Python的list循环遍历中,删除数据的正确方法
在遍历list,删除符合条件的数据时,总是报异常,代码如下:
num_list = [1, 2, 3, 4, 5]
print(num_list) for i in range(len(num_list)):
if num_list[i] == 2:
num_list.pop(i)
else:
print(num_list[i]) print(num_list)
会报异常:IndexError: list index out of range
原因是在删除list中的元素后,list的实际长度变小了,但是循环次数没有减少,依然按照原来list的长度进行遍历,所以会造成索引溢出。
修改代码如下:
num_list = [1, 2, 3, 4, 5]
print(num_list) for i in range(len(num_list)):
if i >= len(num_list):
break if num_list[i] == 2:
num_list.pop(i)
else:
print(num_list[i]) print(num_list)
这回不会报异常了,但是打印结果如下:
[1, 2, 3, 4, 5]
1
4
5
[1, 3, 4, 5]
虽然最后,list中的元素[2]确实被删除掉了,但是,在循环中的打印结果不对,少打印了[3]。
思考了下,知道了原因,当符合条件,删除元素[2]之后,后面的元素全部往前移,于是[3, 4, 5]向前移动,那么元素[3]的索引,就变成了之前[2]的索引(现在[3]的下标索引变为1了),后面的元素以此类推。可是,下一次for循环的时候,是从下标索引2开始的,于是,取出了元素[4],就把[3]漏掉了。
再次修改代码,结果一样,丝毫没有改观:
num_list = [1, 2, 3, 4, 5]
print(num_list) for item in num_list:
if item == 2:
num_list.remove(item)
else:
print(item) print(num_list)
找出问题的根本原因所在,想要找到正确的方法,也并不难,再次修改代码:
num_list = [1, 2, 3, 4, 5]
print(num_list) i = 0
while i < len(num_list):
if num_list[i] == 2:
num_list.pop(i)
i -= 1
else:
print(num_list[i]) i += 1 print(num_list)
执行结果,完全正确:
[1, 2, 3, 4, 5]
1
3
4
5
[1, 3, 4, 5]
我的做法是,既然用for循环不行,那就换个思路,用while循环来搞定。每次while循环的时候,都会去检查list的长度(i < len(num_list)),这样,就避免了索引溢出,然后,在符合条件,删除元素[2]之后,
手动把当前下标索引-1,以使下一次循环的时候,通过-1后的下标索引取出来的元素是[3],而不是略过[3]。
当然,这还不是最优解,所以,我搜索到了通用的解决方案:
1、倒序循环遍历;
2、遍历拷贝的list,操作原始的list。
1、倒序循环:
num_list = [1, 2, 3, 4, 5]
print(num_list) for i in range(len(num_list)-1, -1, -1):
if num_list[i] == 2:
num_list.pop(i)
else:
print(num_list[i]) print(num_list)
执行结果完全正确
解释正序循环时删除就有问题,而倒序循环时删除就ok
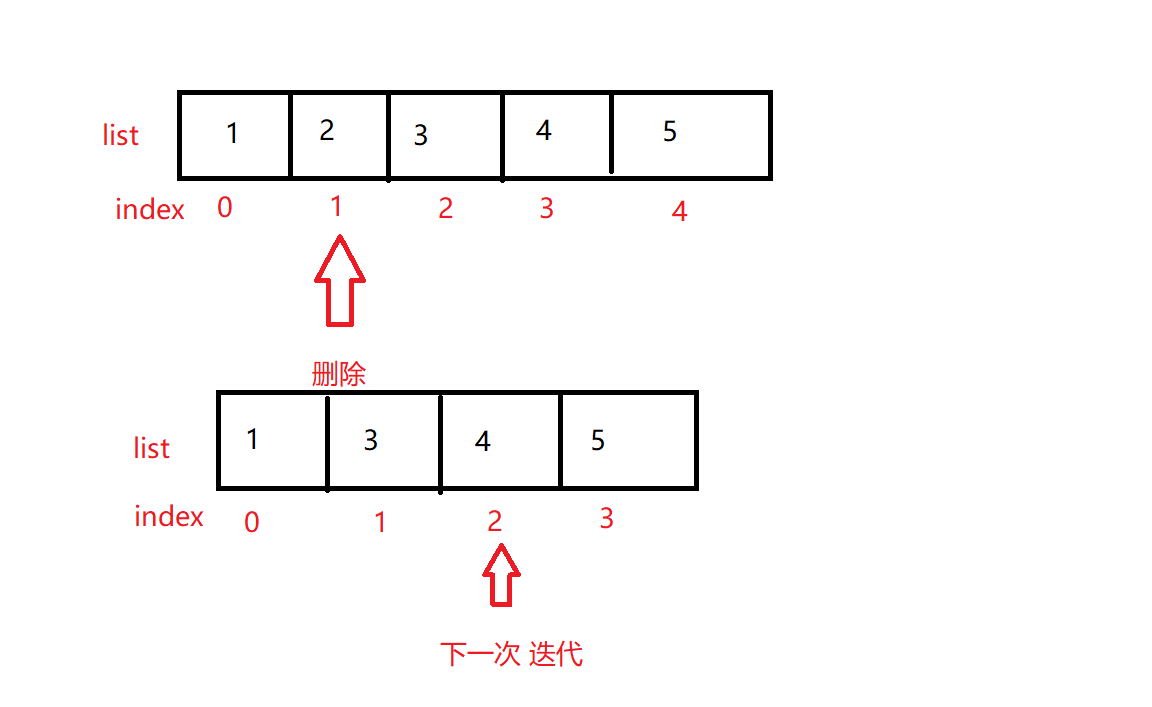
删除元素[2]之后,下一次循环的下标索引为2,但此时,里面存放的是[4],于是就把[3]给漏了。
2)倒序循环时删除

删除元素[2]后,[3, 4, 5]往前挤,但是没关系,因为下一次循环的下标索引为0,里面存放的是[1],所以正是我们所期望的正确的元素值。
2、遍历拷贝的list,操作原始的list
num_list = [1, 2, 3, 4, 5]
print(num_list) for item in num_list[:]:
if item == 2:
num_list.remove(item)
else:
print(item) print(num_list)
原始的list是num_list,那么其实,num_list[:]是对原始的num_list的一个拷贝,是一个新的list,所以,我们遍历新的list,而删除原始的list中的元素,则既不会引起索引溢出,最后又能够得到想要的最终结果。此方法的缺点可能是,对于过大的list,拷贝后可能很占内存。那么对于这种情况,可以用倒序遍历的方法来实现
Python的list循环遍历中,删除数据的正确方法的更多相关文章
- Java中ArrayList循环遍历并删除元素的陷阱
ava中的ArrayList循环遍历并且删除元素时经常不小心掉坑里,昨天又碰到了,感觉有必要单独写篇文章记一下. 先写个测试代码: import java.util.ArrayList; public ...
