Ajax爬虫必用到的字典转换器
1.使用情景
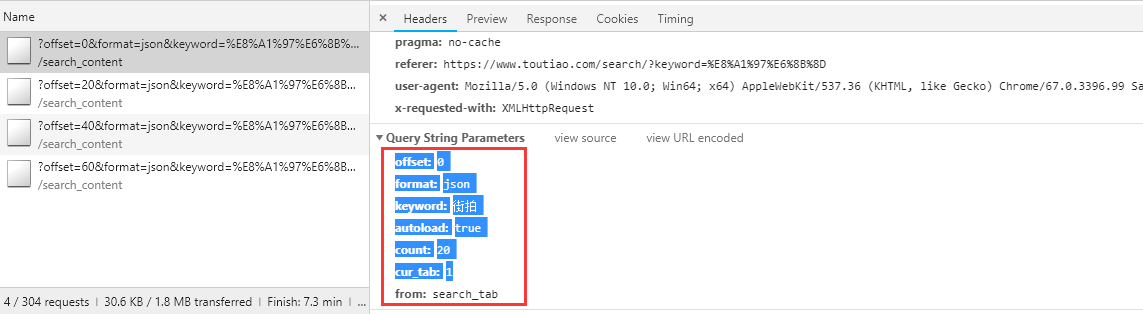
在我们Ajax爬虫时需要用到以下这样的数据的时候我们会一个一个地复制粘贴,这样会很麻烦
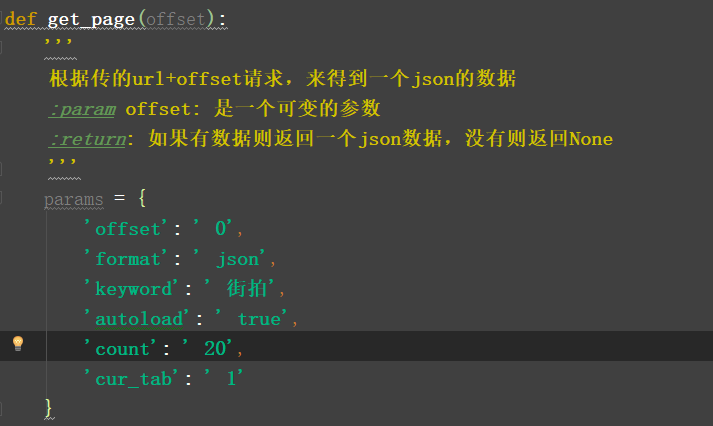
def dictionary_converter(key_value):
'''主要用于爬虫时复制浏览器中的数据时不方便而特此把文本转换为字典'''
# 例如,此此处需要注意复制来的数据一定要紧贴在'''之后
'''offset: 0
format: json
keyword: 街拍
autoload: true
count: 20
cur_tab: 1'''
# 转换后的格式为
''''{'offset': ' 0', 'format': ' json', 'keyword': ' 街拍', 'autoload': ' true', 'count': ' 20', 'cur_tab': ' 1'}
'''
# 这样使用起来比较方便
# 1.先把数据进行按换行切分
key_value_split = key_value.split('\n') # print(key_value_split)
# 2.初始化一个字典
d = dict()
# 3.循环取出列表中的键值对行如这样一个['key:value']
for temp in key_value_split:
# 4.再把列表中的键值对来用:分割成一个键值对的列表行如[key,value]
result = temp.split(':')
# 5.把每一个键值对添加到字典里面
d[result[0]] = result[1]
# 打印出需要的数据,方便进行复制
print(d) def main():
'''主程序入口'''
key_value_str = '''offset: 0
format: json
keyword: 街拍
autoload: true
count: 20
cur_tab: 1'''
dictionary_converter(key_value_str) if __name__ == '__main__':
main()
运行结果:

解决方法:这个只是我个人写的,提供给大家用,如有更好的方法也可以在下方评论
Ajax爬虫必用到的字典转换器的更多相关文章
- Python分布式爬虫必学框架Scrapy打造搜索引擎
Python分布式爬虫必学框架Scrapy打造搜索引擎 部分课程截图: 点击链接或搜索QQ号直接加群获取其它资料: 链接:https://pan.baidu.com/s/1-wHr4dTAxfd51M ...
- Python分布式爬虫必学框架Scrapy打造搜索引擎 ✌✌
Python分布式爬虫必学框架Scrapy打造搜索引擎 ✌✌ (一个人学习或许会很枯燥,但是寻找更多志同道合的朋友一起,学习将会变得更加有意义✌✌) 第1章 课程介绍 介绍课程目标.通过课程能学习到 ...
