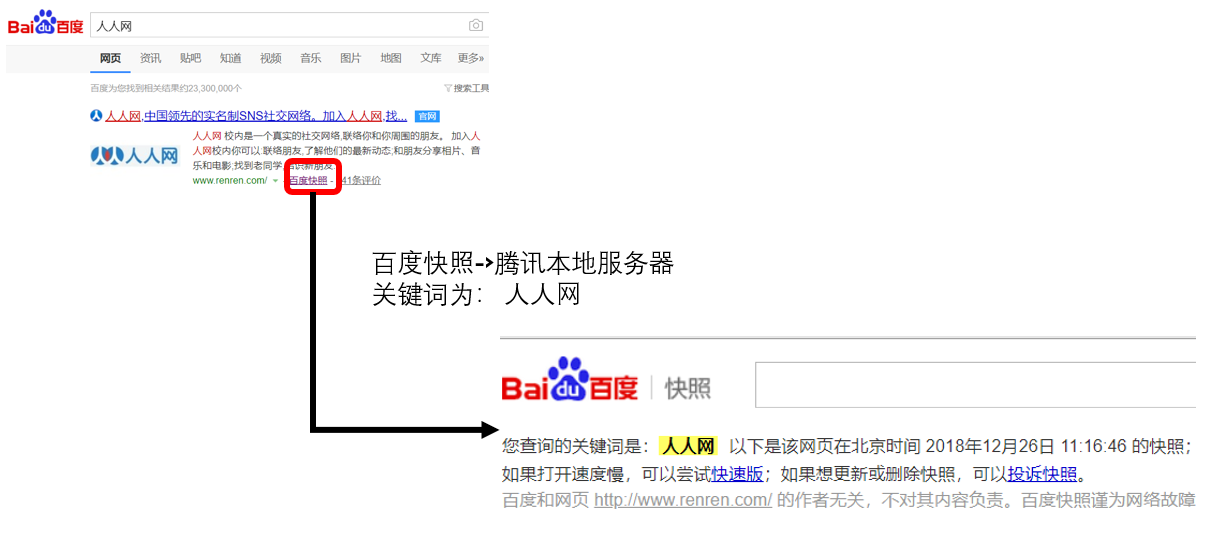
3.抓取流程:
a) 首先选取一部分已有的URL, 把这些URL放到带爬取队列中
b) 从队列中取出来URL,然后解析NDS得到主机IP,然后去这个IP对应的服务器里下载HTML页面,保存到搜索引擎的本地服务器里,之后把爬过的URL放入已爬取队列
c) 分析网页内容,找出网页里其他的URL连接,继续执行第二步,直到爬取结束
4.搜索引擎如何获取一个新网站的URL:
- 主动向搜索引擎提交网址: https://ziyuan.baidu.com/linksubmit/index
- 在其他网站设置网站的外链: 其他网站上面的友情链接
- 搜索引擎会和DNS服务商进行合作,可以快速收录新网站
5.通用爬虫注意事项
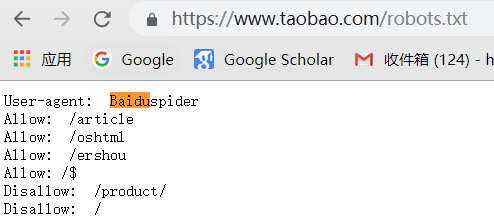
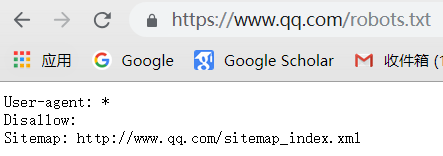
通用爬虫并不是万物皆可以爬,它必须遵守规则:
Robots协议:协议会指明通用爬虫可以爬取网页的权限
我们可以访问不同网页的Robots权限
6.通用爬虫通用流程:

7.通用爬虫缺点
- 只能提供和文本相关的内容(HTML,WORD,PDF)等,不能提供多媒体文件(msic,picture, video)及其他二进制文件
- 提供结果千篇一律,不能针对不同背景领域的人听不同的搜索结果
- 不能理解人类语义的检索
- 聚焦爬虫的优势所在
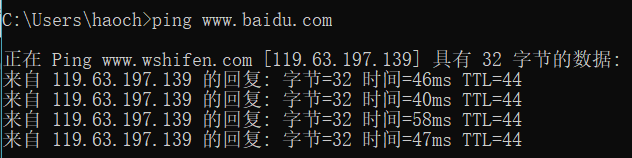
DNS 域名解析成IP: 通过在命令框中输入ping www.baidu.com,得到服务器的IP
6.2 聚焦爬虫:
爬虫程序员写的针对某种内容的爬虫-> 面向主题爬虫,面向需要爬虫
Python爬虫-01:爬虫的概念及分类的更多相关文章
- Python 开发轻量级爬虫01
Python 开发轻量级爬虫 (imooc总结01--课程目标) 课程目标:掌握开发轻量级爬虫 为什么说是轻量级的呢?因为一个复杂的爬虫需要考虑的问题场景非常多,比如有些网页需要用户登录了以后才能够访 ...