- 【转】ArrayList循环遍历并删除元素的常见陷阱
转自:https://my.oschina.net/u/2249714/blog/612753?p=1 在工作和学习中,经常碰到删除ArrayList里面的某个元素,看似一个很简单的问题,却很容易出b ...
- ArrayList循环遍历并删除元素的常见陷阱
在工作和学习中,经常碰到删除ArrayList里面的某个元素,看似一个很简单的问题,却很容易出bug.不妨把这个问题当做一道面试题目,我想一定能难道不少的人.今天就给大家说一下在ArrayList循环 ...
- 用python批量向数据库(MySQL)中导入数据
用python批量向数据库(MySQL)中导入数据 现有数十万条数据,如下的经过打乱处理过的数据进行导入 数据库内部的表格的数据格式如下与下面的表格结构相同 Current database: pyt ...
- 关于js中循环遍历中顺序执行ajax的问题(vue)
js里的循环,每次都是自顾自的走,它不等ajax执行好走完到success代码,就继续循环下一条数据了,这样数据就全乱了. 后来,想到试试ajax里async这个属性,async默认是true,即为异 ...
- 遍历List过程中删除元素的正确做法(转)
遍历List过程中删除元素的正确做法 public class ListRemoveTest { 3 public static void main(String[] args) { 4 ...
- NHibernate 中删除数据的几种方法
今天下午有人在QQ群上问在NHibernate上如何根据条件删除多条数据,于是我自己就写了些测试代码,并总结了一下NHibernate中删除数据的方式,做个备忘.不过不能保证囊括所有的方式,如果还有别 ...
- ODI中删除数据的处理
ODI中删除数据的处理 一.前提知识:数据从源数据库向数据仓库抽取时,一般采用以下几种方式: 全抽取模式如果表的数据量较小,则可以采取全表抽取方式,以TRUNCATE/INSERT方式进行数据抽取. ...
- 总结NHibernate 中删除数据的几种方法
今天下午有人在QQ群上问在NHibernate上如何根据条件删除多条数据,于是我自己就写了些测试代码,并总结了一下NHibernate中删除数据的方式,做个备忘.不过不能保证囊括所有的方式,如果还有别 ...
随机推荐
- repo
repo init -b remoteBranchName repo sync repo start localBranchName --all 整体切分支 if error is tagger cl ...
- 3/1 AT指令集
一.背景 由于机器与传输时的信号类型不通,机器处理的是数字信号,而传输时是模拟信号,故,要实现这两者间的交互,就需要一个介质,之前是靠硬件,靠人工,硬件使用modem(猫): 现在通过一种命令来实现自 ...
- springboot日志logback配置
<?xml version="1.0" encoding="UTF-8"?> <!-- scan:当此属性设置为true时,配置文件如果发生改 ...
- StringUtils.isEmpty StringUtils.isBlank
两个方法都是判断字符是否为空的.前者是要求没有任何字符,即str==null 或 str.length()==0:后者要求是空白字符,即无意义字符.其实isBlank判断的空字符是包括了isEmpty ...
- HC-05蓝牙模块配对步骤
参考:https://blog.csdn.net/m0_37182543/article/details/76383247
- Nancy.Net之旅-探索模块
探索Nancy模块 模块是任何Nancy应用程序中的主角,因为它是您定义应用程序行为的地方,所以无法避免使用它. 事实上,在任何的Nancy应用程序中,声明模块是最基本的要求. 通过继承NancyMo ...
- mysql 创建备份表
mysql 中对已有表进行备份用到的语句 CREATE TABLE table_name_1 SELECT * FROM table_name_2; 这个语句是创建表1并且复制表2的结构和数据到表1 ...
- java Graphics2D drawString()内容换行问题
//字符串总宽度 private int getStringLength(Graphics g,String str) { char[] strcha=str.toCharArray(); int s ...
- python测试开发django-1.开始hello world!
前言 当你想走上测试开发之路,用python开发出一个web页面的时候,需要找一个支持python语言的web框架.django框架有丰富的文档和学习资料,也是非常成熟的web开发框架,想学pytho ...
- nginx多域名、多证书
环境: 一台nginx服务器 192.168.10.251 两台windowsserver2012 IIS服务器 (192.168.10.252.192.168.10.253) 从阿里云上下载ssl证 ...