- Python分布式爬虫必学框架scrapy打造搜索引擎✍✍✍
Python分布式爬虫必学框架scrapy打造搜索引擎 整个课程都看完了,这个课程的分享可以往下看,下面有链接,之前做java开发也做了一些年头,也分享下自己看这个视频的感受,单论单个知识点课程本身 ...
- Python分布式爬虫必学框架Scrapy打造搜索引擎 学习教程
Python分布式爬虫打造搜索引擎Scrapy精讲—用Django实现搜索的自动补全功能 elasticsearch(搜索引擎)提供了自动补全接口 1.创建搜索自动补全字段suggest自动补全需要用 ...
- Python爬虫之自制英汉字典
最近在微信公众号中看到有人用Python做了一个爬虫,可以将输入的英语单词翻译成中文,或者把中文词语翻译成英语单词.笔者看到了,觉得还蛮有意思的,因此,决定自己也写一个玩玩~~ 首先我们的爬虫 ...
- 爬虫必知必会(7)_scrapy框架高级
一.请求传参 实现深度爬取:爬取多个层级对应的页面数据 使用场景:爬取的数据没有在同一张页面中 在手动请求的时候传递item:yield scrapy.Request(url,callback,met ...
- 爬虫必知必会(5)_scrapy框架_基础
一.移动端数据的爬取 基于某一款抓包工具,fiddler,青花瓷,miteproxy fillder进行一个基本的配置:tools->options->connection->all ...
- python 爬虫必知必会
#python爬虫 #新闻数据 #机器学习:股票数据获取及分析 #网络搜索引擎的一个部件 #Http协议 #正则表达式 #多线程,分布式 #http报文展示 #Http 应答报文介绍 #1.应答码 # ...
- 聚焦Python分布式爬虫必学框架Scrapy 打造搜索引擎视频教程
下载链接:https://www.yinxiangit.com/595.html 目录: 第1章 课程介绍介绍课程目标.通过课程能学习到的内容.和系统开发前需要具备的知识 第2章 windows下搭建 ...
随机推荐
- quartz定时任务的简单使用
开发环境: springmvc quartz-2.2.3在官网下载的. 步骤: 1.首先在web.xml中加入以下代码: <servlet> <servlet-name>Qua ...
- 20165221 JAVA第四周学习心得
教材内容总结 子类与继承 子类与父类 定义的标准格式为 class 子类名 extends 父类名 { ... } 如果一个类的声明中,没有使用extends关键字,则默认为Object类. 子类的继 ...
- WC2019 20天训练
Day -1 2019.1.2 初步计划: 0x60 图论 std 洛谷提高剩余练习 NOIP2018遗留题解 洛谷省选基础练习 数学: 1.数论 2.组合数学(练习:莫比乌斯反演) 3.概率(练习: ...
- 修改Spring Social默认提交地址
⒈ package cn.coreqi.social.config; import org.springframework.social.security.SocialAuthenticationFi ...
- 设计模式C++学习笔记之七(AbstractFactory抽象工厂模式)
抽象工厂,提供一个创建一系列相关或相互依赖对象的接口,而无需指定它们具体的类.对于工厂方法来说,抽象工厂可实现一系列产品的生产,抽象工厂更注重产品的组合. 看代码: 7.1.解释 main(),女 ...
- Apollo 代码的编译演示
Apollo 代码的编译演示 官方的文档 -- 运行线下演示 如果你没有车辆及车载硬件, Apollo还提供了一个计算机模拟环境,可用于演示和代码调试. 线下演示需要设置docker的release环 ...
- makefile 中添加依赖的库文件
当库文件中包含多个头文件和c源文件时,需要执行如下步骤: 1) makefile中添加 库文件依赖, -L 后面跟库文件的路径, -l(小写)后面跟库的名字 2)将库文件中的头文件添加到工程中去,使 ...
- 转载:UML学习(三)-----序列图(silent)
原文:http://www.cnblogs.com/silent2012/archive/2011/09/14/2172219.html UML的模型中可分为两种,动态模型和静态模型.用例图.类图和对 ...
- linux dynamic lib
// test1.h ; struct AA { int a,b: }; AA b(5,6); int ball(); // test1.cpp # include"test1.h" ...
- Android视频录制命令screenrecord
不管是教学,还是为了演示,如果能将Android手机(或平板)的屏幕录制成视频文件,那是一件非常酷的事(iOS8已经提供了这一功能,能通过OS X直接在Mac上录制iPad.iPhone的屏幕,win ...