- [Python]新手写爬虫全过程(转)
今天早上起来,第一件事情就是理一理今天该做的事情,瞬间get到任务,写一个只用python字符串内建函数的爬虫,定义为v1.0,开发中的版本号定义为v0.x.数据存放?这个是一个练手的玩具,就写在tx ...
- Python爬虫从入门到进阶(1)之Python概述及爬虫入门
一.Python 概述 1.计算机语言概述 (1).语言:交流的工具,沟通的媒介 (2).计算机语言:人跟计算机交流的工具 (3).Python是计算机语言的一种 2.Python编程语言 代码:人类 ...
- 初探爬虫 ——《python 3 网络爬虫开发实践》读书笔记
零.背景 之前在 node.js 下写过一些爬虫,去做自己的私人网站和工具,但一直没有稍微深入的了解,借着此次公司的新项目,体系的学习下. 本文内容主要侧重介绍爬虫的概念.玩法.策略.不同工具的列举和 ...
- Python开发简单爬虫 - 慕课网
课程链接:Python开发简单爬虫 环境搭建: Eclipse+PyDev配置搭建Python开发环境 Python入门基础教程 用Eclipse编写Python程序 课程目录 第1章 课程介绍 ...
- python 3.x 爬虫基础---Urllib详解
python 3.x 爬虫基础 python 3.x 爬虫基础---http headers详解 python 3.x 爬虫基础---Urllib详解 前言 爬虫也了解了一段时间了希望在半个月的时间内 ...
- python应用之爬虫实战1 爬虫基本原理
知识内容: 1.爬虫是什么 2.爬虫的基本流程 3.request和response 4.python爬虫工具 参考:http://www.cnblogs.com/linhaifeng/article ...
- Python学习网络爬虫--转
原文地址:https://github.com/lining0806/PythonSpiderNotes Python学习网络爬虫主要分3个大的版块:抓取,分析,存储 另外,比较常用的爬虫框架Scra ...
- Python 3网络爬虫开发实战书籍
Python 3网络爬虫开发实战书籍,教你学会如何用Python 3开发爬虫 本书介绍了如何利用Python 3开发网络爬虫,书中首先介绍了环境配置和基础知识,然后讨论了urllib.reques ...
随机推荐
- 如何用golang获取linux上文件的访问/创建/修改时间
在linux上想获取文件的元信息,我们需要使用系统调用lstat或者stat. 在golang的os包里已经把stat封装成了Stat函数,使用它比使用syscall要方便不少. 这是os.Stat的 ...
- 杭电ACM2000--ASCII码排序
ASCII码排序 Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Total Su ...
- [angularjs] 前端路由实现单页跳转
代码: <div ng-app="Home"> <div ui-view></div> <div ng-controller=" ...
- 【Spring】22、Spring缓存注解@Cache使用
缓存注解有以下三个: @Cacheable @CacheEvict @CachePut @Cacheable(value=”accountCache”),这个注释的意思是,当调用这个 ...
- Reinforcement Learning: An Introduction读书笔记(1)--Introduction
> 目 录 < learning & intelligence 的基本思想 RL的定义.特点.四要素 与其他learning methods.evolutionary m ...
- 数据库索引(Oracle和Mysql)学习总结
旭日Follow_24 的CSDN 博客 ,全文地址请点击: https://mp.csdn.net/postedit/80910082 索引概念: 索引是关系数据库中用于存放每一条记录的一种 ...
- angularjs+webapi2 跨域Basic 认证授权(一)
如今的app,利用各种前端框架结合html5的混合开发模式已然盛极一时.其中ionic+angularjs更是如日中天.这种模式利用angularjs $http 请求数据api 以达到前后端分离深得 ...
- apache配置-html碎片shtml格式
修改SSI 文件 conf–httpd.conf <Directory "D:/Android/Apache2.2/htdocs"> //修改文件目录 # # Pos ...
- MongoDB 3.0 WT引擎参考配置文件
单实例: systemLog: destination: file ###日志存储位置 path: /data/mongodb/log/mongod.log logAppend: true stora ...
- Python date,datetime,time等相关操作总结
date,datetime,time等相关操作总结 by:授客 QQ:1033553122 测试环境: Python版本:Python 3.3.2 代码实践: __author__ = '授客' ...